Capítulo 5 Importação e exportação de dados
5.1 Introdução
A importação/exportação de dados era algo que em poucas linhas conseguíamos explicar sobre o ambiente R , no sentido de análise de dados. Entretanto, observando o terceiro princípio do R, afirmado por Chambers (2016): “Interfaces para outros programas são parte do R”. Hoje é uma realidade a interação que o ambiente R tem com outras interfaces (programas, linguagens, etc.). A facilidade em utilizar outras linguagens dentro do ambiente R torna assim mais complexo a importação/exportação de dados, uma vez que o objetivo do R , apesar do R Core Team ainda limitar a sua definição como o ambiente para a computação estatística, a ferramenta se tornou tão versátil, que hoje torna humilde essa definição. Para mais detalhes acesse o manual ??R Data Import/Export (R CORE TEAM, 2021a). Um outro fator e tema atual é a era dos grandes bancos de dados (Big Data), do qual se tem um grande conjunto de variáveis e necessitamos fazer a importação por APIs1 ,por exemplo, ou outras vias. Temas como esses, serão abordados em outros volumes da coleção Estudando o Ambiente R. Nesse momento, limitaremos esse assunto ao objetivo de termos um conjunto de dados em arquivos de texto (extensões do tipo .txt, .csv, .xls), formato binário (.xls ou .xlsx) ou digitados manualmente pelo teclado do computador. Assim, a primeira forma de como os dados estão dispostos, precisaremos importá-los e armazená-los em um quadro de dados (data frame), para que esteja disponível na área de trabalho (ambiente global) do R , e dessa forma, possamos utilizá-lo. Ao final do tratamento dos dados, podemos exportar essas informações para arquivos externos, e daí também, usaremos os arquivos de textos e o formato binário (.xls), mensionados anteriormente.
5.2 Preparação dos dados
A primeira coisa que devemos entender quando desejamos construir o arquivo de dados, é entender que sempre organizaremos as variáveis em colunas, com os seus valores em linhas, Figura ??fig:bdados). Sempre a primeira linha das colunas representarar o nome das variáveis. Esse é outro ponto importante, pois devemos ter a noção que alguma linguagem irá ler esse banco de dados. Assim, quanto mais caracteres diferentes do padrão ASCII, mais difícil será a leitura desses dados. Assim, sugerimos alguns padrões:
Evitem símbolos fora do padrão alfanumérico;
Evitem mistura de letras minúsculas com letras maiúsculas. Isso facilitará o acesso a essas variáveis. Contudo, lembremos do padrão de nomes sintéticos permissíveis observados na seção 3.3.2;
Lembremos que o banco de dados será utilizado para que um programa faça a sua leitura, portanto, deixemos a formatação da apresentação dos dados para arquivos específico. Sendo assim, evitem comentários nesses arquivos, ou qualquer outro tipo de informação que não seja o banco de dados;
Evitem palavras longas, por exemplo, segundavariavel (má escolha), segvar (boa escolha), seg_var (boa escolha);
Evitem palavras compostas com espaço entre elas. Para isso use o símbolo _, por exemplo, var 2 (má escolha), var2 (boa escolha), var_2 (boa escolha);
knitr::include_graphics("img/Modelo_Estrutural_Banco_Dados.png")
FIGURA 5.1: Modelo estrutural de um banco de dados.
5.3 Importando dados
A função primária responável pela importação de dados é a função scan(). Por exemplo, funções como read.table(), read.csv() e read.delim(), usam a função scan() em seu algoritmo. A primeira ideia sobre importação de dados pode ser inserindo-os pelo teclado no próprio ambiente R . Para isso, usaremos a função scan(), isto é,
> # Criando e inserido os elementos do objeto dados
> x <- scan()Após executado essa linha de comando, aparecerá no console 1: que significa, digitar o primeiro valor do objeto x, e depois clicar em ENTER. Depois 2:, que significa digitar o segundo valor, e clicar em ENTER. Depois de inserido todos os valores necessários, aperte a tecla ENTER duas vezes no console, para sair da função scan().
