Sumário
- Caracterizando melhor o ambiente R
- Programação orientada a objetos
- Entendendo um pouco mais sobre objetos no
R - Aprofundamento sobre ambientes
- Programação Funcional
- Composição de funções
- Operadores binários
- Avaliação preguiçosa dos argumentos de uma função
- Saídas implícitas, explícitas, invisíveis de funções
- Funções de substituição
- Programação defensiva
- Controle de fluxos usando paralelização
- Banco de dados
- Gráficos
- Projetos no RStudio
- Projetos R no GitHub
- Introdução a desenvolvimento de pacotes
- Criação de documentações no R
- Documentos Web
- Páginas estatísticas
- Páginas dinâmicas
- Documentações de pacotes
- Documentações de ajuda .Rd
- Página Web de pacotes
- Livros
- Blogs e websites
- Relatórios
- Relatórios animados
- Relatórios dinâmicos
- Demais documentos (PDF, WORD, EPUB)
- Documentos Web
Slides de Aulas
- Aula 26: Apresentação do Curso
- Aula 27: Caracterizando melhor o ambiente R
- Aula 28: Introdução a POO no ambiente R
- Aula 29: Tipos de objetos base
- Aula 30: Sistemas de POO no R
- Aula 31: Sistema S3
- Aula 32: Sistema S3: Funções genéricas (POO no R)
- Aula 33: Sistema S3: Chamada UseMethod (POO no R)
- Aula 34: Sistema S3: Criando funções genéricas (POO no R)
- Aula 35: Sistema S3: Classes e classes implícitas (POO no R)
- Aula 36: Sistema S3: Métodos (POO no R)
- Aula 37: Revisão sobre as aulas 27 a 36 Slide Vídeo-aula Script R
- Aula 38: Sistema S3: Envio (despacho) de métodos
- Aula 39: Sistema S3: Mecanismo de herança
- Aula 40: Entendendo um pouco mais sobre objetos: estruturas atômicas ou recursivos
- Aula 41: Conhecendo outros objetos: Datas
- Aula 42: Conhecendo outros objetos: Datas, horas e fusos horários
- Aula 43: Cópia ao modificar, modificação no local de vetores
- Aula 44: Cópia ao modificar, modificação no local em funções
- Aula 45: Cópia ao modificar, modificação no local em listas
- Aula 46: Cópia ao modificar, modificação no local em quadro de dados (Data frames)
- Aula 47: Cópia ao modificar, modificação no local de vetores caracteres (strings)
- Aula 48: Tamanho de objetos
- Aula 49: Ambientes: Introdução aprofundada
- Aula 50: Ambientes funcionais
- Aula 51: Ambientes em pacotes
- Aula 52: Programação funcional: Introdução
- Aula 53: Programação funcional: Composição de funções
- Aula 54: Programação funcional: Operadores unários e binários
- Aula 55: Programação funcional: Avaliação preguiçosa dos argumentos de uma função
- Aula 56: Programação funcional: Saídas implícitas, explícitas, invisíveis de funções
- Aula 57: Programação funcional: funções de substituição
- Aula 58: Programação funcional: Vetorização de funções
- Aula 59: Programação funcional: funções da família apply
- Aula 60: Programação funcional: funções recursivas
- Aula 61: Programação defensiva em funções
- Aula 62: Projetos no RStudio
- Aula 63: Projetos no Github
- Aula 64: Introdução a desenvolvimento de pacotes
Scripts
- Script 00:
Exercícios e Scripts via Shiny
Apresentação do curso
O Curso R será todo aprensentado no formato online, sendo que as aulas terão vídeos como suporte, postados no canal Youtube/Ben Dêivide divulgados ao longo do material. Os vídeos serão bem objetivos de curta duração para que usem como suporte com o material escrito. Como complemento desse material, disponibilizaremos os scripts com os comandos utilizados em cada aula e sua versão em Shiny para os que não quiserem realizar inicialmente a instalação do R e do RStudio, poderão utilizar uma versão online do material juntamente com a linguagem R.
Caracterizando melhor o ambiente R
Ao estudarmos o módulo básico do Curso R, conseguimos obter uma visão geral sobre o ambiente R, de modo que o aprofundamento sobre a linguagem se faz necessário, para quem deseja não apenas executar rotinas prontas, mas de fato, um contribuidor para a linguagem, como também um desenvolvedor de suas próprias funções.
Na Figura 1, apresentamos um resumo do que buscamos repassar no primeiro módulo. Agora, iremos no módulo intermediário, de fato, entender os dois princípios: Objeto e Função, para que fique claro que nem tudo no R é orientado a objetos, e que a rigor o R não é uma linguagem de programação funcional. Com essas informações, dentre outras, o programador poderá ter um maior controle sobre o desenvolvimento de suas próprias rotinas e funções.
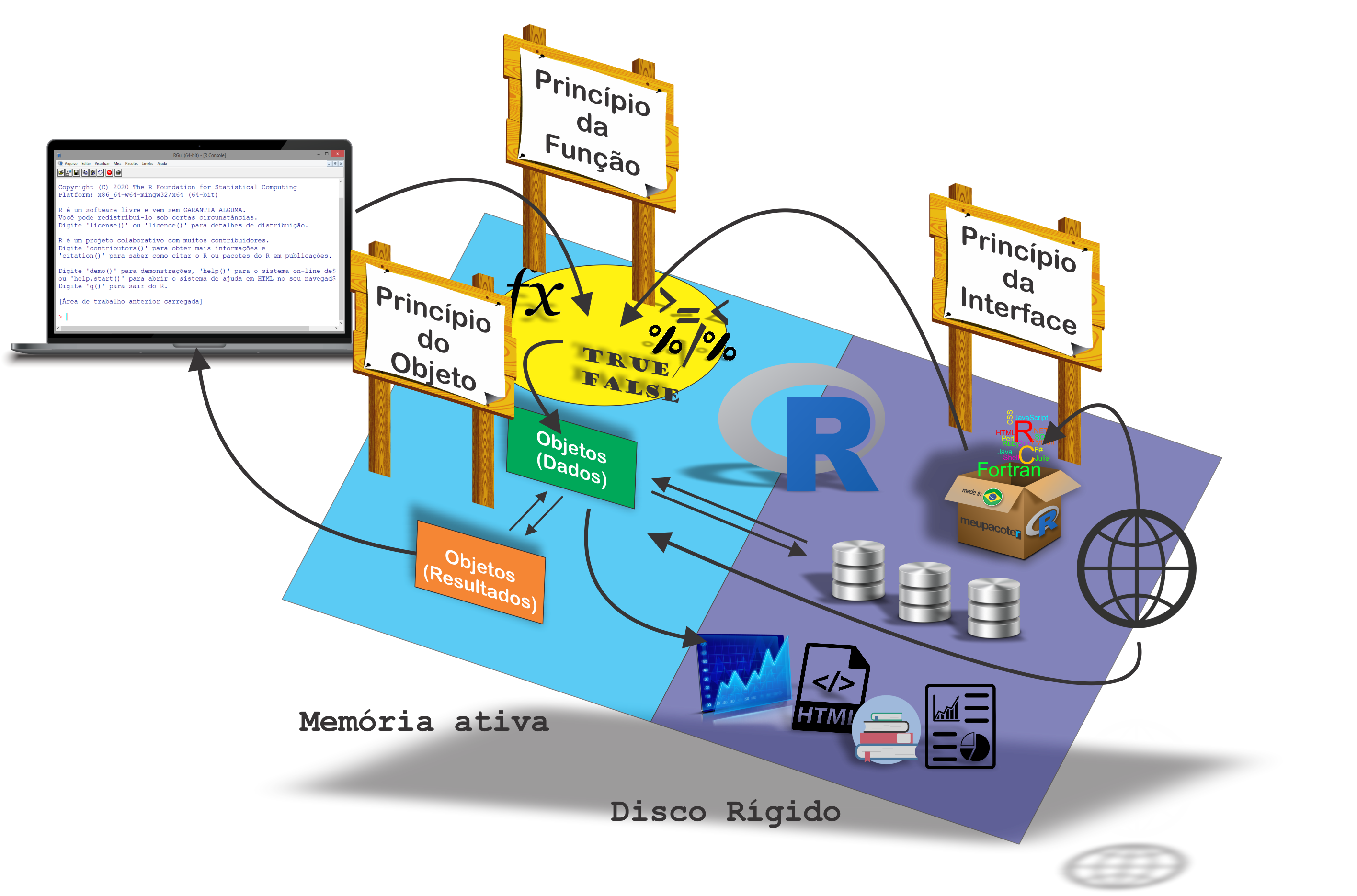
Figure 1: Relembrando como o R funciona.
Vamos inicialmente caracterizar melhor o R. Por que usamos os termos linguagem, software ou ambiente para o R? Na página do R, na seção about se inicia com a primeira pergunta: O que é o R? Em resposta da própria página e utilizando também como resposta a nossa indagação inicial, o “R é uma linguagem e ambiente para computação estatística e gráficos,” que ainda complementa que essa linguagem é uma implementação diferente da linguagem S, linguagem essa do qual inclui as principais implementações para análise estatística. Contudo, ocorrem algumas diferenças dentre as quais já apresentamos no módulo básico, a presença do escopo léxico no R, que não ocorre na linguagem S. Desse modo, percebemos que o R é uma linguagem interpretada, pois além da linguagem S (o que fácil para os usuários a implementação do código), a sua base foi programada em C e FORTRAN (para computação mais intensiva). Mas também, adjetivamos o R como ambiente de software ao invés de apenas software, e aqui predominaremos esse termo, pois segundo ainda na própia página do R se “pretende caracterizá-lo como um sistema totalmente planejado e coerente, ao invés de um acréscimo incremental de ferramentas muito específicas e inflexíveis, como é frequentemente o caso com outros softwares de análise de dados.” Assim, esse ambiente inclui:
- manipulação de dados;
- operações com matrizes;
- coleção de ferramentas para análise de dados;
- criação e apresentações gráficas, para apresentação dos dados;
- linguagem que inclui condicionais, fluxos de controle, funções recursivas definidas pelo usuário e recursos de entrada e saída;
- Documentação e relatórios de análises.
Existem linguagens como C e FORTRAN, por exemplo, que a execução do código nessas linguagem precisam de uma compilação, para depois serem executadas, isto é, as linhas de códigos programadas pelo usuário precisam ser convertidas na linguagem de máquina, para que depois seja executa. Porém, no R, quando escrevemos uma linha de comando no console, do tipo:
(x <- 10)
[1] 10Percebemos no R o código é automaticamente interpretado conforme o usuário executa. Desse modo, caracterizamos a linguagem de programação dinâmica. A ideia se estende a avaliação de funções, a extensão da linguagem sem o uso de macros, e a manipulação com ambiente. Ainda mais, podemos afirmar também que essa dinamicidade está relacionada ao fato do R também ser uma linguagem fortemente e dinamicamente tipada. Nesse caso, os valores contidos nos objetos é que são tipados. Por exemplo, vetores atômicos apresentam sempre elementos com mesmo tipo. Porém, à medida que adicionamos elementos ao vetor, pode haver a coersão da tipagem dos elementos, quando esses elementos apresentam tipos diferentes, como foi abordado no módulo básico, na seção coersão. Vejamos um exemplo, a seguir.
vetor <- TRUE; typeof(vetor)
[1] "logical"vetor[2] <- 1; typeof(vetor)
[1] "double"vetor[3] <- "1"; typeof(vetor)
[1] "character"vetor
[1] "1" "1" "1"Observemos que o objeto associado ao nome vetor vai alterando a tipagem por coersão, é o comportamento dinâmico da linguagem. Observe que o nome vetor é um objeto de tipo symbol e o vetor c("1", "1" "1") é outro objeto, cujos os elementos foram coagidos a tipagem character. Claro, que o acesso ao vetor só é possível recuperar da memória ativa, se este estiver associado a algum nome, no caso vetor. Porém, não é o nome que altera o seu tipo, mas os elementos do objeto associado a este nome, em que, por ser um verto atômico, seus elementos devem apresentar o mesmo tipo.
A ideia do R como uma linguagem de programação com estilo funcional, se deve pelo fato da linguagem ter funções de primeira classe, function(), isto é, funções que se comportam como qualquer outro objeto no ambiente R. Por exemplo, podemos atribuir nomes as nossas funções, armazená-las em listas, serem criadas dentro de outras funções, serem argumentos de outras funções, ou até ser um resultado de uma função. Inclusive na versão do R 4.1, a função function() ganhou um novo formato, que também pode ser usado. Vejamos o exemplo:
# Forma original
soma1 <- function(x) x + 1; soma1(1)
[1] 2# Forma alternativa (>= R 4.1)
soma1 <- \(x) x + 1; soma1(1)
[1] 2Para complementar atualizações dessa versão, uma outra importante foi implemento da função pipe (%>%). Originalmente, a função pipe (lê-se paipe) é do pacote magrittr da família de pacotes tidyverse, do qual é um operador binário em que o primeiro operando é um objeto para a entrada de dados, e o segundo é uma função. Nesse caso, o objeto no primeiro operando entrará no primeiro argumento da função no segundo operando. Vejamos um exemplo, a seguir.
# install.packages(magrittr) # Instalando o pacote
library(magrittr) # anexando o pacote
1:10 %>% mean
[1] 5.5Observe que calculamos a média do vetor 1:10. Agora, a versão do pipe nativa no R (>= 4.1), sua sintaxe é |>. Vejamos o mesmo exemplo usado anteriormente, agora com a função nativa, isto é,
1:10 |> mean()
[1] 5.5A diferença no caso do pipe nativo é que no segundo argumento, além do nome da função, acrescemos o parênteses sem seus argumentos. Lembrando que o primeiro operando entrará no primeiro argumento da função (segundo operando).
