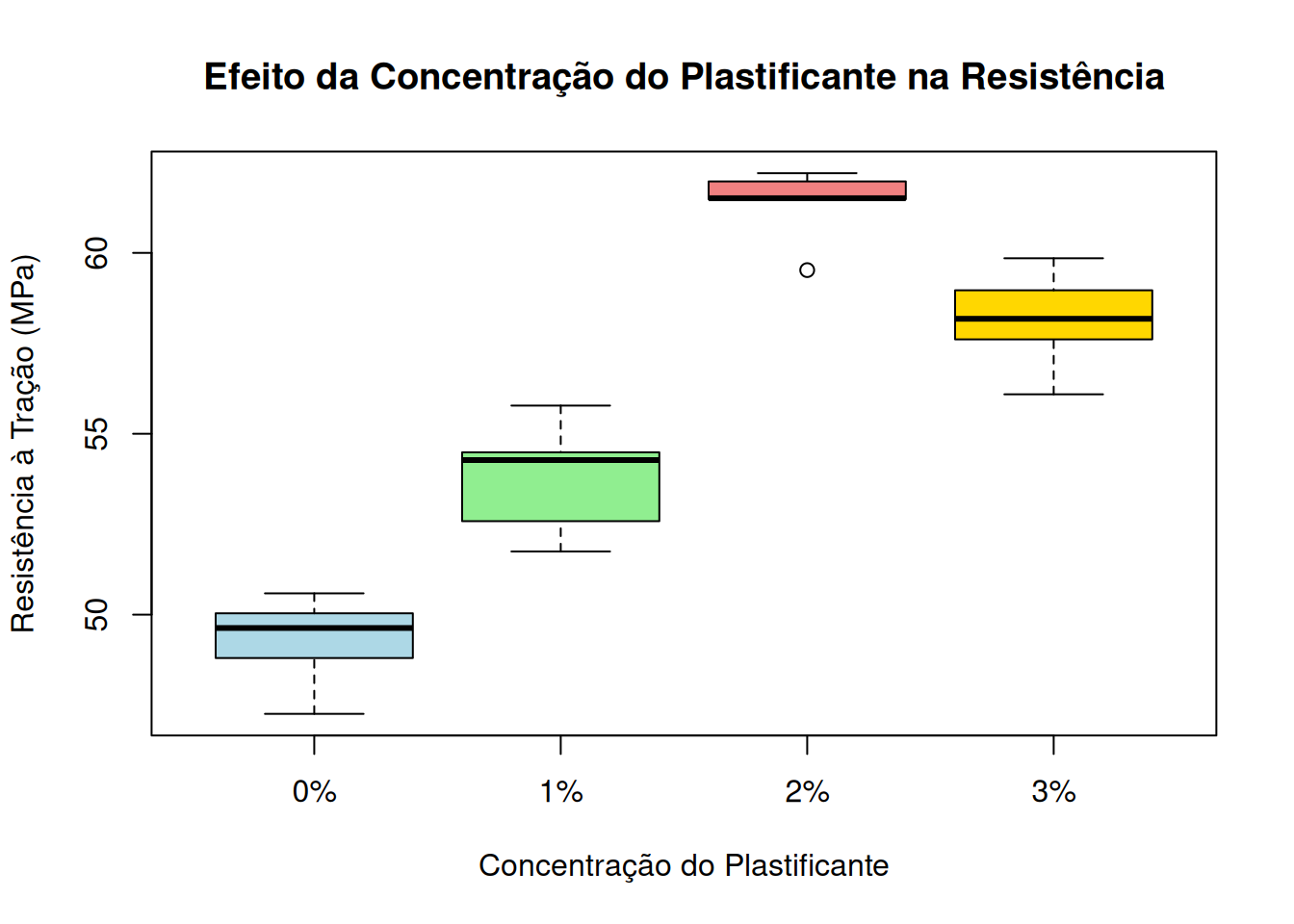
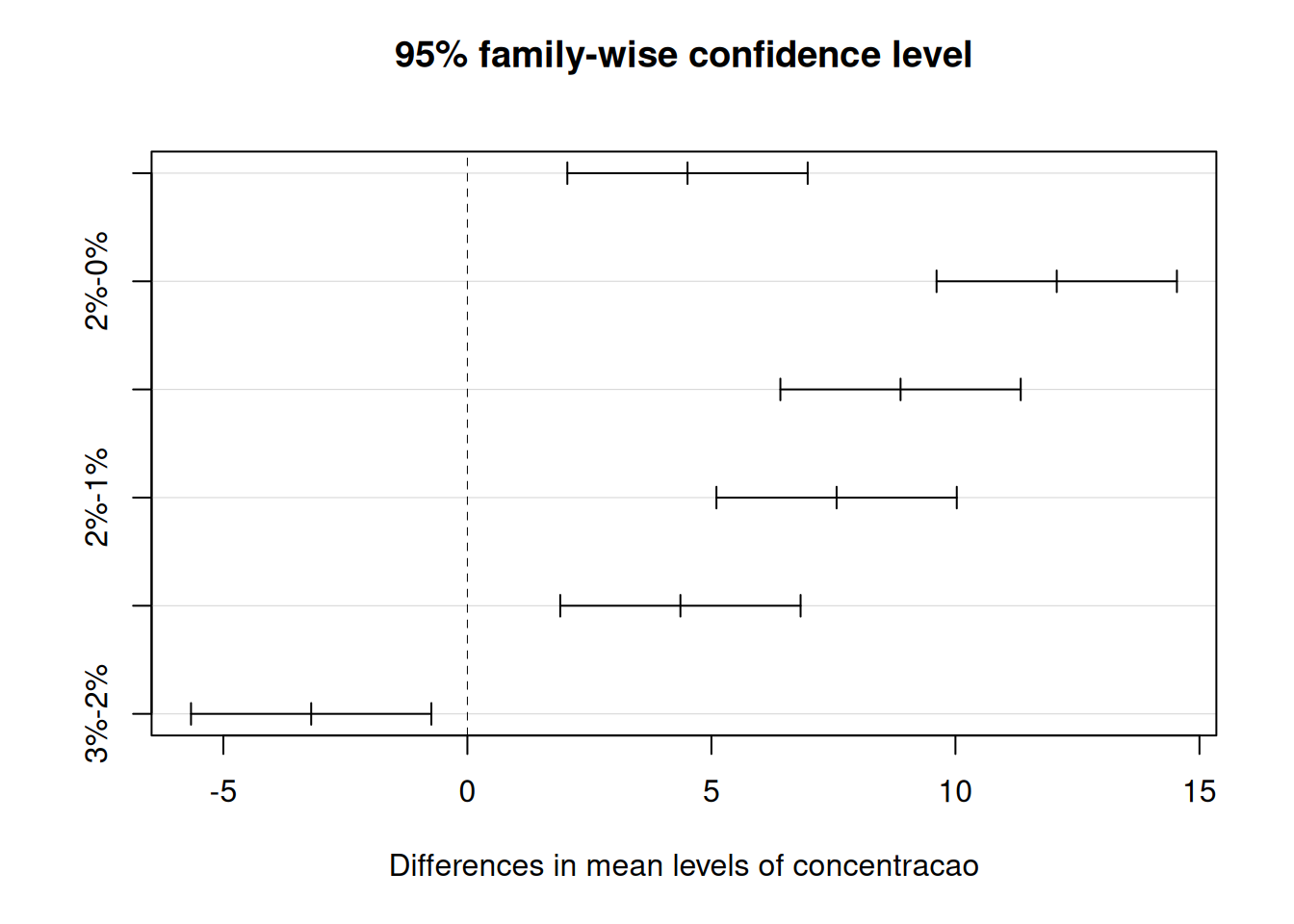
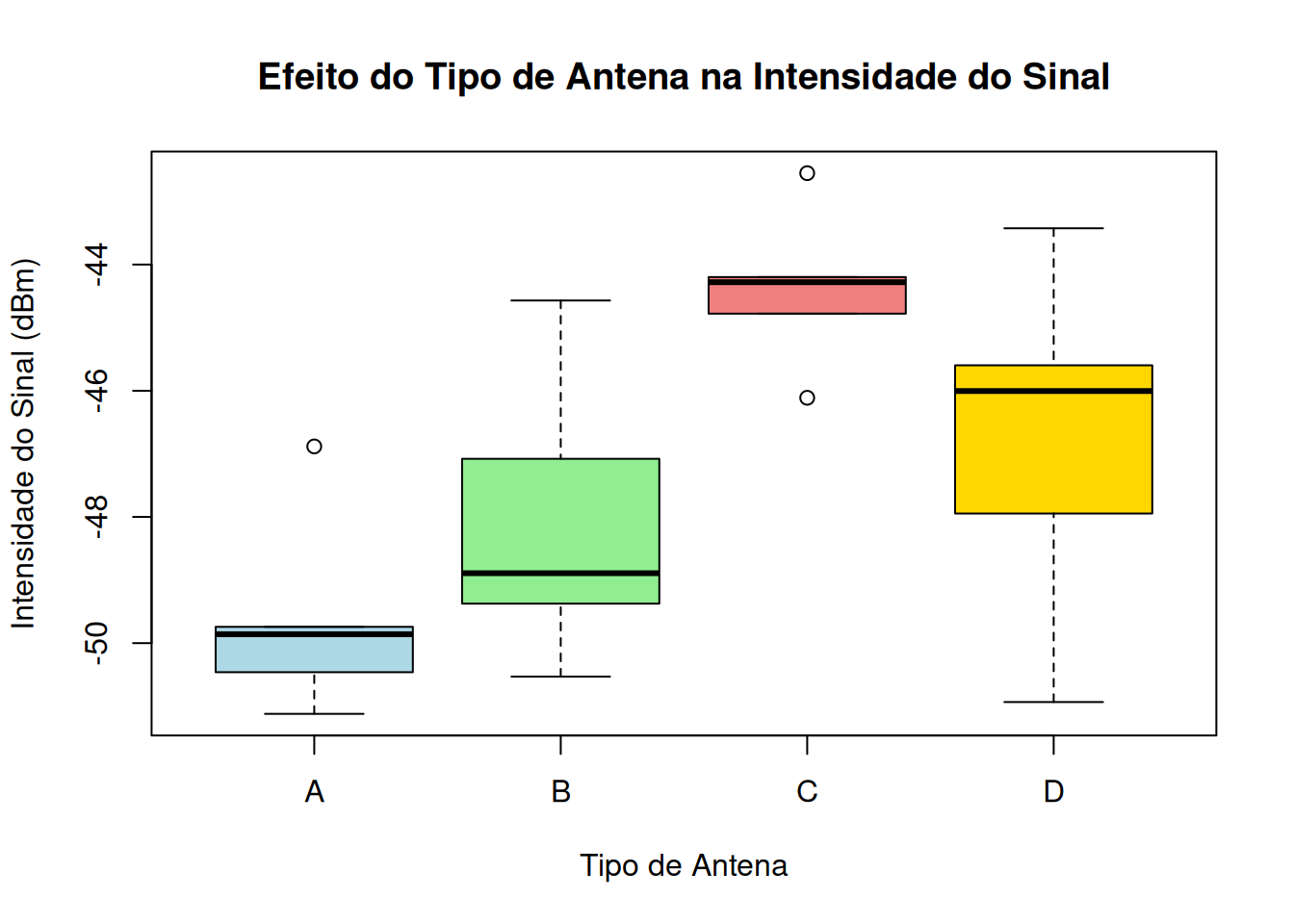
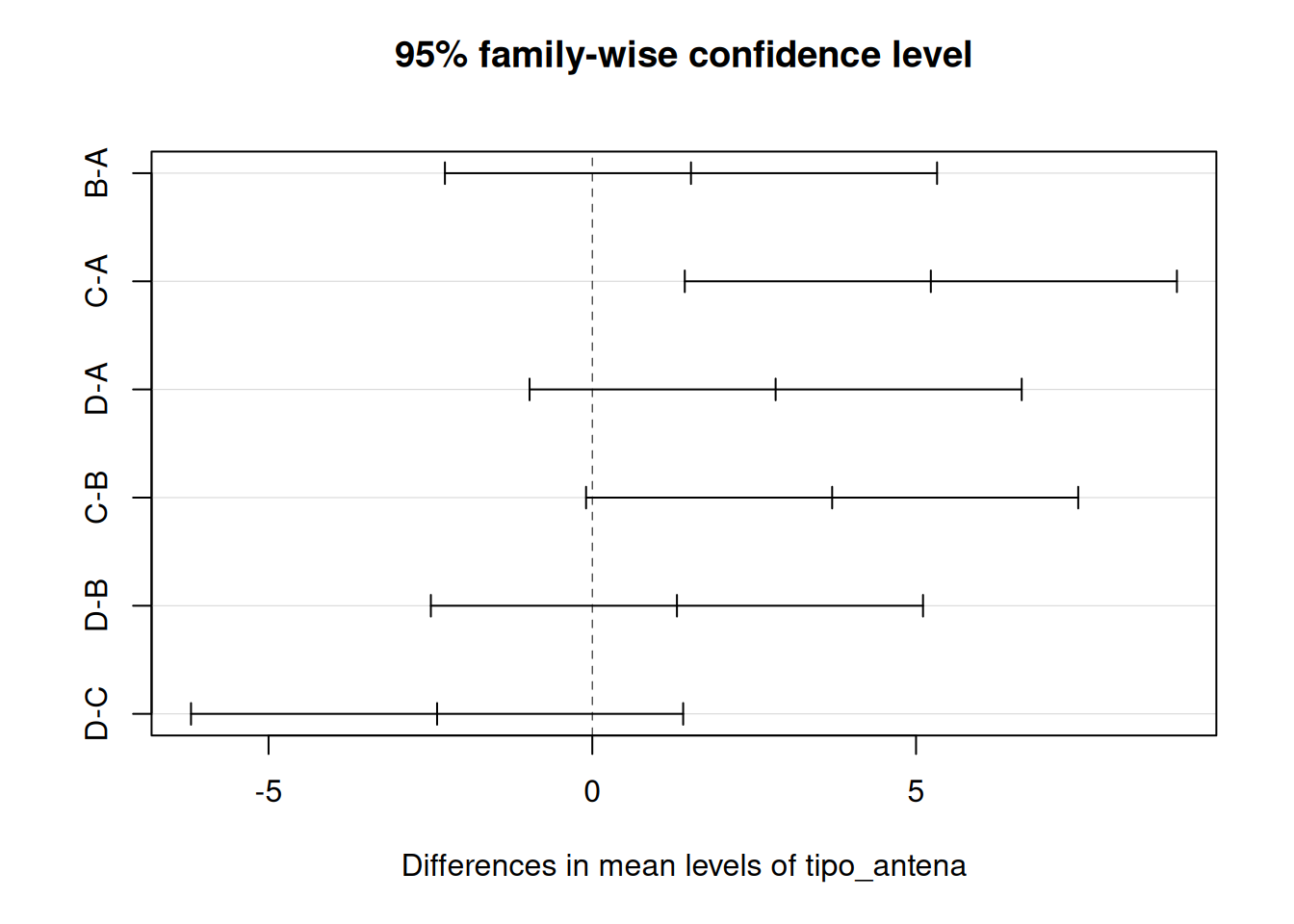
BANZATTO, D. A.; NASCIMENTO KRONKA, S. DO. Experimentação Agrícola. Jaboticabal: Funep, 2006. p. 237
BARBIN, D. Planejamento e Análise Estatística de Experimentos Agrômica. Arapongas: Midas, 2003. p. 208
BOLFARINE, H.; BUSSAB, W. O. Elementos de Amostragem. São Paulo: Edgard Blucher, 2005. p. 274
BOLFARINE, H.; SANDOVAL, M. C. Introdução à Inferência Estatística. 2. ed. São Paulo: SBM, 2010. p. 159