O mais tradicional é usar programa para criação de banco de dados e deixá-lo pronto para o R lê-lo. O tipo de arquivo de texto que melhor controla a separação de variáveis é com a extensão .csv, uma vez que separamos as variáveis por “;”, é o padrão. O arquivo de texto com extensão .txt, geralmente usa espaços. Isso acaba gerando problema de leitura no R , porque muitos usuários usam nomes de variáveis muito grandes, palavras compostas, de forma a desalinhar as colunas das variáveis. Daí, como a separação das variáveis é por meio de espaços, acaba gerando problema de leitura. Uma outra forma, é fazer importação de dados gerados pelo próprio R , extensão .RData.
Temos a opção de usar um editor de banco de dados para essas extensões por meio de programas como MS Excel, Libre Office, dentre outros. Estes exportam arquivos binários do tipo .xls, .xlsx, dentre outros. Uma sugestão para diminuir complicações, é exportar os bancos de dados para arquivos de texto sitados acima, que também é possível ser exportado por esses programas. Isso evita a necessidade de ser instalado mais pacotes e dor de cabeça. Porém, para quem ainda deseja enfrentar, sugerimos a leitura do pacote readr, como exemplo, porém existem diversos outros pacotes para este mesmo fim.
Uma vez que o banco de dados está pronto, a leitura destes pode ser feita por alguns caminhos. Mostraremos o mais trivial que é o botão Import Dataset, terceiro quadrante, aba Environment, na IDE do RStudio , como observado na Figura 5.2.
knitr::include_graphics("img/Importando_Dados_01.png")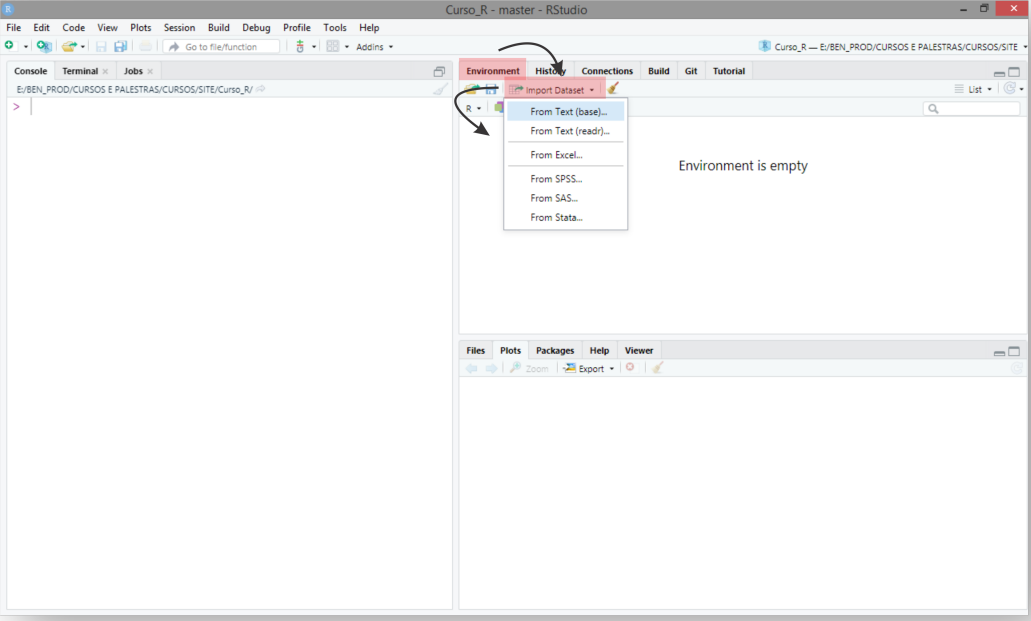
FIGURA 5.2: Usando o RStudio para importar dados
Posteriormente, indique o arquivo para leitura. Aparece algumas opções de tipo de arquivo. Em nosso caso, usaremos a opção From Text (base), que significa realizar a leitura para os tipos de arquivo .txt ou .csv. Daí os passos seguintes são:
Escolher o arquivo para leitura dos dados Figura 5.2;
Configurar a leitura do banco de dados. Uma prévia pode ser vista no quadro Data Frame. Se for visualizado, algum problema, isso significa que deve ser informado opções adicionais como separador de variáveis (Separator), símbolo para casas decimais (Decimal), dentre outras opções. Por fim, digitar o nome associado ao objeto (Name) que será criado do tipo quadro de dados (data frame), e clicar no botão Import Figura 5.3;