Retornando a programação funcional, sabemos que o R não é estritamente funcional. A definição de programação funcional apresenta algumas características, dentre elas, que a linguagem apresente:
- Composição de funções;
- Funções puras;
- Imutabilidade;
- Efeito colateral;
A ideia da composição de funções representa a criação de funções por meio de outras funções, e isso está dentro da linguagem R. Por exemplo, vamos criar uma função que calcula a média de um conjunto de dados, usando a função, mean(), já existente no pacote base, isto é,
x <- 1:10
media <- function(x) mean(x)
media(x)
[1] 5.5A caracterização de funções puras, significa que as funções sempre retornam o mesmo resultado, dados os mesmos parâmetros de entrada, isto significa que não existe efeito colateral. Um exemplo de função pura, pode ser como:
fpura <- function(x) {
if (!is.numeric(x)) stop("x deve ser numérico")
x + 1
}
fpura(x = 2)
[1] 3Observe que fpura() toda vez que a entrada for x = 2, o resultado sempre será o resultado 3. Porém, o R se exclui dessa característica estritamente funcional, quando aprensentamos funções: runif(), rnorm(), read.csv(), dentre outras. Por exemplo, a função rnorm() representa um gerador de números aleatórios de uma distribuição normal, do qual se executarmos essa função, mais de uma vez, usando a mesma entrada para o argumento n = 3, o resultado não será sempre o mesmo, observe:
A imutabilidade na programação funcional apresenta em uma linguagem na situação em que uma variável ou objeto é criado, e este não pode ser modificado. Esta é outra característica que ocorre no R, mas não para todos os objetos em que exitem nomes associados, é o caso da modificação no local. Por exemplo, vamos apresentar um contra-exemplo de que nem todos os objetos no R são imutáveis. Vejamos:
Para a execução dessas linhas de comando, sugerimos que não utilizem diretamente o RStudio, porque a IDE sempre faz uma referência a cada objeto. Sugerimos que utilize a própria interface do R. Esse tema será aprodundado mais a frente, na seção entendendo um pouco mais sobre objetos.
Por fim, duas outras características importantes do estilo funcional da linguagem, é o escopo léxico das funções, assunto abordado no módulo básico, e a execução preguiçosa, do qual o argumentos das funções são avaliados apenas quando utilizados. Vejamos, o exemplo a seguir.
preguicoso <- function(a, b = faux()) a * 100
preguicoso(4)
[1] 400Observemos nesse caso, que o argumento b recebe uma função aux() que não existe. Contudo, ao executar a linha de comando seguindo, a função preguicoso retorna o resultado 400 sem erro. Isso porque como não foi necessário utilizar o argumento b no corpo da função, este não foi avaliado, e portanto, sem retorno de erro da função preguicoso. Iremos mais a frente, detalhar essa característica de modo mais aprofundado.
O R não é uma linguagem totalmente orientada a objetos, como afirmado por alguns. Apesar, de um dos princípios do R que tudo é um objeto, não significa dizer que tudo é orientado a objetos. Isso se deve ao fato de que os primeiro objetos criados no R, que chamaremos de objetos base, foram desenvolvidos baseados na linguagem S. E nesse tempo não havia qualquer cogitação de que fosse necessário um sistema de programação orientada a objetos (POO). Veremos mais a frente, que a distinção básica entre objetos base e objetos baseados em sistemas orientados a objetos, chamaremos de objetos POO, é que estes últimos terão o atributo class, do qual podemos consultá-lo pela função attr(). Vejamos, alguns exemplos:
Quando não há o atributo class, isto é, NULL, é objeto base. Contudo, iremos na seção Programação orientada a objetos saber em que sistemas esses objetos estão orientados, porque no R, diferentemente de outras linguagens, existem vários sistemas POO, como: S3, S4 R5 (classes de referências), R6, dentre outros.
Por fim, como última caracterização do R abordada é como uma linguagem de programação metaparadigma ocorre porque pela própria linguagem, poderemos inspecioná-la, modificá-la, por ela mesma, como se fosse um objeto, o que acaba tornando uma ferramenta muito poderosa. E isso será tema abordado mais a frente.
Portanto, esclarecido isso, e ainda com as demais características apresentadas no módulo básico, dizemos que o R é:
- um ambiente de software livre e código aberto, com licença GNU;
- umalinguagem de programação interpretada;
- uma linguagem de programação dinâmica;
- uma linguagem de programação funcional;
- de escopo lêxico;
- avaliação preguiçosa;
- uma linguagem de programação orientada a objetos;
- uma linguagem de tipagem forte e dinâmica; e
- uma linguagem de programação metaparadigma.
Programação orientada a objetos
Assim como no nosso dia a dia podemos realizar uma mesma tarefa de modos diferentes, isso ocorre também na programação. Nesse caso, dizemos que esses modos são os paradigmas da programação. E a programação orientada a objetos (POO) é um desses paradigmas que veio para contornar alguns problemas da programação estrutural, um outro paradigma.
Antes de apresentarmos outras diferenças entre os objetos base e objetos OO, se faz necessário entendermos alguns conceitos da POO, do qual tudo se desencadeará pelos termos classe, objeto e método. Para isso, vamos ilustrar alguns termos baseados no nosso cotidiano. Uma das grandes cobiças nessa era digital é ter um bom smartphone para que possamos estar conectados nessa era digital, bem não sei se foi bem esse objetivo do smartphone, mas consideremos que tenha sido. Essa escolha se deve a algumas características tamanho, cor, desempenho, câmera, dentre outras. Outro fator que pode ter sido o motido da sua escolha é o comportamento desse celular, como o seu desempenho do processador, a velocidade com o qual se desenvolve as atividades, a forma como os aplicativos reagem as suas ações, o sistema como o algoritmo baseado em inteligência artificial interage com todo o sistema operacional do aparelho, dentre outros. Nesse momento, fazendo uma relação com o ambiente R, dizemos que o celular que desejamos é o objeto, suas características são os atributos do objeto, e o comportamento será o método aplicado a este objeto na programação orientada a objetos.
Mesmo que seu aparelho apresente um IMEI (Código de identificação do aparelho) único, nós sabemos que existem diversos aparelhos com essa mesma configuração, modelo e marca, alguns outros com pequenas características que o diferenciam, mas conseguimos identificar ainda assim, esse objeto como um celular. Portanto, podemos dizer que o celular é uma classe para o ambiente R, em que apesar de termos diversos objetos, estes são identificados dentro de um conjunto de características que o definem como celular. Nesse caso, dizemos ainda que o celular que escolhemos é uma instância dessa classe, que apesar de ter atributos próprios, ainda assim, é identificado como um celular. Desse modo, ao ser definidos as classes de determinados objetos, a linguagem saberá utilizar o método correto para tal objeto, isso significa que mesmo que não saibamos como ocorre, devemos confiar que ocorrerá. Isso é programação orientada a objetos.
Teríamos mais analogias para abordar, como encapsulamento, hierarquias , envio (ou despacho) de método, polimorfismo, subclasses, superclasses, dentre outras. Mas, vamos deixar para discutir ao longo das aplicações.
Assim, esse paradigma da programação permite associarmos o desenvolvimento do nosso código pra dentro de nossa realidade humana. Porém a ideia de POO dentro do R sai do escopo de implementações densenvolvidas em outras linguagens. Antes de entrarmos no tema propriamente dito, queremos ressaltar que não estamos interessados em repassar uma POO eficiente, devido a todo o cunho teórico exigido para o assunto. Mas, queremos repassar como os principais sistemas de POO foram desenvolvidos dentro do R.
Nem tudo é orientado a objetos no R
Uma primeira ideia que temos que saber é que apenas de um dos princípios que tudo no R é um objeto, mas nem tudo é orientado a objetos. Isso ocorre, porque discutimos anteriormente, que o R é um dialeto da linguagem S. No início do desenvolvimento da linguagem S, John Chambers e seus colaboradores nem cogitavam para a implementação do código a programação orientada a objetos, desse modo, o R quando começou a ser densevolvido, os primeiros objetos desenvolvidos foram vêm dessas primeiras versões da linguagem S, sem ainda a implementação de POO.
Dessa forma, vamos distinguir o R com dois tipos de objetos:
- Objetos POO (Objetos para POO)
- Objetos base (Objetos não voltados a POO)
A principal diferença técnica é que um objeto POO terá o atributo class, e o objeto base, não. Vejamos,
# Objeto "data.frame"
objPOO <- data.frame(a = 1, b = "1", c = TRUE)
# Objeto "data.frame" eh um objeto POO?
is.object(objPOO)
[1] TRUE# Vetor de comprimento 10
objBASE <- 1:10
# O vetor eh um objeto POO?
is.object(objBASE)
[1] FALSEPela função is.object(), sabemos se um objeto é de POO ou não. Entretanto, no R temos diversos sistemas POO, alguns da base de instalação do programa, e outros disponíveis no CRAN. Detalharemos os tipos, a seguir.
Objetos base
Existem 24 tipos de objetos diferentes no R (antes eram 26, porém o objetos referentes a fatores e fatores ordenados foram retirados). A base de criação desses objetos foram a linguagem C, e que na realidade são ponteiros para uma estrutura com typedef SEXPREC. Os seus tipos estão representados por SEXPTYPE, que determina como as características da estrutura são usadas. Para mais detalhes, ler R Language Definition e R Internals. Alguns tipos são importantes para o usuário R, outros apenas com importância interna ao ambiente R, dos quais esses tipos podem ser identificados pela função typeof(), que segue:
Representação em R |
Representação em C (SEXPTYPE) |
Descrição |
|---|---|---|
NULL |
NILSXP |
Único vetor que tem comprimento zero e não pode ter atributo |
logical |
LGLSXP |
Vetores lógicos |
integer |
INTSXP |
Vetores inteiros |
double |
REALSXP |
Vetores reais |
complex |
CPLXSXP |
Vetores complexos |
character |
STRSXP |
Vetores caracteres (strings) |
list |
VECSXP |
Listas |
raw |
RAWSXP |
Vetores brutos |
closure |
CLOSXP |
Funções criadas por meio de function() |
special |
SPECIALSXP |
Funções primitivas (funções básicas e operadores) que são escritas principalmente na linguagem C. Desse modo, essas funções não apresentam as três estruturas básicas de uma função do tipo closure, como formals(), body(), environment(), que são todas NULL. Aprofundaremos esse objeto no módulo avançado |
bultin |
BUILTINSXP |
Funções primitivas (funções básicas e operadores) que são escritas principalmente na linguagem C. Desse modo, essas funções não apresentam as três estruturas básicas de uma função do tipo closure, como formals(), body(), environment(), que são todas NULL. Aprofundaremos esse objeto no módulo avançado |
environment |
ENVSXP |
Ambientes |
S4 |
S4SXP |
Objetos com sistema POO S4 |
symbol |
SYMSXP |
Nomes associados aos objetos |
language |
LANGSXP |
Objetos de linguagem, que abordaremos na seção sobre metaprogramação |
pairlist |
LISTSXP |
Argumento das funções |
expression |
EXPRESXP |
Vetores de expressão |
externalptr |
EXTPTRSXP |
Ponteiro externo, são vetores exóticos que tem importância para a linguagem C |
weakref |
WEAKREFSXP |
Referência fraca, são vetores exóticos que tem importância para a linguagem C |
bytecode |
BCODESXP |
Código de byte, são vetores exóticos que tem importância para a linguagem C |
promise |
PROMSXP |
Promessas, são objetos responsáveis pelo pelo carregamento preguiçoso dos argumentos de uma função |
... |
DOTSXP |
Objeto utilizado como um argumento da função, após a criação de uma função, ainda assim, podem ser inseridos mais argumentos |
any |
ANYSXP |
Objeto que representa qualquer tipo. Raramente utilizado em R, mas aparece por exemplo em as.vector(x, mode = "any"), considerando que x é um objeto R |
| - | CHARSXP |
Cadeia de caracteres internas, isto é, um tipo de escalar string, usado somente internamente |
Todas as funcões que usam esses objetos base e apresentam comportamento diferentes, não usam o sitema POO, porque foram implementadas em sua maioria na linguagem C, usando a instrução switch, em que também aprofundaremos no módulo avançado.
Sistemas de POO no R
Usando as ideias de Chambers (2016), complementadas por Wickham (2019), dizemos que o paradigma da programação orientada a objetos pode ser dividida em dois ramos:
- POO encapsulada: os métodos são encapsulado em suas classes, isto é, os objetos nesse estilo de programação contém os seus comportamentos;
- POO funcional: os métodos pertencem as funções, das quais serão aplicadas aos objetos de determinada classe.
O R em sua base, apresenta três sistemas de POO: S3, S4 e CR (classes de referência). No CRAN, existem diversas implementações de POO, das quais podemos citar: R6 (pacote R6), R.oo, proto, dentre outros.
Exploraremos para esse momento, apenas o sistema S3 (POO funcional), em que o sitema S4 também apresenta o paradigma POO funcional. Esses dois sistemas foram a evolução da implementação de POO na linguagem S implementadas no R. Contudo, os seus nomes geram a impressão de que também haviam os sistemas S1 e S2, mas não, os nomes S3 e S4 se devem as versões da linguagem S, como evolução da linguagem em si. Nesses momentos, foram o marco para a incorporação da programação orientada a objetos na linguagem, em que antes não existia, por isso, não haver sistemas S1 e S2.
Para complementar a carcterização dos sistemas citados, os sistemas RC e R6 apresentam o paradigma POO encapsulado. Os demais sistemas implementados nos pacotes disponíveis no CRAN, como R.oo fornece algum formalismo em cima de S3 e torna possível ter objetos S3 mutáveis (Wickham (2019)), e proto que implementa outro estilo de OOP baseado na ideia de protótipos , que confundem as distinções entre classes e instâncias de classes (objetos) (Wickham (2019)), do qual foi o sistema implementado para o pacote ggplot2.
Sistema S3
Poderíamos descrever todos os sistemas, porém restringiremos ao sistema S3, por uma única razão, é o sistema amplamente empregado aos objetos dos pacotes base e stats, bem como na maioria dos pacotes disponíveis no CRAN. Mais detalhes sobre o sistema, sugerimos leituras em Chambers (2016), Wickham (2019), Chambers (2008), Chambers and Hastie (1991), dentre outros materiais.
Como falado anteriormente, um objeto POO terá sempre um atributo class, em que podemos utilizar a função atributes para verificar isso. Vejamos,
quadro_dados <- data.frame(a = 1, b = TRUE, c = "A")
attributes(quadro_dados)
$names
[1] "a" "b" "c"
$class
[1] "data.frame"
$row.names
[1] 1O fato do objeto quadro_dados ter o atributo class=data.frame, lhe dá um comportamento especial a determinadas funções genéricas. Vejamos como imprimos essa função pela funcão print(), isto é,
print(quadro_dados)
a b c
1 1 TRUE ARemovendo esse atributo do objeto, por meio da função unclass(), voltamos ao tipo de objeto base subjascente. Dessa forma, a função print perde esse comportamento especial, apresentada a seguir.