COCHRAN, W.; COX, G. M. Experimental Designs. 2. ed. New York: John Wiley & Sons, 2005. p. 618
CRESPO, A. A. Estatística Fácil. 19. ed. São Paulo: Saraiva, 2009. p. 232
DANTAS, C. A. B. Probabilidade: Um Curso Introdutório. 3. ed. São Paulo: EDUSP, 2008. p. 256
DRAPER, N. R.; SMITH, H. Applied regression analysis. 3. ed. New York: Wiley, 1998. p. 736
MAGALHAES, M. N. Probabilidade e variáveis aleatórias. 3. ed. São Paulo: EDUSP, 2011. p. 424
MAGALHAES, M. N.; LIMA, A. C. P. Noções de Probabilidade e Estatística. 7. ed. São Paulo: EDUSP, 2023. p. 428
MEYER, P. L. Probabilidade: aplicações á estatística. 2. ed. Rio de Janeiro: LTC, 2000. p. 426
MONTGOMERY, D. C. Design and Analysis of Experiments. 9. ed. New Jersey: Wiley, 2019. p. 752
MONTGOMERY, D. C.; RUNGER, G. C. Estatísta Aplicada e Probabilidade para Engenheiros. 7. ed. Rio de Janeiro: LTC, 2021. p. 416
MOOD, A. M.; GRAYBILL, F. A.; BOES, D. C. Introduction to the Theory of Statistics. New York: John Wiley & Sons, 1974. p. 564
PAGANO, M.; GAUVREAU, K. Princípios de Bioestatística. São Paulo: Thomson, 2004. p. 506
PIMENTEL-GOMES, F. Curso de Estatística Experimental. 15. ed. Piracicaba: FEALQ, 2022. p. 451
SILVA, N. N. Amostragem Probabilística. 3. ed. São Paulo: EDUSP, 2015. p. 136
SOUZA, G. S. Introdução aos Modelos de Regressão Linear e Não-Linear. Brasília: EMBRAPA, 1998. p. 489
STEEL, R. G. D.; TORRIE, J. H. Principles and procedures of statistics: A biometrical approach. 2. ed. New York: McGraw-Hill Book Company, 1980. p. 512