Uma vez inserido, o RStudio apresenta a linha de comando utilizada para importar os dados no console (2º quadrante), o conjunto de dados (1º quadrante), e a ligação entre o nome e o objeto no ambiente global (3º quadrante), Figura 5.4;
A outra forma é utilizar linhas de comando. Para isso utilizaremos a função read.table(). Antes de importarmos o banco de dados, algo interessante é inserir o arquivo de dados no diretório de trabalho no ambiente R . Para verificar o ambiente de trabalho use a função getwd(). Para alterar o local do ambiente de trabalho use setwd(). Se esse procedimento não for realizado, o usuário deve informar na função read.table(), o local exato do arquivo de texto.
Vamos usar como diretório o local C:. Lembre-se que no R , a barra deve ser invertida. Vamos inserir nesse diretório três arquivos alfafa.txt, datast1980.txt e producao.csv.
Os três conjuntos de dados são:
knitr::include_graphics("img/Importando_Dados_02.png")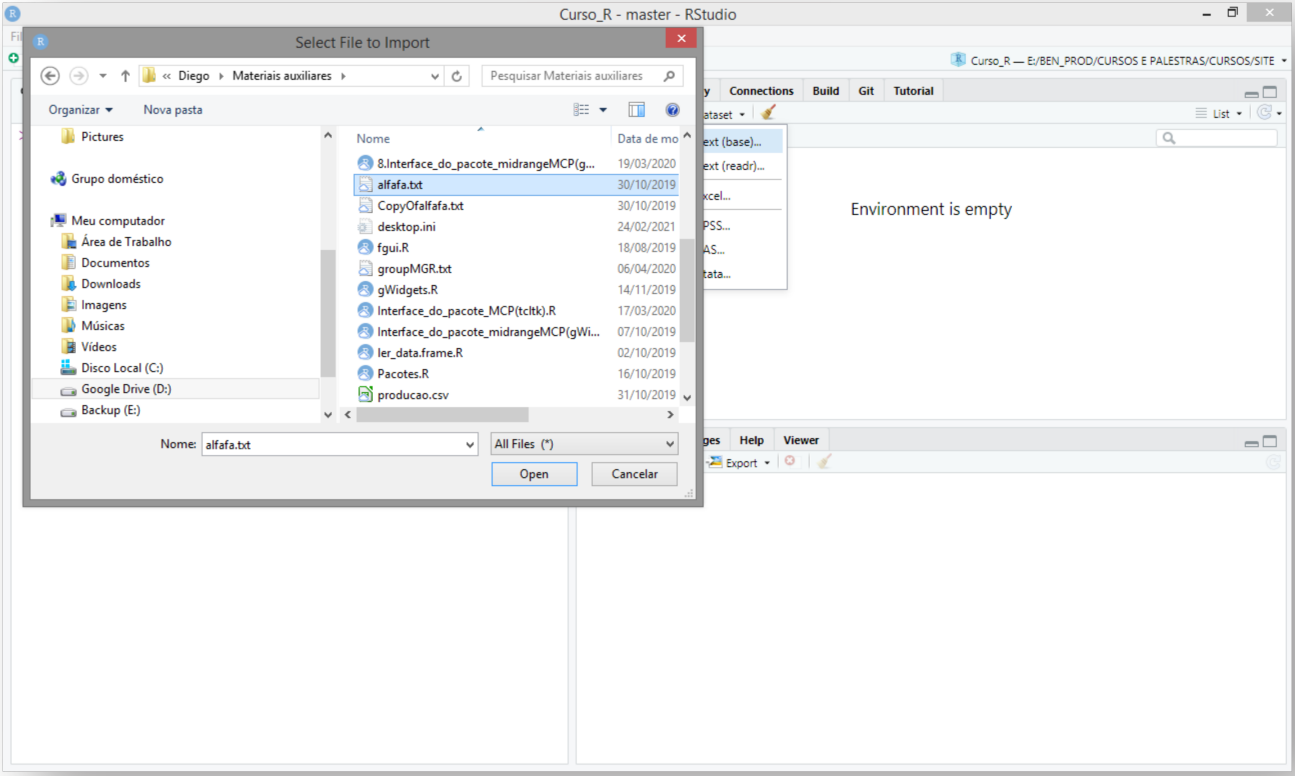
FIGURA 5.3: Usando o RStudio para importar dados
knitr::include_graphics("img/Importando_Dados_03.png")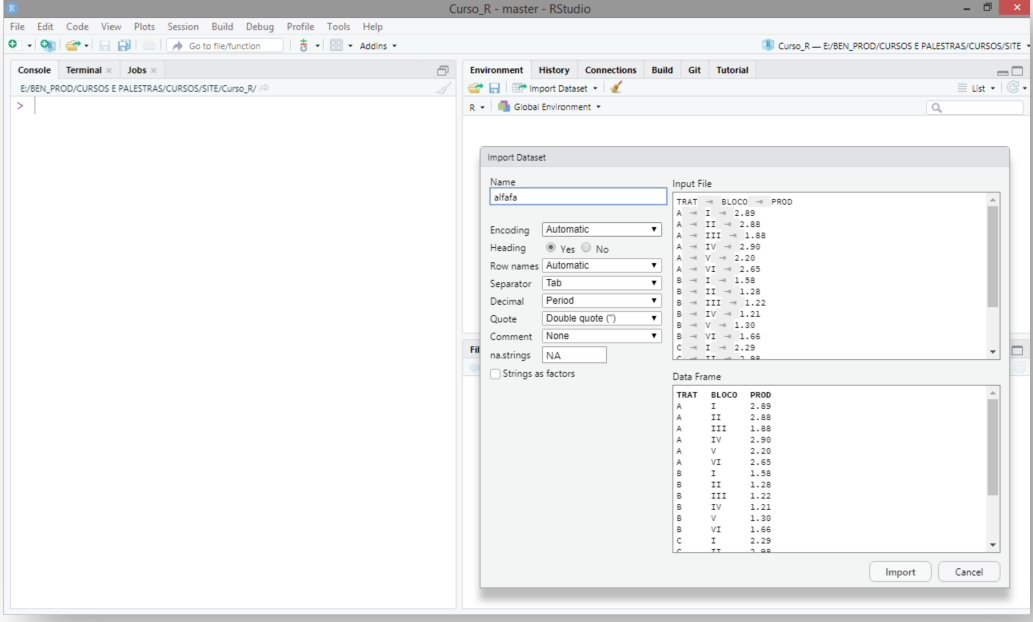
FIGURA 5.4: Usando o RStudio para importar dados
knitr::include_graphics("img/Importando_Dados_04.png")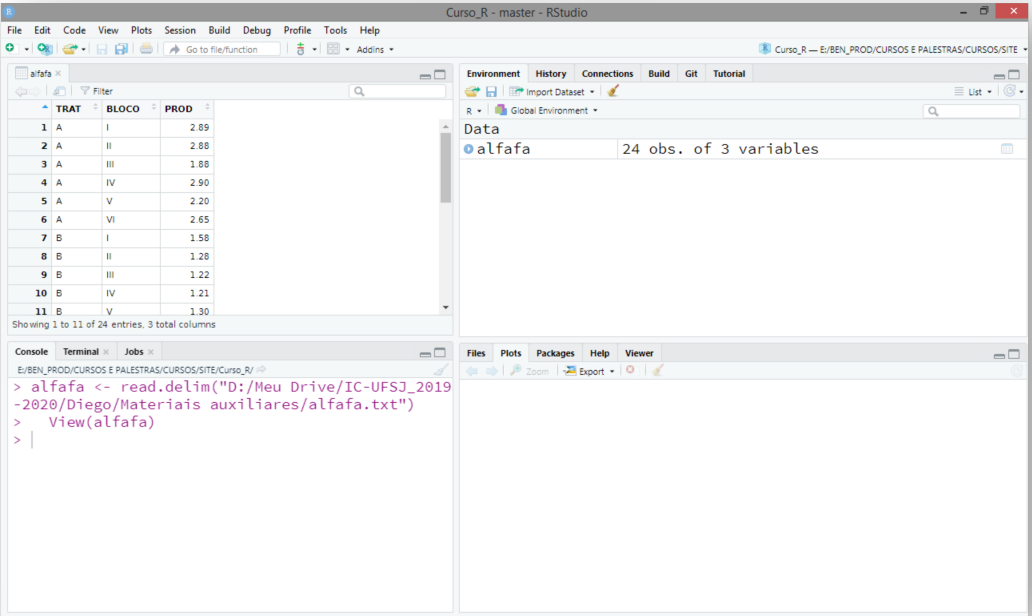
FIGURA 5.5: Usando o RStudio para importar dados