Isso significa, que o objeto data.frame perde seu comportamento especial e retorna ao mesmo comportamento de uma lista. Afinal, falamos no módulo básico que um objeto data.frame é uma lista.
Funções genéricas
A base do sistema S3 está nas funções genéricas ou também podemos chamar de genéricos, que buscam o método específico para determinada classe de um objeto. Esta função representa um intermediário do sistema S3, do qual define os argumentos de entrada, e na sequência, encontra o método certo, baseado na classe do objeto associado ao primeiro argumento da função genérica. Para sabermos se uma função é genérica, temos algumas funções: utils::isS3stdGeneric() e sloop::ftype(). Verificando esta última função, além de informar se é uma função genérica, informa também o sistema POO, além do que a função utils::isS3stdGeneric() apenas retorna TRUE, as funções genéricas S3 que apresentam no corpo de sua função, a chamada UseMethod. Vale lembrar, que funções primitivas/internas não apresentam essa chamada de função. Dessa forma, usaremos, principalmente, a função sloop::ftype() como pesquisa por funções genéricas. Vejamos,
# Funcoes do tipo "closure" que nao pertencem ao sistema S3
utils::isS3stdGeneric(data)
[1] FALSEsloop::ftype(data)
[1] "function"# Funcao generica S3 em funcoes do tipo "closure"
utils::isS3stdGeneric(mean)
mean
TRUE sloop::ftype(mean)
[1] "S3" "generic"# funcoes primitivas e internas que nao pertencem ao sistema S3
utils::isS3stdGeneric(inherits)
[1] FALSEsloop::ftype(inherits)
[1] "internal"#-----
utils::isS3stdGeneric(unclass)
[1] FALSEsloop::ftype(unclass)
[1] "primitive"# funcoes genericas do sistema S3 que sao primitivas e internas
utils::isS3stdGeneric(length)
[1] FALSEsloop::ftype(length)
[1] "primitive" "generic" #--
utils::isS3stdGeneric(unlist)
[1] FALSEsloop::ftype(unlist)
[1] "internal" "generic" A função sloop::ftype() retorna um vetor de caracteres de comprimento 1 ou 2. Quando retorna apenas um valor, do qual não obtemos o resultado generic, significa que esta função não é genérica, como é o caso da função data. Quando há um retorno de dois valores, e um deles é generic, significa dizer que a função é genérica, em que o primeiro valor, representa o sistema POO, como é o caso da função mean. No caso, das funções primitivas/internas que estão no pacote base, o primeiro resultado da função sloop::ftype() para a referida função será primitive ou internal, e se houver o segundo valor de nome generic, se confirma que também é um função primitiva genérica do método S3.
As funções genéricas do tipo closure terão no corpo de sua função a chamada UseMethod, uma função primitiva . Essa é a identificação básica de uma função genérica. Podemos observar, como exemplo, a função mean:
mean
function (x, ...)
UseMethod("mean")
<bytecode: 0x0000000008e55c60>
<environment: namespace:base>Entretanto, funções primitivas e internas são escritas em linguagem C, mas também podem ser funções genéricas. Não há função no R para acesso direto do código interno interno dessas funções, bem como de seus argumentos. O que na realidade deve ser feito é acessar código fonte. Para isso, podemos pesquisar sobre alguma função primitiva, por exemplo '[[', por pryr::show_c_source(.Primitive("[[")).
O que ocorre nesse caso, é que estas funções não usam a chamada UseMethod. Desse modo, as funções primitivas e internas podem ser identificadas, pelo objeto .S3PrimitiveGenerics, um vetor de caracteres, que seguem:
.S3PrimitiveGenerics
[1] "anyNA" "as.character" "as.complex"
[4] "as.double" "as.environment" "as.integer"
[7] "as.logical" "as.call" "as.numeric"
[10] "as.raw" "c" "dim"
[13] "dim<-" "dimnames" "dimnames<-"
[16] "is.array" "is.finite" "is.infinite"
[19] "is.matrix" "is.na" "is.nan"
[22] "is.numeric" "length" "length<-"
[25] "levels<-" "names" "names<-"
[28] "rep" "seq.int" "xtfrm" # Outras funcoes primitivas
(outros_obj_S3_primitivos <- c("[", "[[", "$", "[<-", "[[<-", "$<-"))
[1] "[" "[[" "$" "[<-" "[[<-" "$<-" # Outras funcoes internas nao primitivas
(outros_obj_S3_primitivos <- c("unlist", "cbind", "rbind", "as.vector"))
[1] "unlist" "cbind" "rbind" "as.vector"Algumas outras funções como is.name que é sinônimo da função is.symbol, assim como a função as.numeric é sinônimo da função as.double. Existem outras funções genéricas que também são primitivas/internas, são as funções genéricas do grupo S3 que não estão descritos no objeto .S3PrimitiveGenerics. Há quatro desses grupos para que os métodos S3 podem ser escritos, denominados: grupo Math, grupo Ops, grupo Summary e grupo Complex. Detalhamos as funções:
- Grupo
Math:abs,sign,sqrt,floor,ceiling,trunc,round,signifexp,log,expm1,log1p,cos,sin,tan,cospi,sinpi,tanpi,acos,asin,atan,cosh,sinh,tanh,acosh,asinh,atanhlgamma,gamma,digamma,trigammacumsum,cumprod,cummax,cummin
- Grupo
Ops:"+","-","*","/","^","%%","%/%""&","|","!""==","!=","<","<=",">=",">"
- Grupo
Summary:all,any,sum,prod,min,max,range
- Grupo
Complex:- Arg,
Conj,Im,Mod,Re
- Arg,
Apesar não termos funções com nomes Math, Ops, Summary e Complex no pacote base, e portanto, também não serem objetos R, podemos fornecer métodos para estes, como por exemplo, no pacote base, temos métodos como:
- Métodos de
Math:
methods("Math")
[1] Math,CsparseMatrix-method Math,ddenseMatrix-method
[3] Math,denseMatrix-method Math,dgeMatrix-method
[5] Math,diagonalMatrix-method Math,nonStructure-method
[7] Math,sparseMatrix-method Math,sparseVector-method
[9] Math,structure-method Math.data.frame
[11] Math.Date Math.difftime
[13] Math.factor Math.POSIXt
[15] Math.quosure* Math.vctrs_sclr*
[17] Math.vctrs_vctr*
see '?methods' for accessing help and source code- Métodos de
Summary:
methods("Summary")
[1] Summary,abIndex-method Summary,ddenseMatrix-method
[3] Summary,ddiMatrix-method Summary,dsparseMatrix-method
[5] Summary,indMatrix-method Summary,ldenseMatrix-method
[7] Summary,ldiMatrix-method Summary,lMatrix-method
[9] Summary,Matrix-method Summary,ndenseMatrix-method
[11] Summary,nMatrix-method Summary,nsparseVector-method
[13] Summary,sparseVector-method Summary.data.frame
[15] Summary.Date Summary.difftime
[17] Summary.factor Summary.numeric_version
[19] Summary.ordered Summary.POSIXct
[21] Summary.POSIXlt Summary.quosure*
[23] Summary.roman* Summary.unit*
[25] Summary.vctrs_sclr* Summary.vctrs_vctr*
see '?methods' for accessing help and source code- Métodos de
Complex:
methods("Complex")
[1] Complex.vctrs_sclr*
see '?methods' for accessing help and source codeOs métodos que estão com asterisco é porque não são exportados do namespace dos pacotes em que essas funções foram criadas. Para isso, use :::, getS3method ou getAnywhere. Por exemplo, se tentarmos procurar pelo método str.data.frame no console, não iremos encontrar porque ela não foi exportada pelo namespace do pacote utils. Para acessar o referido método, segue:
# Primeira forma:
getAnywhere("str.data.frame")
A single object matching 'str.data.frame' was found
It was found in the following places
registered S3 method for str from namespace utils
namespace:utils
with value
function (object, ...)
{
if (!is.data.frame(object)) {
warning("str.data.frame() called with non-data.frame -- coercing to one.")
object <- data.frame(object)
}
cl <- oldClass(object)
cl <- cl[cl != "data.frame"]
if (0 < length(cl))
cat("Classes", paste(sQuote(cl), collapse = ", "), "and ")
cat("'data.frame':\t", nrow(object), " obs. of ", (p <- length(object)),
" variable", if (p != 1)
"s", if (p > 0)
":", "\n", sep = "")
if (length(l <- list(...)) && any("give.length" == names(l)))
invisible(NextMethod("str", ...))
else invisible(NextMethod("str", give.length = structure(FALSE,
from = "data.frame"), ...))
}
<bytecode: 0x000000002494ac48>
<environment: namespace:utils># Segunda forma (Sistema S3 apenas):
getS3method("str", "data.frame")
function (object, ...)
{
if (!is.data.frame(object)) {
warning("str.data.frame() called with non-data.frame -- coercing to one.")
object <- data.frame(object)
}
cl <- oldClass(object)
cl <- cl[cl != "data.frame"]
if (0 < length(cl))
cat("Classes", paste(sQuote(cl), collapse = ", "), "and ")
cat("'data.frame':\t", nrow(object), " obs. of ", (p <- length(object)),
" variable", if (p != 1)
"s", if (p > 0)
":", "\n", sep = "")
if (length(l <- list(...)) && any("give.length" == names(l)))
invisible(NextMethod("str", ...))
else invisible(NextMethod("str", give.length = structure(FALSE,
from = "data.frame"), ...))
}
<bytecode: 0x000000002494ac48>
<environment: namespace:utils># Terceira forma
utils:::str.data.frame
function (object, ...)
{
if (!is.data.frame(object)) {
warning("str.data.frame() called with non-data.frame -- coercing to one.")
object <- data.frame(object)
}
cl <- oldClass(object)
cl <- cl[cl != "data.frame"]
if (0 < length(cl))
cat("Classes", paste(sQuote(cl), collapse = ", "), "and ")
cat("'data.frame':\t", nrow(object), " obs. of ", (p <- length(object)),
" variable", if (p != 1)
"s", if (p > 0)
":", "\n", sep = "")
if (length(l <- list(...)) && any("give.length" == names(l)))
invisible(NextMethod("str", ...))
else invisible(NextMethod("str", give.length = structure(FALSE,
from = "data.frame"), ...))
}
<bytecode: 0x000000002494ac48>
<environment: namespace:utils>Os métodos desenvolvidos no pacote base com asterisco dos métodos genéricos de grupo não são acessados pelas funções anteriores. Por fim, vamos criar uma pequena rotina, adaptado de Chambers (2016), para vermos quais e quantas funções genéricas primitivas existem no pacote base, a seguir.
# Todos os objetos do pacote 'base'
todosobj <- objects(baseenv(), all.names = TRUE);
# Mostre apenas os primeiros (ver todos remova 'head')
head(todosobj)
[1] "-" "-.Date" "-.POSIXt" "!" "!.hexmode"
[6] "!.octmode"# Quantos objetos no pacote 'base'?
length(todosobj)
[1] 1373# Quais sao funcoes primitivas?
objprimitivos <- todosobj[sapply(todosobj, function(x) is.primitive(get(x, envir = baseenv())))]
# Mostre os primeiros (ver todos remova 'head')
head(objprimitivos)
[1] "-" "!" "!=" "$" "$<-" "%%" # Quantos primitivos ('buitin' ou 'special')?
length(objprimitivos)
[1] 204# Quais sao primitivos genéricos (Sistema S3)?
ehPrimitivaGenerica <- function(primitiva) {
fprimitiva <- getFunction(primitiva, mustFind = FALSE, where =asNamespace("base"))
ehgenerica <- sloop::ftype(fprimitiva)
if (any(ehgenerica == "generic")) {
TRUE
} else FALSE
}
# Mostre os primeiros (ver todos remova 'head')
head(sapply(objprimitivos, ehPrimitivaGenerica))
- ! != $ $<- %%
TRUE FALSE TRUE TRUE TRUE TRUE [1] 100Entendendo melhor a chamada UseMethod
Na seção anterior, falamos que as funções genéricas do tipo closure, usam no corpo da função a chamada UseMethod. Esta é uma função primitiva, desenvolvida em C, porém usa a correspondência padrão de argumentos, com sintaxe dada por:
UseMethod(generic, object)
em que o argumento generic representa o nome da função genérica (obrigatório para utilizar na chamada de UseMethod), e o segundo argumento object é o objeto cuja classe determina o método a ser enviado para execução pela função genérica. O argumento objeto representa o primeiro argumento da função genérica, e portanto, na prática usamos apenas o argumento generic, uma vez que a função UseMethod se encarrega do resto.
Uma outra coisa importante é que a chamada da função UseMethod deve ser usada apenas no corpo de uma função, isto é, function(x) UseMethod("fgenerica"). Caso contrário, ocorre o retorno de erro, isto é,
Error in eval(expr, envir, enclos): 'função' genérica não é uma funçãoDesse modo, a forma correta de declarar a chamada de função Usemethod, baseado no exemplo anterior, deve ser apresentado como segue,
Portanto, o objeto associado ao nome fgenerica é o que chamamos de função genérica. Nesse caso, o código interno de UseMethod examina o atributo class no objeto do primeiro argumento da função genérica, que no caso da função genérica fgenerica anterior, é o argumento x.
A chamada UseMethod insere objetos especiais no ambiente de avaliação da função genérica, que são .Class, .Generic e .Method. Eles são responsáveis pelo despacho de método e os mecanismos de herança. O objeto .Class representa a classe do objeto (primeiro argumento da função genérica), .Generic é o nome da função genérica, e .Method é o nome do método usado. Poderá surgir também um outro objeto chamado .Group, quando funções genéricas são primitivas que se enquandram dentro das funções genéricas de grupo, visto mais a frente. De todo modo, isso é serviço para o R internamente e o usuário não precisará se preocupar. Vejamos o código a seguir, para observamos como podemos obter informações desses objetos.
generico <- function(x) UseMethod("generico")
generico.metodo <- function(x) cat("Imprima o valor dos objetos .Generic, .Class e .Method, respectivamente:\n", .Generic, "\n", .Class, "\n", .Method)
x <- 1; class(x) <- "metodo"
generico(x)
Imprima o valor dos objetos .Generic, .Class e .Method, respectivamente:
generico
metodo
generico.metodoUma coisa interessante, é que a função UseMethod por ser primitiva, não cria seu próprio ambiente, mas a sua chamada ocorre no ambiente de chamada, isto é, no ambiente de execução da função genérica. Além do mais, como o ambiente de chamada da função UseMethod é o ambiente de execução da função genérica, um código interno em UseMethod faz com que o ambiente de chamada seja finalizado após o método ter sido avaliado. Em outras palavras, o que for escrito no corpo da função genérica após a chamada UseMethod, não será executado nem avaliado. Vejamos um exemplo, para clarear o que estamos falando, que segue,
# Funcao generica
quem <- function(x) {
print("Isso pode ser impresso!")
UseMethod("quem")
## Apos a Chamada UseMethod o ambiente eh encerrado!
print("Isso nao sera impresso!")
}
## Metodo
quem.eh <- function(x) print("Sou eu! (arg x)")
# Aplicacao:
pessoa <- "ben" # objeto sem atributo 'class'
class(pessoa) <- "eh"
quem(pessoa)
[1] "Isso pode ser impresso!"
[1] "Sou eu! (arg x)"Observemos nesse caso, que a linha de comando no corpo da função genérica quem, antes da chamada UseMethod é avaliada e executada, porém, o que ocorre após não é executado, uma vez, que não é impresso no console o resultado "Isso nao sera impresso!". Logo, após a chamada de UseMethod e o envio de método para quem.eh e a ocorrência de sua execução, o ambiente de execução de quem é finalizado, do qual, print("Isso nao sera impresso!") não é executado.
Criando funções genéricas
Como já mostrado em alguns exemplos na seção anterior, a forma de criar uma função genérica é por meio da inserção no corpo da criação de uma função, a chamada UseMethod. A ideia da função genérica, é encontrar o método específico para uma determinada instância de classe (objeto). Desse modo, criamos uma função genérica da seguinte forma:
# Funcao generica
quem <- function(x) {
UseMethod("quem")
}
Assim, quem é uma função genérica. Esta função tem o objetivo, por meio de UseMethod, identificar a classe do objeto definido em x, e depois o envio de método, isto é, encontrar o método (objeto função) específico para a classe do objeto em x.
Classe e classe implícita
Usuário de outras linguagens que estudaram POO , por exemplo em Java, C++, Python, devem estar muito confusos, até esse momento, como o sistema S3 não tem uma forma usual de definir uma classe. Para isso, basta usar o atributo class em um objeto. Desse modo, este se torna uma instância da classe.
Já vimos no módulo básico como verificar os atributos em um objeto, por meio da função attributes(). Vamos expandir um pouco mais, antes de passarmos para o atributo class. Vejamos a seguir, como inserir um ou mais de um atributo aos objetos, bem como eliminá-los.
# Objeto
(x <- 1:10)
[1] 1 2 3 4 5 6 7 8 9 10# Inserindo atributos em um objeto (1ª Forma)
attr(x,"dim") <- c(2, 5) # 1º Atributo 'dim'
attr(x,"class") <- "ben" # 2º Atributo 'ben'
attr(x,"nada") <- "1" # 3º Atributo 'nada'
# Visualizar os atributos em x
attributes(x)
$dim
[1] 2 5
$class
[1] "ben"
$nada
[1] "1"# Eliminando um determinado atributo ('nada')
attr(x,"nada") <- NULL # Remove atribuindo 'NULL'
# Visualizar os atributos em x, sem o atributo 'nada'
attributes(x)
$dim
[1] 2 5
$class
[1] "ben"# Eliminar todos os atributos
attributes(x) <- NULL
# Visualizando x sem atributos
attributes(x)
NULL# Inserindo os atributos todos de uma vez
mostattributes(x) <- list(dim = c(2, 5), class = "ben", nada = "1")
# Verificando se um objeto apresenta determinado atributo, por exemplo, class='nada'
inherits(x, "nada")
[1] FALSE# Outra forma de inserir mais de um atributo
x <- structure(1:10, dim = c(2, 5), class = "ben", nada = "1")
# Casos especificos, podem ter funcoes proprias
# para inserir atributos, por exemplo, 'class'
attr(x,"class") <- NULL; attributes(x) # removendo o atributo 'class'
$dim
[1] 2 5
$nada
[1] "1"class(x) <- "ben"; attributes(x)
$dim
[1] 2 5
$nada
[1] "1"
$class
[1] "ben"Percebemos que alguns atributos têm funções próprias, além do atributo class, temos dim, levels, names, dimnames, dentre outros.
Para esse caso, iremos nos concentrar apenas no atributo class. Seguindo as próprias recomendações de Wickham (2019), e com razão, podemos utilizar qualquer conjunto de caracteres para nominar a classe de interesse. Porém, evitemos utilizar o ponto (“.”) como parte dos caracteres para nominar a classe, porque na próxima seção, veremos que o ponto é parte sintática da criação de um método, em que nominamos o método pela junção do nome da função genérica mais o nome da classe, separados por um ponto. E para evitar confusão, seguiremos essa sugestão.
Desse modo, poderemos retirar um objeto como instância de uma classe, removendo o atributo class. Essa flexibilidade na prática, não apresenta grandes problemas, um vez que como afirmado por Wickham (2019), o R não impede do programador atirar no próprio pé, desde que ele não aponte a arma para o pé e puxe o gatilho. Mais a frente, apresentaremos algumas sugestões propostas por Wickham (2019), do qual adotaremos.
Uma outra característica do atributo class é que este pode ser um vetor de caracteres. Por exemplo, um vetor atômico do tipo fator é largamente utilizado na estatística, quando queremos representar os níveis de um tratamento, em que para usar a função aov(), função para a realização da análise de variância, um dos argumentos da função faz-se necessário ser um fator. Em algumas situações, além de ser um fator, é importante que os níveis sejam ordenados, na estatística descritiva, chamamos também de variáveis qualitativas ordinais.
Para criarmos um vetor do tipo fator, usamos a função factor, e a sua ordenação, ou usamos em factor, o argumento ordered=TRUE, ou criamos um fator ordenado pela função ordered(). Usando este último, e associando a um nome, vamos perceber que o atributo class desse objeto é um vetor de comprimento 2, isto é,
[1] "ordered" "factor" # Observando os atributos do objeto
attributes(x)
$levels
[1] "1" "2" "3" "4" "5"
$class
[1] "ordered" "factor" Essa sequência será responsável pelo mecanismo de herança de métodos, que discutiremos mais a frente. No entanto, quando o objeto em R não é objeto POO, a função class pode retornar resultados equivocados quanto ao despacho do método. Por exemplo, vamos criar um vetor multidimensional, do tipo array, e verificarmos o que a função class retorna,
Porém, usando a função sloop::s3_class() ou .class2, perceberemos uma maior detalhamento, observemos:
Isso é o que chamamos de classes implícitas aos objetos base, que não tem o atributo class definido. Segundo Wickham (2019), a classe implícita, obtida de objetos base, apresenta um vetor de três conjuntos de caracteres (strings):
arrayoumatrix, se o objeto tiver dimensão;- resultado de
typeof, com algumas variações; numeric, se os valores foreminteger(inteiro) oudouble(real).
Para mostrarmos que a função class não retorna corretamente o despacho de método utilizado, isto é, para qual método a chamada da função genérica (UseMethod) foi executado, vamos utilizar a função sloop::s3_dispatch(). O despacho ocorrerá no método que contém (=>). Vejamos,
# Imprimindo o despacho do objeto associado a 'y'
sloop::s3_dispatch(print(y))
print.matrix
print.integer
print.numeric
=> print.defaultObserve que o despacho ocorreu em print.default. O que fica mais claro, nesse segundo exemplo, o que queremos afirmar,
# Objeto com classe implícita (sem atributo 'class')
w <- 1
# Imprimindo class
class(w)
[1] "numeric"# Verificando o despacho em 'print'
sloop::s3_dispatch(print(w))
print.double
print.numeric
=> print.defaultObservemos nesse caso que class retorna numeric, e o despacho ocorre em print.default, e não em print.numeric como verificado por class, ficando mais evidente o que falamos anteriormente. Na seção envio de método e mecanismos de herança, detalharemos um pouco mais sobre o assunto.
Por fim, um último ponto que queríamos abordar são os termos técnicos como subclasse e superclasse. Anteriormente, vimos o objeto x <- ordered(1:5) que era um fator ordenado, e que o seu atributo class era um vetor de comprimento 2, isto é, "ordered" "factor". Dizemos que "ordered" é uma subclasse de "factor" porque o antecede no vetor, assim como "factor" é considerada uma superclasse para "ordered" porque o precede. A rigor, o sistema S3 não faz imposição nenhuma a estas classes, mas veremos na seção envio de método e mecanismos de herança, algumas estratégias para isso.
Método S3
O método no sistema S3 tem a seguinte estrutura no nome da função 'nome_funcao_generica'.'nome_classe'. Vamos supor que criamos uma classe para o objeto pessoa, com atributo class sendo eh, isto é,
# Objeto
pessoa <- "ben"
# Atribuindo classe ao objeto 'pessoa'
class(pessoa) <- "eh"
Como falado no módulo básico, os atributos não modificam os valores dos objetos. Então até aqui, nada de novo. Para criarmos o método, baseado na função genérica quem, criada anteriormente, e na classe eh, criamos um método (objeto de modo function no R, ou tipo closure) quem.eh, isto é,
## Metodo
quem.eh <- function(x) print("Sou eu!")
Algo muito importante no método é que a função deve ter os mesmos argumentos da função genérica, a menos que seja utilizado o objeto ... na função genérica. De um modo geral, apresentamos alguns aspectos e sugestões para a criação de um método, que destacamos:
- Um método deve ser criado considerando a existência de uma função genérica ou uma classe;
- O método deve apresentar os mesmos argumentos que a função genérica, e estes não se alteram no código interno da função genérica. Caso a função genérica apresente o objeto
'...', o número de argumentos entre a função genérica e o método podem ser diferentes; - Reforçando, evitem nos nomes das funções genéricas ou classes o uso de pontos, porque o ponto é uma forma sintática de criarmos o nome do método, isso evitará problemas para o despacho correto. Um exemplo é a função
t.test, que poderíamos imaginar que fosse um método, em queté a função genérica etesta classe. Na realidade,t.testé uma função genérica, pois usa a chamadaUseMethod. A criação desse objeto o R deve ter ocorrido, muito provavelmente, antes da implementação do sistema S3 a base do R; - A chamada de função deve ser realizada, preferencialmente pela função genérica, porém nada impede de ser realizada pelo próprio método. Nesse caso, ocorrem alguns aspectos internos ao código, que chamaremos atenção mais a frente;
- Na criação de funções genéricas em pacotes, deem preferências ao nome das classes exatamente igual ao nome do pacote em desenvolvimento. Isso evitará possíveis conflitos de nomes de classes;
Finalizado a criação do método, o que ocorrerá agora é que não precisaremos chamar o método pelo próprio método, mas pela função genérica, é o que chamamos de envio de método (ou despacho de método). Essa é a caixa preta da POO, devemos acreditar que isso ocorrerá, claro, se todo o processo de criação estiver correto.
Um outro método que se sugere criar é o padrão (default), para que se a função genérica não encontrar o método específico, ela procurará pelo método padrão. Se não existir o método padrão, caso não encontre o método específico, a função genérica pode retornar uma mensagem de erro. Vejamos a implementação, a seguir.
# Objeto
pessoa <- "ben"
# Atribuindo classe ao objeto 'pessoa'
class(pessoa) <- "eh"
## Metodo 'eh'
quem.eh <- function(x) print("Sou eu!")
## Metodo 'padrao'
quem.default <- function(x, y) print("??")
#-----------------------------------------
# Aplicacao:
pessoa <- "ben" # objeto sem atributo 'class'
# Usando a funcao generica
quem(pessoa) # Aplicando o metodo padrao
[1] "??"#--------
class(pessoa) <- "eh"
quem(pessoa) # Aplicando o metodo eh
[1] "Sou eu!"Retornando sobre a função UseMethod, quando inserimos os dois argumentos generic e object no corpo da função genérica, e definimos em object qual o objeto que a função observará o atributo class, a chamada de função UseMethod desconsiderará o primeiro argumento da função genérica, independente de ter um atributo class ou não. Vejamos um exemplo,
# Funcao generica
quem <- function(y) UseMethod("quem", x)
# Metodos
quem.eh <- function(y) print("Sou eu!")
quem.outro <- function(y) print("Outro!")
quem.default <- function(y) print("Qualquer um!")
# Objeto em UseMethod sem o atributo 'class'
x <- "ben"
# Objeto no primeiro argument de fgenerica
y <- "ninguem"
class(y) <- "outro"
# O despacho ocorre em quem.default
quem(y)
[1] "Qualquer um!"# Removendo quem.defaul, a fgenerica retorna erro
rm("quem.default"); quem(y)
Error in UseMethod("quem", x): método não aplicável para 'quem' aplicado a um objeto de classe "character"Contudo, se o objeto definido em object não tiver o atributo class, e não houver um despacho para o método fgenerica.default, a função genérica (fgenerica) retorna um erro. Vejamos outro exemplo,
quem <- function(y) UseMethod("quem", x)
quem.eh <- function(y) print("Sou eu!")
quem.outro <- function(y) print("Outro!")
quem.default <- function(y) print("Qualquer um!")
# Objeto em UseMethod
x <- "ben"
class(x) <- "eh"
# Objeto no primeiro argument de fgenerica
y <- "ninguem"
class(y) <- "outro"
# Executando a funcao generica
quem(y)
[1] "Sou eu!"Uma coisa interessante que ocorre com a chamada UseMethod, que foge a exceção do padrão de chamadas das funções. Vejamos o código a seguir.