| TRAT | BLOCO | PROD |
|---|---|---|
| A | I | 2.89 |
| A | II | 2.88 |
| A | III | 1.88 |
| A | IV | 2.90 |
| A | V | 2.20 |
| A | VI | 2.65 |
| B | I | 1.58 |
| B | II | 1.28 |
| B | III | 1.22 |
| B | IV | 1.21 |
| B | V | 1.30 |
| B | VI | 1.66 |
| C | I | 2.29 |
| C | II | 2.98 |
| C | III | 1.55 |
| C | IV | 1.95 |
| C | V | 1.15 |
| C | VI | 1.12 |
| D | I | 2.56 |
| D | II | 2.00 |
| D | III | 1.82 |
| D | IV | 2.20 |
| D | V | 1.33 |
| D | VI | 1.00 |
| trt | y |
|---|---|
| 1 | 19,4 |
| 1 | 32,6 |
| 1 | 27,0 |
| 1 | 32,1 |
| 1 | 33,0 |
| 2 | 17,7 |
| 2 | 24,8 |
| 2 | 27,9 |
| 2 | 25,2 |
| 2 | 24,3 |
| 3 | 17,0 |
| 3 | 19,4 |
| 3 | 9,1 |
| 3 | 11,9 |
| 3 | 15,8 |
| 4 | 20,7 |
| 4 | 21,0 |
| 4 | 20,5 |
| 4 | 18,8 |
| 4 | 18,6 |
| 5 | 14,3 |
| 5 | 14,4 |
| 5 | 11,8 |
| 5 | 11,6 |
| 5 | 14,2 |
| 6 | 17,3 |
| 6 | 19,4 |
| 6 | 19,1 |
| 6 | 16,9 |
| 6 | 20,8 |
| X | y |
|---|---|
| 1 | 6.7 |
| 2 | 7.9 |
| 3 | 9.1 |
| 4 | 6.6 |
| 5 | 7.5 |
| 6 | 8.8 |
| 7 | 7.7 |
| 8 | 7.6 |
| 9 | 6.5 |
| 10 | 7.9 |
| 11 | 8.7 |
| 12 | 6.2 |
| 13 | 7.9 |
| 14 | 7.4 |
| 15 | 9.7 |
| 16 | 6.2 |
| 17 | 4.9 |
| 18 | 5.6 |
| 19 | 7 |
| 20 | 6 |
Vejamos as linhas de comando para importar os dados, Código R 5.1.