# Funcao (Primeiro caso)
h <- function(x, y) {
x <- 10
y <- 10
c(x = x, y = y)
}
x <- 1
y <- 1
h(x, y)
x y
10 10 #----------------------------------------
# Funcao generica e metodo (Segundo caso)
g <- function(x, y) {
x <- 10
y <- 10
UseMethod("g")
}
# metodo padrao
g.default <- function(x, y) c(x = x, y = y)
# Avaliacao
x <- 1
y <- 1
g(x, y)
x y
1 1 #----------------------------------------
# Funcao generica e metodo (Terceiro caso)
g <- function(x) {
x <- 10
y <- 10
UseMethod("g")
}
# metodo padrao
g.default <- function(x) c(x = x, y = y)
# Avaliacao
x <- 1
y <- 1
g(x)
x y
1 10 #-----------------------------------------
# Funcao generica e metodo (Quarto caso)
g.default <- function(x) c(x = x, y = y)
# Avaliacao
x <- 1
y <- 1
g.default(x)
x y
1 1 Observemos no primeiro caso, em que definimos duas variáveis globais x <- 1 e y <- 1, ao serem utilizadas como argumentos da função h(), percebemos que após a chamada de h(), o ambiente de execução é criado temporariamente, e lá existe três instâncias x <- 10, y <- 10 e a chamada c(x = x, y = y), em que esta última busca por x e y, que é encontrado nas duas instâncias anteriores, e que portanto, sobrepõe a entrada dos argumentos. Logo, o resultado de h(x, y) será um vetor de comprimento 2, com valores 10 e 10, respectivamente.
No segundo caso, temos uma função genérica, e aqui surge algo meio inconsistente, aparentemente com a chamada UseMethod no corpo da função genérica. Mais vez, esta função nos surpreende, porque ela não permite a alteração dos argumentos definidos na função genérica com variáveis definidas no código interno dessa função, para posteriormente, seguir no despacho do método. Observemos na função genéricag(), que apesar de associado valores para os nomes x e y, todos iguais a 10, ao chamarmos g(), definimos para os seus argumentos x e y valores iguais a 1, e o que ocorre após a chamada dessa função é um vetor de 1s (uns). Isto siginifica, que as instâncias internas da função genérica, não alteraram os argumentos da função, e o despacho de método segue para g.default().
No terceiro caso, a função genérica apresenta apenas um argumento, x. Observemos nesse caso, que o código interno do método g.default() procura por um objeto associado a y, que é encontrado primeiro no ambiente de execução da função genérica, cujo resultado é 10. Porém, mesmo havendo um nome x associado ao valor 10, no ambiente de execução da função genérica, a chamada UseMethod preserva o argumento x = 1 definido em g(), que despacha para o método. Ao final, o resultado da função genérica é um vetor com valores 1 e 10, respectivamente.
Por fim, o quarto caso, cuja a chamada de função ocorre diretamente pelo método e não pela função genérica. Nesse caso, o resultado será igual ao que ocorre com a função h(), porque não há o despacho pela chamada UseMethod, e portanto, não se preserva os argumentos da função no código interno da função genérica.
Retornando a criação de métodos, uma forma de criar um método é por meio de funções primitivas genéricas. No fim da seção Funções genéricas, mostramos um código como encontrar as funções primitivas genéricas. O procedimento será o mesmo, isto é, determinado a função genérica, por exemplo, print, e posteriormente, definir uma classe específica para um objeto. Vamos implementar um método para print, a seguir.
# Objeto classe 'comp'
x <- 1:10; class(x) <- "comp"
# Metodo 'comp'
print.comp <- function(x) {
x <- unclass(x)
cat("O comprimento de ", x, " eh ", length(x))
}
# Aplicacao
print(x) # Metodo 'comp'
O comprimento de 1 2 3 4 5 6 7 8 9 10 eh 10 [1] 1 2 3 4 5 6 7 8 9 10Além de as funções internas/primitivas não terem a chamada UseMethod1, que podem dificultar a identificação de uma função genérica, alguns de seus métodos não estão exportadas pelo namespace do pacote base. Para verificarmos o código interno (instruções) desses métodos, podemos usar três funções: :::, getS3method ou getAnywhere, já comentados na seção Funções genéricas.
Podemos usar a função utils::methods(), sloop::s3_methods_generic() ou sloop::s3_methods_class(). Com essas, funções podemos saber por meio do nome ou da função genérica ou pelo nome da classe, quais os métodos disponíveis. Vejamos pelo código a seguir, por exemplo usando a função genérica print, quais os métodos disponíveis, isto é,
# Usando o nome da funcao generica
# utils::methods(print)
## [1] print.acf*
## [2] print.AES*
## [3] print.all_vars*
## [4] print.anova*
## [5] print.ansi_string*
## [6] print.ansi_style*
## ...
# Usando agora a funcao s3_methods_generic
sloop::s3_methods_generic("print")
# A tibble: 317 x 4
generic class visible source
<chr> <chr> <lgl> <chr>
1 print acf FALSE registered S3method
2 print AES FALSE registered S3method
3 print all_vars FALSE registered S3method
4 print anova FALSE registered S3method
5 print any_vars FALSE registered S3method
6 print aov FALSE registered S3method
7 print aovlist FALSE registered S3method
8 print ar FALSE registered S3method
9 print Arima FALSE registered S3method
10 print arima0 FALSE registered S3method
# ... with 307 more rowsObservamos, pelos pacotes instalados no computador do qual escrevemos esse material, apresenta para a função genérica print, 284 métodos. Porém, observamos que a última função sloop::s3_methods_generic() apresenta um maior detalhamento dos métodos, como por exemplo, a visibilidade de suas instruções no console, e ainda de qual pacote o método foi desenvolvido. Nesse caso, quando na coluna visible, um determinado método retorna FALSE, que é equivalente a um asterisco no resultado, por meio da função methods(), que significa que o método não é exportado do namespace do pacote, em que esse método foi desenvolvido. Contudo, mostramos anteriormente, alternativas de como acessar esses métodos.
De outro modo, poderíamos está interessados em métodos baseados em uma determinada classe. Nesse caso, vejamos um exemplo para a classe factor, a seguir.
# Usando o nome da funcao generica
utils::methods(class = factor) # Imprimindo os primeiros metodos para a classe 'factor'
[1] [ [[ [[<- [<-
[5] all.equal Arith as.character as.data.frame
[9] as.Date as.list as.logical as.POSIXlt
[13] as.vector c cbind2 coerce
[17] Compare droplevels format initialize
[21] is.na<- length<- levels<- Logic
[25] Math Ops plot print
[29] rbind2 relevel relist rep
[33] show slotsFromS3 summary Summary
[37] xtfrm
see '?methods' for accessing help and source code# Usando agora a funcao s3_methods_generic
sloop::s3_methods_class("factor")
# A tibble: 28 x 4
generic class visible source
<chr> <chr> <lgl> <chr>
1 [ factor TRUE base
2 [[ factor TRUE base
3 [[<- factor TRUE base
4 [<- factor TRUE base
5 all.equal factor TRUE base
6 as.character factor TRUE base
7 as.data.frame factor TRUE base
8 as.Date factor TRUE base
9 as.list factor TRUE base
10 as.logical factor TRUE base
# ... with 18 more rowsPara o caso dos genéricos de grupo, sabemos que os grupos Math, Ops, Summary, e Complex não são objetos R, porém esses nomes podem ser usados para a criação de métodos S3. Uma outra coisa interessante nessa situação é que os objetos .Generic, .Class e .Methods, sofrem uma pequena variação da forma convencional dos nomes da função genérica, da classe e do método, respectivamente. Vamos tomar como exemplo a função sum() que pertence ao grupo Summary, e vamos criar um método para o grupo Summary, a seguir.
# Metodo ben
Summary.ben <- function(..., na.rm=FALSE) {
c(.Generic, .Class, .Method)
}
# Vamos aplicar a funcao sum em um obj de classe 'ben'
x <- structure(1, class = "ben")
sum(x)
[1] "sum" "ben" "Summary.ben"Observamos nesse primeiro exemplo que o objeto .Generic acaba recebendo o nome da função genérica do grupo e não o nome do grupo, como poderíamos pensar. Porém, o nome do método acaba sendo relacionado com o nome do grupo e não da função genérica aplicada, nesse caso. No que isso interfere na semântica do sistema S3? Tudo! Vejamos um outro exemplo, com o código a seguir.
# Metodo
Summary.ben <- function(..., na.rm=FALSE) {
"Eu sou do grupo 'Summary'"
}
# Objeto de classe 'ben'
x <- structure(2, class = "ben")
# Genericos do grupo 'Summary'
all(x); any(x); sum(x); prod(x); min(x); max(x); range(x)
[1] "Eu sou do grupo 'Summary'"[1] "Eu sou do grupo 'Summary'"[1] "Eu sou do grupo 'Summary'"[1] "Eu sou do grupo 'Summary'"[1] "Eu sou do grupo 'Summary'"[1] "Eu sou do grupo 'Summary'"[1] "Eu sou do grupo 'Summary'"Como criamos o método a partir do nome do grupo, todas as funções genéricas desse grupo despacharão nesse método, e o resultado para todas as funções será o mesmo. Um outro recurso, seria utilizar a função switch() para diferenciar o despache de método, apesar desse envio ser no próprio Summary.ben(). Vejamos o próximo código para esse elucidar o que acabamos de falar.
# Metodo
Summary.ben <- function(..., na.rm=FALSE) {
switch(.Generic,
all = paste0("Eu sou do grupo 'Summary', mas generico: ", .Generic),
any = paste0("Eu sou do grupo 'Summary', mas generico: ", .Generic),
sum = paste0("Eu sou do grupo 'Summary', mas generico: ", .Generic),
prod = paste0("Eu sou do grupo 'Summary', mas generico: ", .Generic),
min = paste0("Eu sou do grupo 'Summary', mas generico: ", .Generic),
max = paste0("Eu sou do grupo 'Summary', mas generico: ", .Generic),
range = paste0("Eu sou do grupo 'Summary', mas generico: ", .Generic))
}
# Objeto de classe 'ben'
x <- structure(2, class = "ben")
# Genericos do grupo 'Summary'
all(x); any(x); sum(x); prod(x); min(x); max(x); range(x)
[1] "Eu sou do grupo 'Summary', mas generico: all"[1] "Eu sou do grupo 'Summary', mas generico: any"[1] "Eu sou do grupo 'Summary', mas generico: sum"[1] "Eu sou do grupo 'Summary', mas generico: prod"[1] "Eu sou do grupo 'Summary', mas generico: min"[1] "Eu sou do grupo 'Summary', mas generico: max"[1] "Eu sou do grupo 'Summary', mas generico: range"Ou ainda, poderíamos ter criado um método apenas para uma função genérica específica do grupo. Desse modo, não criamos o método a partir do nome do grupo, mas da própria função. Vejamos o próximo código.
# Metodo para o generico 'min'
min.ben <- function(..., na.rm = FALSE) paste0("Eu sou do grupo 'Summary', mas generico: ", .Generic)
# Objeto de classe 'ben'
x <- structure(2, class = "ben")
# Generico do grupo 'Summary': min()
min(x)
[1] "Eu sou do grupo 'Summary', mas generico: min"# Ja com um outro generico de 'Summary', o resultado eh diferente
max(x)
[1] 2Uma vez entendido a criação de método, vamos entender na sequência, os detalhes que a chamada UseMethod() realiza para o envio de método e os mecanismos de herança e como esse processo ocorre para as funções genéricas primitivas e os grupos genéricos, que não apresentam a chamada UseMethod() en seu código interno.
Envio de método e mecanismo de herança
Como falado anteriormente, o atributo class em um objeto, pode ser um vetor de strings, e ter diversos nomes. Já comentamos anteriormente sobre o envio de método ou também podemos chamar como despacho de método.
Envio ou despacho de método
A ideia do envio de método e a criação de um vetor de potenciais nomes de métodos, como por exemplo esse:
E desse modo a chamada UseMethod se encarregará de verificar quais os métodos que existem. Pode haver mais de uma existência de método, será chamado o primeiro método na sequência de métodos existentes. Para verificar isso, podemos usar a função sloop::s3_dispatch(), isto é,
# Objeto de classe 'data.frame'
x <- data.frame()
# Despacho (envio) do generico 'print'
sloop::s3_dispatch(print(x))
=> print.data.frame
* print.defaultO resultado da chamada sloop::s3_dispatch() pode apresentar três símbolos antes dos potenciais nomes de métodos:
=>: este símbolo indica que a função genérica despachou no referido método;*: este símbolo indica que este método existe, mas a função genérica não despachou nele;->: indica o método chamado subjacente, após o método com o símbolo=>ter sido chamado. Isso ocorre, por no método representado por"=>"existe uma função nominada porNextMethodque faz o serviço de chamar o próximo método. Veremos esse ponto mais a frente.
No código anterior, vimos os dois símbolos => e *. Interpretamos que a função genérica print(x) despachou em print.data.frame(), mas que o método print.default existia, porém não foi utilizado.
Vejamos o próximo código para entendermos o que significa o símbolo (->) na saída da função sloop::s3_dispatch().
# Funcao generica
quem_sou_eu <- function(x, ...){
UseMethod("quem_sou_eu")
}
# Metodo numero natural
quem_sou_eu.numero_natural <- function(x, ...){
message("Eu sou um numero natural")
NextMethod("quem_sou_eu")
}
# Metodo numerico
quem_sou_eu.numerico <- function(x, ...){
message("Eu sou numerico")
}
x <- 1:10
class(x) <- c("numero_complexo","numero_natural","numerico")
sloop::s3_dispatch(quem_sou_eu(x))
quem_sou_eu.numero_complexo
=> quem_sou_eu.numero_natural
-> quem_sou_eu.numerico
quem_sou_eu.defaultObservemos que a função genérica quem_sou_eu() despachou no método quem_sou_eu.numero_natural, símbolo (=>), mas internamente nesse método, nós temos a chamada NextMethod() que invoca o próximo método. Nesse caso foi quem_sou_eu.numerico, com o símbolo (->). Os demais métodos não existem, pois não apresentam o asterisco (*). Entenderemos um pouco mais sobre a chamada NextMethod() mais a frente.
Funções primitivas genéricas e genéricos de grupo
Anteriormente falamos sobre as funções primitivas genéricas. Dissemos que eram funções escritas em linguagem C, não apresentavam as três composições básicas de uma função: formals(), body(), environment(), e que não apresentavam internamente a chamada UseMethod. Então, se o objeto inserido no primeiro argumento dessas funções não tiverem o atributo class (objeto base), o despacho para métodos não ocorrerá, isto é, as funções primitivas genéricas não usarão as classes implícitas. Isso porque, as funções que se comportam de modo diferente para diferentes tipos de objetos base, apresentam essa característica não porque formam um sistema POO, mas porque estas funções primitivas usam instruções da linguagem C do tipo switch. Nós temos a versão da função switch() em R, e foi comentada no módulo Básico. Vejamos a função primitiva genérica cbind(), como exemplo a seguir.
# Eh primitiva generica?
sloop::is_s3_generic("cbind")
[1] TRUE# Onde ocorre o despacho?
sloop::s3_dispatch(cbind(1:10))
cbind.integer
cbind.numeric
cbind.default
=> cbind (internal)Percebemos nesse caso, como o objeto 1:10 não apresenta o atributo class, a função interna foi a chamada, e nenhuma das classes implícitas são utilizadas. Nesse caso, apenas função primitiva/interna é utilizada.
No caso dos genéricos de grupo, sabemos que o nome dos grupos podem fazer parte da criação do método e o despacho de todos os genéricos serão realizados nesse método. Mas também, podemos criar métodos específicos para um determinado genérico de um grupo, sem influenciar no despacho dos demais genéricos. Nesses casos, os genéricos de grupo procurarão inicialmente pelos métodos relacionados as funções primitivas genéricas (fpgenerica.classe), e não achando, procurará pelos métodos relacioado aos nomes dos grupos (grupo.classe), não achando, despachará na função primitiva. Pode haver também o mecanismo de herança, por meio da chamada NextMethod(). Vejamos o código a seguir para o primeiro caso.
# Objeto de classe factor
x <- factor(1:5)
# Verificando o despacho de sqrt() do grupo 'Math'
sloop::s3_dispatch(sqrt(x))
sqrt.factor
sqrt.default
=> Math.factor
Math.default
* sqrt (internal)# Verificando o metodo Math.factor()
Math.factor
function (x, ...)
stop(gettextf("%s not meaningful for factors", sQuote(.Generic)))
<bytecode: 0x0000000041ce6e38>
<environment: namespace:base>Observamos nessa situação que o objeto do tipo factor, apesar de ser um resultado numérico, não se comporta como numérico. Nesse caso, calcular a raiz quadrado de cada elemento não será possível, ou qualquer outra operação do grupo 'Math', e assim, uma proteção para esse caso é assegurado logo no método Math.factor() (=>) com a chamada stop(). A ideia da função gettextf()2 no ambiente Ré similar a printf() para a linguagem C. No despacho, percebemos que existe a função primitiva (*) sqrt(), porém nesse caso, não foi utilizada.
Para os demais casos, podemos observar o código na sequência, para entendermos o que falamos anteriormente.
# Primeira situacao:
# ------------------
# Metodo de grupo
Summary.ben <- function(..., na.rm=FALSE) {
"Eu despacho em todo grupo 'Summary'"
}
# Objeto de classe 'ben'
x <- structure(TRUE, class = "ben")
# Despacho para funcao 'all'
sloop::s3_dispatch(all(x))
all.ben
all.default
=> Summary.ben
Summary.default
* all (internal)####################
# Segunda situacao:
# ------------------
# Metodo apenas para a funcao 'all'
all.ben <- function(..., na.rm=FALSE) {
"Eu despacho apenas para 'all.ben'"
}
# Metodo de grupo
Summary.ben <- function(..., na.rm=FALSE) {
NextMethod(.Generic)
}
# Objeto de classe 'ben'
x <- structure(TRUE, class = "ben")
# Despacho para funcao 'all'
sloop::s3_dispatch(all(x))
=> all.ben
all.default
* Summary.ben
Summary.default
* all (internal)###################
# Terceira situacao:
# ------------------
# Metodo apenas para a funcao 'all'
all.ben <- function(..., na.rm=FALSE) {
NextMethod(.Generic)
}
# Metodo de grupo
Summary.ben <- function(..., na.rm=FALSE) {
"Eu passei por 'all.ben', mas terminei em 'Summary.ben'"
}
# Objeto de classe 'ben'
x <- structure(TRUE, class = "ben")
# Despacho para funcao 'all'
sloop::s3_dispatch(all(x))
=> all.ben
all.default
-> Summary.ben
Summary.default
* all (internal)###################
# Quarta situacao:
# ------------------
# Metodo apenas para a funcao 'all'
all.ben <- function(..., na.rm=FALSE) {
NextMethod(.Generic)
}
# Metodo de grupo
Summary.ben <- function(..., na.rm=FALSE) {
NextMethod(.Generic)
}
# Objeto de classe 'ben'
x <- structure(TRUE, class = "ben")
# Despacho para funcao 'all'
sloop::s3_dispatch(all(x))
=> all.ben
all.default
-> Summary.ben
Summary.default
-> all (internal)A primeira situação o envio de método ocorre para Summary.ben() (=>), se verifica a função primita all() (*), porém não executada. Na segunda situação, observamos a existência do método Summary.ben() (*) e a função primitiva all() (*), porém o descpacho ocorre em all.ben() (=>). Na terceira situação, o despacho ocorre em all.ben() (=>), que intermanente chama NextMethod(), delegando para Summary.ben() (->). Por fim, na quarta situação o envio de método ocorre em all.ben() (=>) que delega para Summary.ben (->), que delega para a função primitiva all() (->).
Chamada NextMethod()
Vimos anteriormente que a chamada UseMethod() é responsável pelo envio de método, isto é, dado um objeto com um atributo class inserido no primeiro argumento do genérico, a chamada UseMethod() procurará pelo método específico dessa classe. Contudo, falamos anteriormente, que o atributo class pode ser um vetor de caracteres. Dessa forma é que entra a chamada NextMethod(). A ideia é aplicar o genérico para o próximo método. Já mostramos anteriormente essa semântica, e vamos reforçar com o código a seguir.
# Generico
fgenerica <- function(x) UseMethod("fgenerica")
# Metodo 1
fgenerica.clas1 <- function(x) {
print("Despache para o metodo 1")
NextMethod("fgenerica")
}
# Metodo 2
fgenerica.clas2 <- function(x) print("Despache para o metodo 2")
############
# Avaliacao:
# Objeto clas1 e clas2
fgenerica(structure(2, class = c("clas1", "clas2")))
[1] "Despache para o metodo 1"
[1] "Despache para o metodo 2"[1] "Despache para o metodo 2"# Despacho
sloop::s3_dispatch(fgenerica(structure(2, class = c("clas1", "clas2"))))
=> fgenerica.clas1
-> fgenerica.clas2
fgenerica.defaultO que caracteriza a chamada NextMethod() é a ocorrência do símbolo (->) na saída em sloop::s3_dispatch(). O que essa chamada de função faz é executar o próximo método.
De modo formal, apresentamos a sintaxe como NextMethod(generic, object, ...). Se nenhum argumento for adionado em NextMethod(), os argumentos serão os mesmos em quantidade, ordem e nome do método corrente, e por consequência também dos argumentos do genérico. Outra coisa interessante é que por meio de '...', podemos inserir mais argumentos para essa chamada, do qual todos os argumentos são anexados em uma lista como promessas, isto é, os argumentos não são avaliados. Porém se foram avaliados no ambiente atual ou no ambiente anterior, permanecerão avaliados. Vejamos alguns outros aspectos, dos quais alguns foram citados por Chambers and Hastie (1993):
- Os argumentos são transmitidos do método corrente para o método herdado com seus valores atuais no momento em que
NextMethod()é chamado; - Um objeto com mesmo nome de um dos argumentos (até mesmo o primeiro argumento) do método corrente, definido no ambiente de chamada de
NextMethod(), pode ser passado para o método herdado, sendo um valor diferente definido no argumento do método corrente. No caso da chamadaUseMethod(), é preservado o valor definido nos argumentos do genérico; - Alterar o primeiro argumento do genérico em uma chamada
NextMethod()afeta os argumentos recebidos no método herdado, mas não na escolha desse método. - A avaliação preguiçosa dos argumentos continuam. Se um argumento não foi avaliado, continua não avaliado;
- Argumentos ausentes permanecem ausentes no método herdado;
- Alguns objetos definidos no método atual, se informados em
NextMethod(), passarão para o método herdado, desde esse objeto seja um argumento do método herdado; - O ambiente de chamada de
NextMethod()não é encerrado após finalizado a chamado do método herdado, como ocorre comUseMethod(); - A chamada
NextMethod()é importante em algumas situações para evitar um loop infinito.
Apresentaremos a seguir, um código para exemplificar esses pontos. E um código seguinte será específico para o último ponto.
# Generico
fgenerica <- function(x, ...) UseMethod("fgenerica")
# Metodo 1
fgenerica.clas1 <- function(x, z = faux(), ...) {
x <- 3
y <- 5
NextMethod(generic = .Generic, object = x, y, z)
cat("Passei pelo metodo 1")
}
# Metodo 2
fgenerica.clas2 <- function(x, y, ...) {
cat("Chegando no metodo 2, consigo imprimir x:", x, "e y:", y, "\n")
cat("Existe classe em x? ", print(attr(x, "class")), "\n")
}
############
# Avaliacao:
# Chamada do generico com objeto de classe: clas1 e clas2
fgenerica(structure(2, class = c("clas1", "clas2")))
Chegando no metodo 2, consigo imprimir x: 3 e y: 5
NULL
Existe classe em x?
Passei pelo metodo 1Observemos no momento da chamada NextMethod() no método fgenerica.clas1() que o objeto do primeiro argumento x do genérico foi alterado [(1), (2) e (3)]. Inicialmente tinha o valor 2 com atributo class, porém no ambiente de execução do método fgenerica.clas1(), um objeto associado ao mesmo nome x <- 3 foi criado e passado para NextMethod(). Nesse caso, esse novo objeto não apresenta mais o atributo class (Observe a saída: Existe classe em x? NULL), e desse modo é repassado para o método herdado, porém observemos que o fato de não ter o atributo class não prejudicou nas escolhas dos métodos (3).
Ainda no método fgenerica.clas1() surge um argumento z que apresenta uma função faux() não existente, isso é a característica de avaliação preguiçosa dos argumentos por parte das funções (4), isso significa, que enquanto esse argumento não for chamado internamente, ele não será avaliado. E isso pode ser verificado, pois o genérico retorna o resultado esperado, sem mensagem de erros.
Um outro ponto importante é o objeto y definido no corpo do método fgenerica.clas1(), que não definido como seu argumento, mas sim como argumento na chamada NextMethod(), do qual pode ser repassada para o método herdado (6). Isso foi possível também porque y também entrou como argumento para o método fgenerica.clas2().
Diferentemente de UseMethod(), a chamada NextMethod() não encerra o ambiente de chamada (7). Isso pode ser verificado com o resultado do genérico imprimindo Passei pelo metodo 1, isto é, o genérico despacha em fgenerica.clas1() que herda o método fgenerica.clas2(), por meio de NextMethod(). Após o fechamento de fgenerica.clas2() e posteriormente da chamada NextMethod(), o ambiente de execução de fgenerica.clas1() continua a executar as suas instruções, do qual segue com a execução de cat("Passei pelo metodo 1"), e posteriormente ocorre o seu fechamento.
Por fim, a justificativa do último ponto, vamos apresentar uma aplicação muito importante que ocorre com a função primitiva genérica [. Por exemplo, se tivermos um vetor associado ao nome x com um atributo class e desejarmos o segundo elemento, isto é, x[2]. Este resultado não preserva a classe de x. Para isto, precisamos criar um método para esse genérico, apresentado a seguir.
# Criando um objeto de classe 'cpf'
new_cpf <- function(x) {
structure(x, class = "cpf")
}
# Metodo print para 'cpf'
print.cpf <- function(x, ...) {
x <- as.character(x)
substr(x, 3, 9) <- "*******"
print(x)
}
# Criando e imprimindo x
x <- new_cpf(c(12345678912,
78945612323,
98765432112)); x
[1] "12*******12" "78*******23" "98*******12"# Selecionando o segundo cpf
x[2]
[1] 78945612323Observamos nesse exemplo que a função primitiva [ é um genérico mas que não tem o método para classe cpf, e por isso retorno o valor do cpf na íntegra, algo que não queríamos como resultado. Nesse caso, precisamos criar um método para tal, sendo apresentado três soluções a seguir.
# Primeira solucao (menos eficiente pq cria copia de x)
`[.cpf` <- function(x, i) {
x <- unclass(x)
new_cpf(x[i])
}
x[2]
[1] "78*******23"# Segunda solucao
`[.cpf` <- function(x, i) {
class(x) <- NULL
new_cpf(x[i])
}
x[2]
[1] "78*******23"# Terceira solucao
`[.cpf` <- function(x, i) {
new_cpf(NextMethod())
}
x[2]
[1] "78*******23"# Quarta solucao: Loop infinito
`[.cpf` <- function(x, i) {
new_cpf(x[i])
}
x[2]
Error: avaliação aninhada demais; recursão infinita / options(expressions=)?Uma primeira tentativa, resolve o problema, porém perdemos eficiência por fazer uma cópia do objeto x. A segunda e terceira tentativas, são mais eficientes, sendo que a última usa a chamada NextMethod(). Essa chamada procura pelo próximo método que é a própria função primitiva, que ao ser executada retorna o resultado, e este entra como um argumento da função new_cpf(). Então, o ocorre a chamada new_cpf() que retorna novamente um objeto de classe cpf. Por fim, a quarta tentativa gera um loop infinito, porque ao criar o método [.cpf(), percebemos que internamente usamos a função primitiva genérica [, e como o objeto x tem o atributo class igual a cpf, este procurará novamente o método, e assim por diante.
Na sequência, veremos em detalhes o mecanismo de herança de modo como o UseMethod() despacha para um determinado método, como também a chamada NextMethod() é usada para a busca do método herdado.
Mecanismo de herança
O mecanismo de herança ocorre de acordo com os elementos do vetor de atributo class pela função genérica. Esse vetor pode ter qualquer comprimento. Além desses elementos, temos ainda uma pseudoclasse chamada default que não aparece no atributo class. O genérico procurará inicialmente pelo método para o primeiro elemento do vetor do atributo class, se o método para essa classe não existir, procurará pelo método observando pelo segundo elemento, e assim por diante. Caso o genérico percorra por todo o vetor, e não encontre o método para a classe desejada, o despacho ocorre no método default. E por fim, se este método não existir, o genérico retornará uma mensagem de erro erro.
O mecanismo de herança, ocorre por meio da chamada NextMethod(). Vejamos o código a seguir.