> # Diretorio
> getwd()
> # Mudadando para o diretorio de interesse
> setwd("C:/cursor")
> # Verificando os arquivos no diretorio de trabalho
> list.files()
> # Importando os dados apontando para o diretorio do arquivo
> dados1 <- read.table(file = "C:/cursor/alfafa.txt", header = TRUE)
> # Considerando que o arquivo esta no diretorio de
> # trabalho, isto eh, getwd()
> dados2 <- read.table("alfafa.txt", header = TRUE)
> # Importando os dados com decimais com ',' apontando para o diretorio do
> arquivo
> dados3 <- read.table(file = "C:/cursor/dadost1980.txt", header = TRUE, dec =
+ ",")
> # Considerando que o arquivo esta no diretorio de
> # trabalho, isto eh, getwd()
> dados4 <- read.table(file = "dadost1980.txt", header = TRUE, dec = ",")
> # Importando os dados com decimais ',', e separados por ';' apontando para o diretorio do arquivo
> dados5 <- read.table(file = "C:/cursor/producao.csv", header = TRUE, dec =
+ ",", sep = ";")
> # Considerando que o arquivo esta no diretorio de
> # trabalho, isto eh, getwd()
> dados6 <- read.table(file = "producao.csv", header = TRUE, dec = ",", sep =
+ ";")
> # Importando da internet
> dados7 <- read.table(file =
+ "https://raw.githubusercontent.com/bendeivide/book-eambr01/main/files/␣
+ alfafa.txt", header = TRUE)Na última linha de comando, mostramos que também é possível importar dados de arquivos de texto da internet, e claro considerando que o usuário está com acesso a internet no momento da importação. E um recurso interessante que pode ser feito, principalmente para este caso, é salvar o banco de dados em um arquivo de dados no ’.RData‘. Dessa forma, todos os dados, inclusive os importados da internet serão agora armazenados nesse tipo de arquivo, e não precisaremos, nesse caso, de acesso a internet. Para salvar, usamos a função save(). Para carregar os dados e armazenálo no ambiente global, usamos a função load(), Código R 5.2.
> # Diretorio
> getwd()
>
> # Verificando os arquivos do diretorio de trabalho
> list.files()
>
> # Importando os dados da internet
> dados7 <- read.table(file =
+ "https://raw.githubusercontent.com/bendeivide/book-eambr01/main/files/alfafa.txt", header = TRUE)
>
> # Salvando em '.RData'
> save(dados7, file = "alfafa.RData")
>
> # Carregando '.RData' para o ambiente global
> load("alfafa.RData")Percebemos que as extensões .txt e .csv são idênticos, exceto pela estrutura de como os dados estão dispostos. Para comprovar isso, o usuário manualmente poderá mudar a extensão de um arquivo do tipo .csv para um arquivo .txt e observar em um bloco de notas. Até agora, usamos as funções no R, em algumas situações, sem apresentar os argumentos dessas funções dentro dos parênteses. Isso porque quando inserimos os valores dos argumentos na posição correta destes, não precisaremos inserir o nome dos argumentos. Por exemplo, já usamos anteriormente a função mean() que calcula a média de um conjunto de valores, por exemplo, valores <- 1:10. Temos como primeiro argumento para essa função o x que representa um objeto R que recebe os valores para o cálculo. Assim, como sabemos que x é o primeiro argumento dessa função, podemos omitir o seu nome e calcular a média por mean(valores), que é o mesmo que mean(x = valores). Para mais detalhes, ?mean(), como também, para mais detalhes sobre a função read.table(), use ?read.table()