# Construtor
new_intparord <- function(x, ..., inteiro = FALSE, ordenado = FALSE) {
stopifnot(is.numeric(x))
classe = c("par", "ordenado", "inteiro")
if (inteiro) {
classe <- c("inteiro")
}
if (ordenado) {
classe = c("ordenado", "inteiro")
}
structure(x, class = classe)
}
# Método inteiro para o generico print
print.par <- function(x, ...) {
NextMethod(.Generic, x = x[!as.logical(trunc(x) %% 2)])
}
# Método ordenado para o generico print
print.ordenado <- function(x, ...) {
NextMethod(.Generic, x = sort(x))
}
# Método inteiro para o generico print
print.inteiro <- function(x, ...) {
attributes(x) <- NULL
print(as.integer(x))
invisible(x)
}
x <- new_intparord(x = 10:1); x
[1] 2 4 6 8 10attributes(x)
$class
[1] "par" "ordenado" "inteiro" Criamos uma função chamada de new_intparord, que é um construtor de instâncias de uma classe. Essa estratégia é importante principalmente quando temos classes com características mais complexas. O objeto criado desse construtor tem um atributo class de comprimento até de três classes: "par", "ordenado" e "inteiro". Isto é, a classe mais geral é "inteiro" e a chamamos no contexto de POO de superclasse, uma vez que é uma classe que abrange características mais gerais. Essa classe representa os números inteiros. A próxima classe é "ordenada", que é uma organização dos números inteiros. Essa classe herda de "inteiro" a característica de que além de ordenado, esses elementos devem ser número inteiros. Essa herança ocorre por meio de NextMethod(). Por fim, a classe "par" que representa apenas os números pares, mas também, herda a sua ordenação da classe "ordenado", que por sua vez, herda a condição dos número serem inteiros da classe "inteiro". Nessa situação, fica claro que "par" é uma subclasse de "inteiro", uma vez que representa um grupo mais restrito da classe mais abrangente. De um modo geral, dizemos que uma subclasse são as classes mais à esqueda no atributo class e a superclasse mais à direita.
Esse exemplo nos mostra a importância da chamada NextMethod() para o mecanismo de herança. Mais ainda, a rigor o sistema S3 não impõe restrições nenhuma entre subclasses e superclasses. Porém, o desenvolver deve pensar nesse aspecto, uma vez que em termos práticos, a construção das ideias se tornam mais fáceis na criação de suas rotinas. Não estamos falando necessariamente que a implementação de subclasses e superclasses seja algo fácil. Para contextualizar, percebamos que o objeto x do código anterior, desejássemo a impressão do segundo elemento, usaríamos x[2]. Retornaríamos o valor correto, porém a sua classe não seria presevada. Por quê? Porque a função primitiva genérica [ não tem esses métodos implementados, isto é, [.par, [.ordenado e [.inteiro. Assim, também vale a aplicação do objeto x para os demais genéricos. Vejamos em código o que acabamos de falar.
[1] "par" "ordenado" "inteiro" [1] 9[1] "integer"Cada subclasse que for inserida no objeto x irá exigir sempre mais trabalho para que o desenvolve, porque necessita garantir teoricamente a herança.
Entendendo um pouco mais sobre objetos
Depois de termos abordado a ideia de objetos no sentido de programação orientada a objetos, retornamos a ideia inicial abordada no módulo básico, do tipo do objeto no sentido da forma de como seus valores são organizados. Afirmamos que tínhamos a estrutura mais de objeto é um vetor, conhecidos como estruturas atômicas pois os seus valores são de mesmo modo (character, logical, numeric, complex e raw). Falamos também dos objetos do tipo lista, que armazenam outros objetos que podem ter modos diferentes.
Estruturas atômicas e recursivas
A ideia de estrutura atômica ficou bem claro. Temos agora uma outra ideia que é a estrutura recursiva, que representa a condição dos objetos conterem elementos de sua própria estrutura. Por exemplo, uma lista pode ter um objeto que é uma lista, uma função também é uma estrutura recursiva, porque seus argumentos podem ser uma função, e assim por diante.
Para sabermos se um objeto é atômico ou recursivo, usamos as funções respectivamente, is.atomic() e is.recursive(). Assim, vejamos o código a seguir.
# Funcao auxiliar
eh_atom_ou_recur <- function(x) c(atomico = is.atomic(x), recursivo = is.recursive(x))
# Testando alguns objetos
eh_atom_ou_recur(c(a = 1, d = 3)) # TRUE FALSE
atomico recursivo
TRUE FALSE eh_atom_ou_recur(list()) # FALSE TRUE
atomico recursivo
FALSE TRUE eh_atom_ou_recur(list(2)) # FALSE TRUE
atomico recursivo
FALSE TRUE eh_atom_ou_recur(mean) # FALSE TRUE
atomico recursivo
FALSE TRUE eh_atom_ou_recur(y ~ x) # FALSE TRUE
atomico recursivo
FALSE TRUE eh_atom_ou_recur(expression(x^2 + 2)) # FALSE TRUE
atomico recursivo
FALSE TRUE eh_atom_ou_recur(quote(sqrt)) # FALSE FALSE
atomico recursivo
FALSE FALSE Na última execução, percebemos que a função quote, apesar de função ela é primitiva. Nesse caso, esse objeto fugirá a regra de atomicidade e recursividade, porque em seu único argumento expr, tudo que for inserido nele será uma expressão, e não será avaliado. O resultado de quote(), apesar de mode() retornar call ou name, este último quando remos uma constante, o seu resultado pode ser qualquer tipo.
Por que uma lista é uma lista, por exemplo? Podemos escrever uma lista da seguinte forma:
Um outro caso é o objeto função. Podemos escrever uma função dentro de outra função, isto é,
fun1 <- function(x) {
fun2 <- function(y) x + y
fun2(x)
}
fun1(2)
[1] 4A maioria dos objetos R são recursivos, exceções para os atômicos, NULL, objetos tipo "symbols", objetos "S4", objetos "externalptr", objetos "bytecode" e "weakref". Esses últimos raramente vísiveis ao usuário.
Usando vector(), is.vector() e as.vector()
Apesar de conhecermos vetores como vetores atômicos, observemos que um objeto pode ser atômico mas não um vetor. Observemos o código a seguir.
A criação de vetores pode ser denvolvida pela função vector(mode, length), cujos argumentos são mode tipagem de acordo com a linguagem S ("logical", "numeric", "complex", "character" e "raw"). O argumento mode permite também "integer" e "double" de acordo com a tipagem da linguagem C. O argumento length representa o comprimento do vetor. Desse modo, criando um vetor de modo "logical" e de comprimento 5, temos:
vector(mode = "logical", length = 5)
[1] FALSE FALSE FALSE FALSE FALSEA identificação de um vetor é realizada por is.vector(), resultando em TRUE para um objeto tipo vetor, e FALSE, caso contrário. A afirmação anterior de que um objeto pode ser atômico mas não um vetor, ocorre porque quando usamos atributos aos vetores, exceto nomes, o retorno de is.vector() é FALSE. Vejamos o próximo código para essa confirmação.
[1] TRUE[1] FALSE [1] 1 2 3 4 5 6 7 8 9 10Como esperado, is.vector(x) retorna FALSE por causa do atributo atrib1. Porém, quando coagimos x a um vetor, usando as.vector(), esse novo objeto retorna os valores sem seus atributos. A exceção ocorre apenas para o atributo name, isto é,
x <- c(arg1 = 1, arg2 = 2); x; attributes(x)
arg1 arg2
1 2 $names
[1] "arg1" "arg2"[1] TRUE[1] TRUESempre nos confundimos quando desejamos verificar a tipagem do vetor usando typeof() ou mode(), que já mencionamos também que o primeiro se relaciona com a tipagem C e o segundo com a tipagem S. Desse modo, a condição de equivalência ocorre, apesar de nomes diferentes entre algumas tipagens das linguagens, isto é,
# Objeto tipo 'integer' e 'numeric'
x <- 1L
# Vericando
is.vector(x, mode = "numeric")
[1] TRUEis.vector(x, mode = "integer")
[1] TRUEtypeof(x)
[1] "integer"mode(x)
[1] "numeric"Vimos na seção objetos base os tipos de objeto baseados na tipagem C. Os objetos tipo "integer" e "double" são equivalentes a "numeric" para a linguagem S, assim como o objeto "symbol" tem seu equivalente "name". Isso significa, que também poderemos usar is.vector() e as.vector() para saber se os objetos são desses tipos ou coagi-los, respectivamente, sendo monstrado exemplos a seguir.
# Criando um objeto "symbol" ou "name"
x <- as.vector(1, mode = "symbol")
# Verificando
is.vector(x, mode = "symbol")
[1] TRUEis.vector(x, mode = "name")
[1] TRUE# Criando um objeto "pairlist"
fxy <- function(x, y) c(x, y)
argumentos <- formals(fxy)
# Verificando
is.vector(argumentos, mode = "pairlist")
[1] TRUESe mode = any representa um objeto do tipo any, isto é, pode ser qualquer um dos tipos "character", "integer", "double", "numeric", "complex", "raw", "list" ou "expression". Desse modo, a função is.vector() retornará TRUE para todos esses tipos de objetos, porém quando usado a função mode() ou typeof(), esta retornará os seus tipos de origem e não "any", vejamos o código seguinte.
# Criando um objeto "any"
x <- as.vector(1, mode = "any")
# Verificando o tipo
is.vector(x, mode = "any")
[1] TRUEis.vector(x, mode = "numeric")
[1] TRUEmode(x)
[1] "numeric"typeof(x)
[1] "double"Por fim, se o argumento mode em is.vector for um tipo desconhecido, então o retorno será FALSE, ao invés de mensagem de erro.
Conhecendo outros objetos
No módulo básico, discutimos sobre alguns objetos que não demos detalhes adicionais ou não foram comentados.
Objeto para datas, horas, tempo, durações e fusos horários
O tempo intrínseco ao nosso dia a dia, e muitas vezes passamos despercebido em muitos aspectos. Vejamos, devido ao ano bissexto, alguns anos não têm 365 dias, nem 24 horas para um dia, muito menos 60 segundo para um minuto. Devido aos fenômenos de rotação e translação da terra, essas variáveis passam por alguns ajustes. Dessa forma, podemos perceber a complexidade de trabalhar com esses tipos de dados. Vamos aqui apresentar o básico para objetos que armazenam essas informações.
Datas
O objeto que armazena esses tipos de dados são vetores tipo "double", com classe Date, e portanto, um objeto POO do sistema S3. Para sabermos a data de hoje, usamos a função Sys.time(), isto é,
[1] "double"# Eh um vetor?
is.vector(hoje)
[1] FALSE# Eh 'double'?
is.vector(hoje, mode = "double")
[1] FALSE# Qual a sua classe?
class(hoje)
[1] "Date"Calma que as execuções para is.vector() retornaram FALSE, devido o atributo class. Se excluirmos verificaremos a sua confirmação, apresentado a seguir.
Quando retornamos a classe implícita desse objeto, recebemos o seguinte resultado:
unclass(hoje)
[1] 18940O resultado 18940 coagido a double se refere ao número de dias desde a data “1970-01-01.” Essa data é em homenagem ao marco zero do sistema de calendário utilizado pelo sistema UNIX.
Podemos criar um objeto data com o construtor (gerador de instâncias de classe) chamado .Date(). O argumento de entrada será o número de dias após o marco “1970-01-01,” isto é,
# O marco zero
.Date(0)
[1] "1970-01-01"# Um dia apos o marco
.Date(1)
[1] "1970-01-02"# Dez dias apos o marco
.Date(10)
[1] "1970-01-11"A função de coerção para um objeto data é uma função genérica para as classes implícitas "character" e "numeric", e para as classes "POSIXct", e para mais detalhes da função, use ?as.Data(). Vejamos alguns exemplos a seguir.
# Objeto x tipo "character"
x <- "2017-08-02"
(data <- as.Date(x))
[1] "2017-08-02"class(data)
[1] "Date"# Objeto x tipo "numeric"
x <- 10
# Com o objeto numerico, precisamos informar
# a data inicial no argumento 'origin'. Nesse
# caso, o retorno sera a data x dias apos
# 'origin'
#
(data <- as.Date(x, origin = "2017-08-02"))
[1] "2017-08-12"# Objeto de classe 'POSIXct'
x <- as.POSIXct("2018-08-02 5:30")
(data <- as.Date(x))
[1] "2018-08-02"class(data)
[1] "Date"Explicaremos posteriormente os objetos da classe "POSIXct". Podemos alterar o formato tanto da data como também da hora, que falaremos mais a frente, por meio da função format(), cuja sintaxe geral para essa função é dada por:
format(x, format, ...),em que x é o argumento que recebe um valor de data, e o argumento format é o argumento para informarmos o formato de apresentar essa data. O default é o formato "%Y-%m-%d. Porém, já vamos adiantar algumas siglas importantes na Tabela 1, para a formatação das datas.
| Sigla | Significado | Sigla | Significado |
|---|---|---|---|
%Y |
Todos os dígitos do ano | %y |
Os dois últimos dígitos do ano |
%C |
Século (00-99) | %c |
Data e hora específico do local, formado "%a %b %e %H:%M:%S %Y" |
%B |
Mês completo (Texto) | %b ou %h |
Mês abreviado (Texto) |
%m |
Mês (Número) | %j |
Número de dias no ano |
%A |
Dia da semana completa | %a |
Dia da semana abreviada |
%D |
Data completa no formato %m/%d/%y, padrão C99 |
%d |
Dia do mês |
%H |
Horas (24 horas) | %l |
Horas (12 horas) |
%M |
Minutos | %S |
Segundos |
%p |
inserção para as horas AM/PM | ||
%w |
Dia da semana (texto) | %W |
Número da semana no ano () |
%x |
Data específica de acordo com Sys.setlocale() |
%X |
Horário especificado de acordo com Sys.setlocale() |
%z |
Compensação em relação ao horário de Greenwich (GMT) |
%Z |
Fuso horário |
Mais detalhes dessas siglas, ?strptime(). Vejamos alguns exemplos no código a seguir.
Para os objetos de classe "Date", as siglas utilizadas para a função format() devem estar relacionadas a data, isto é, dia, mês e ano. Lembrando que o resultado desse genérico, bem como de as.character(), retornam vetores de tipo caractere, sem a classe "Date".
Algumas funções genéricas estão prontas para serem utilizados nesses objetos, como +, -, seq(), rep(), etc. Para saber mais quais métodos para essa classe, use methods(class = "Date").
Datas, horas e fusos horários
Se observarmos os métodos disponíveis para o genérico as.Date(), usando methods(as.Date), direto ou indiretamente, internamente ao código há uma chamada as.POSIXlt() ou as.POSIXct(). Nesse caso, nas base do R a forma de armazenar a data e hora segue uma família de padrões especificados pela IEEE Computer Society chamado POSIX (do inglês, Portable Operating System Interface). O objetivo é manter um padrão para que haja uma compatibilidade entre os sistemas operacionais. Assim, os objetos contrutores para armazernar além das datas também as horas são respectivamente, .POSIXct() e .POSIXlt(). O primeiro se refere a data e hora do calendário (ct - calendar time), e o segundo a data e hora local (lt - local time).
O construtor .POSIXct() é um vetor tipo double, em que seu primeiro argumento de entrada representa o número de segundos desde “1970-01-01.” Assim, esse construtor gera uma instância para as classes "POSIXct" e "POSIXt", que podemos observar a seguir.
# Marco zero
(mzero <- .POSIXct(0))
[1] "1969-12-31 21:00:00 -03"# Classe
class(mzero)
[1] "POSIXct" "POSIXt" Percebemos que o resultado mzero não representa a data “1970-01-01.” Quando investigamos a função .POSIXct(), percebemos que um dos argumentos é tz que representa o fuso horário. Por default tz = NULL, e nesse caso será buscado o fuso horário do calendário do sistema operacional. Vejamos,
# Marco zero, baseado no calendario SO
.POSIXct(0)
[1] "1969-12-31 21:00:00 -03"# Marco zero, fuso Horario de Greenwich (GMT) ou Tempo Universal Coordenado (UTC)
.POSIXct(0, tz = "GMT")
[1] "1970-01-01 GMT".POSIXct(0, tz = "UTC")
[1] "1970-01-01 UTC"Nesse caso, o resultado da chamada .POSIXct(0), foi executado de um sistema operacional (SO) com fuso horário no Brasil, horário de Brasília, com fuso -3GMT em relação ao fuso horário UTC ou GMT (do inglês, Greenwich Mean Time e Coordinated Universal Time, respectivamente), que representa o fuso horário de Greenwich e o Tempo Universal Coordenado, respectivamente. Para se alterar o fuso horário, o argumento tz deve ser usado. Para saber, acesse a lista de fusos horários chamando OlsonNames().
A coersão para um objeto POSIXct, a função usada é as.POSIXct(), que pode coagir a partir de vetores caracteres e numéricos. Seguem as mesmas ideias que comentamos para as.Date(), porém agora acrescentamos as horas. O fuso horário pode ser captado pelo calendário do sistema operacional, ou pode ser inserido.
# Objeto caractere
x <- "2021-09-02 22:46:30"
data_hora1 <- as.POSIXct(x)
class(data_hora1)
[1] "POSIXct" "POSIXt" # Objeto numerico
data_hora2 <- as.POSIXct(100, origin = "1955-09-13")
class(data_hora2)
[1] "POSIXct" "POSIXt" A saída padrão é "%Y-%m-%d %H:%M:%S", seguido do fuso horário. Essa configuração é realizada pelo genérico format que despacha para o método apropriado.
O outro contrutor é algo mais complicado de se trabalhar, porque ao invés de um vetor double, é uma lista com no mínimo 9 componentes que segue:
| Componente | Descrição |
|---|---|
sec |
Segundos |
min |
Minutos |
hour |
Horas |
mon |
Mês |
zone |
Fuso horário |
wday |
Dias da semana |
mday |
Dias do mês |
year |
Anos desde “1899-12-31.” |
isdst |
O fuso horário é utilizado para configurar o isdst, que representa o horário de verão |
gmtoff |
Deslocamento em segundos do horário de Greenwich (GMT) |
Os dois últimos componenente basicamente é o fuso horário que configura. O construtor é .POSIXlt(), e de forma mais direta, podemos usar stiptime() para converter vetores caracteres nesse classe. A classe desse objeto é "POSIXlt" e POSIXt
Vejamos alguns exemplos para criação desse objeto, com o código a seguir.
# Marco zero
xx <- list(sec = 0, min = 0, hour = 0, mday = 0,
mon = 0, year = 0, wday = 0, yday = 0,
isdst = 0, zone = "America/Sao_Paulo", gmtoff = "")
tempo1 <- .POSIXlt(xx)
class(tempo1)
[1] "POSIXlt" "POSIXt" # Objeto caractere -> POSIXlt
tempo2 <- strptime("2021-09-02 03:21 am UTC", "%Y-%m-%d"); tempo2; unlist(tempo2)
[1] "2021-09-02 -03" sec min hour mday mon year wday yday isdst zone
"0" "0" "0" "2" "8" "121" "4" "244" "0" "-03"
gmtoff
NA class(tempo2)
[1] "POSIXlt" "POSIXt" Muitas outras funções podem ser utilizadas para manipulação de datas, mas deixaremos para o leitor em realizar as suas consultas adicionais: striftime(), Sys.setlocale(), Sys.getlocale(), .difftime(), as.difftime(), Sys.timezone(), Sys.time(), etc.
Tanto para datas, horas e fusos horários existem pacotes alternativos que podem facilitar a utilização desses tipos de dados, como por exemplo o pacote lubridate.
Cópia ao modificar, modificação no local e tamanho de objetos
Muitos dos problemas de perda de desempenho do código R pode estar envolvido a essa seção. Já abordamos no módulo básico de modo superficial, e agora iremos aprofundar um pouco mais. Outro assunto importante dentro do paradigma da programação funcional, que é a imutabilidade. Veremos que em algumas situações os objetos podem ser mutáveis, e com isso podemos afirmar a linguagem R não é estritamente funcional. Por fim, iremos perceber um grande equívoco que ocorre entre os programadores R quando cria um objeto associado ao nome x, afirma que criou um objeto x cujo valor está dentro dele. Perceberemos que na verdade, temos dois objetos envolvidos, e o que faz retornar o valor associado ao nome x é o ambiente onde esses objetos foram criados, de modo que, poderemos associar mais de um nome ao mesmo objeto.
Sugerimos que quando buscarmos pelo identificador de memória de onde os objetos foram alocados na memória ativa do seu sistema operacional, seja usado o interpretador do R ao invés do RStudio, porque a IDE faz uma referência a cada objeto para exibir informações sobre ele.
Quando falamos dos tipos de objeto base, mencionamos os 24 tipos de objetos que existem no ambiente R. Vejamos o código a seguir.
x <- 10Falamos também que o objeto nome é do tipo symbol, como no caso de x, e o objeto 10 é um vetor numérico tipo integer de comprimento 1. Ao criar esse objeto, a forma de recuperá-lo é associar um nome a ele, uma vez que o ambiente R não tem uma forma de recuperar o valor do objeto pelo identificador de memória onde ele foi reservado, pelo menos ainda limitados a compreensão de existência. As ligações desses objetos ficam armazenados como uma lista em um outro objeto, o ambiente. Nesse caso, essa ligação foi armazenada no ambiente global, .GlobalEnv. Na Figura 2, mostramos em detalhes essas ligações.
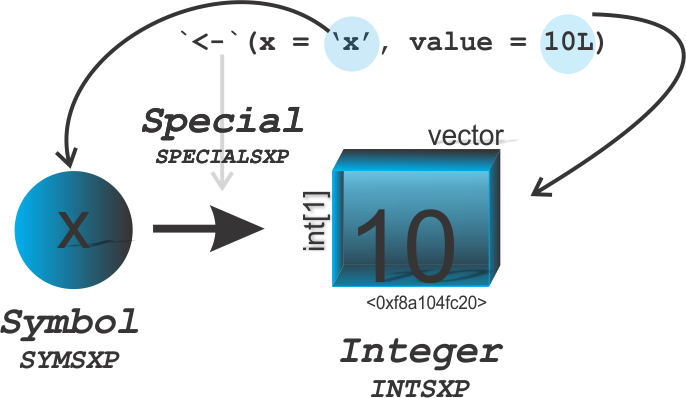
Figure 2: Ligações entre objetos tipo 'symbol' e 'integer'.
Diante disso, o que vem a ser a cópia de um objeto, nada mais é do que alocar um outro espaço de memória para armazenar o(s) valor(es) do objeto copiado. Isso significa, mais espaço de memória ativa. Há de se observar que o consumo de memória pelo R é um dos gargalos do ambiente, mas ao longo do tempo vem evoluindo bastante. Porém, muitas vezes é o mau uso na escrita das rotians desenvolvida pelos usuários que gera essas intempéries. Então, vamos lá para uma série de exemplos.
# Exemplo 1
a <- b <- d <- 6
# identificador de memoria
lobstr::obj_addr(a)
[1] "0x2767abe0"lobstr::obj_addr(b)
[1] "0x2767abe0"lobstr::obj_addr(d)
[1] "0x2767abe0"Lembrando no módulo básico, que os identificadores de memória sempre se alteram, à medida que reiniciamos. Porém, percebam que ao chamar o objeto associado a esses nomes, todos retornam o valor 6. Ainda mais, o identificador de memória é o mesmo. Portanto, aqui fica claro que não está havendo cópia do objeto, e sim, mais nomes se associando ao mesmo objeto, observemos a Figura 3, é o que chamamos de vinculação compartilhada.
Figure 3: Ligações de nomes associados ao objeto numérico.
Vamos agora apresentar um próximo código, para entendermos a definição de cópia ao modificar.
# Vetor caractere ligado a dois nomes
x <- y <- c("a", "b", "c"); y; x
[1] "a" "b" "c"[1] "a" "b" "c"[1] "0x24565128"[1] "0x24565128"# Copia ao modificar
x[1] <- "f"
# Ident de mem do obj associado aos nomes apos a modificacao
lobstr::obj_addr(y); lobstr::obj_addr(x)
[1] "0x24565128"[1] "0x2c3f8ea0"# Imprimindo novamente os objetos
y; x
[1] "a" "b" "c"[1] "f" "b" "c"Percebam que criamos um vetor caractere de comprimento 3, e vinculamos a dois nomes, x e y. Posteriormente, alteramos o primeiro elemento do vetor x, mas isso não modificou o vetor y. O que aconteceu? O ambiente R preservou o objeto y, e fez uma cópia de 0x24565128 para 0x2c3f8ea0, com o valor alterado, e religou o nome x a esse objeto, Figura 4. Portanto, fazer uma cópia representa realocar um outro espaço de memória para armazenar os valores desse objeto, e assim, um outro identificador de memória será apresentado, diferente do objeto copiado.
Figure 4: Cópia de objetos.
A função tracemem() do pocote base, pode auxiliar na verificação de cópias de objetos. Após a vinculação de um nome a um objeto, essa função pode ser acionada, e após as alterações de valores do objeto, se houver cópia, uma mensagem é impressa no console informando a referida cópia. Vejamos no código a seguir.
# Vetor numerico de comprimento 3
w <- rnorm(3); w
[1] 0.8546449 1.1350022 -0.3083730<0000000026CA4748> # Vinculacao de outro nome e copia
z <- w; z[2] <- 10
tracemem[0x0000000026ca4748 -> 0x00000000423ad298]: eval eval withVisible withCallingHandlers handle timing_fn evaluate_call <Anonymous> evaluate in_dir eng_r block_exec call_block process_group.block process_group withCallingHandlers process_file <Anonymous> <Anonymous> withCallingHandlers suppressMessages render_one FUN lapply sapply <Anonymous> <Anonymous> <Anonymous> # Desativando o rastreamento
untracemem(w)
# Modificando novamente o obj z
z[1] <- 100; z
[1] 100.000000 10.000000 -0.308373# Identificador de memoria
lobstr::obj_addr(z)
[1] "0x423ad298"Após vinculado o nome w ao vetor numerico de comprimento 3, que é um gerador de números aleatórios de uma distribuição normal padrão, acionamos a chamada tracemem(), e após a criação de cópias, a função mostrará a ocorrência dessas cópias. Se desejarmos que essa mensagem não seja mais acionada, devemos usar a chamada untracemem(), que desativará o rastreameto de cópia. Lembrando que o rastreamento só ocorrerá o objeto informado na função tracemem(). Por fim, fizemos mais uma alteração no objeto z, e nesse caso como o objeto se associa apenas a um nome, ocorre a modificação no local, um processo de otimização do R, em que usa a mesma alocação de memória, não havendo portanto, uma cópia de objeto.
Mas, fazendo alguns estudos e pesquisas, encontramos algumas funções primitivas, acessadas pela chamada .Internals(), denominada inspect(), address() e refcnt(), funções experimentais para imprimir informações de baixo nível dos objetos R. Essa função não é exposta ao nível superior da linguagem, e segundo a própria documentação, é um recurso para depuração/inpeção. A documentação ainda afirma que nem todas as informações foram implementadas. Para esse momento, o que está implementado é suficiente para identificarmos os procedimentos de cópia dos objetos. Uma segunda informação é que a partir da versão R 4.0.0, a decisão de cópia de objetos passaram a ser determinados pela contagem de referência, ao invés do mecanismo NAMED. Esse ponto realmente exige um entendimento de baixo nível na linguagem, isto é, a sua implementação em linguagem C. Vamos mostrar os resultados do código anterior, inspecionado por essas funções, a seguir.
# Vetor numerico de comprimento 3
w <- rnorm(3); w
## [1] 0.2733585 -0.6819105 -0.1788905
# inspecionando em baixo nivel o objeto w
.Internal(inspect(w)); .Internal(address(w)); .Internal(refcnt(w))
## @0x000000000a046838 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 0.273359,-0.68191,-0.17889
## <pointer: 0x000000000a046838
## [1] 1
# Vinculacao de outro nome e copia
z <- w
# inspecionando em baixo nivel o objeto z
.Internal(inspect(z)); .Internal(address(z)); .Internal(refcnt(z))
## @0x000000000a046838 14 REALSXP g0c3 [REF(2)] (len=3, tl=0) 0.273359,-0.68191,-0.17889
## <pointer: 0x000000000a046838>
## [1] 2
# Alterando z
z[2] <- 10
# inspecionando em baixo nivel o objeto z
.Internal(inspect(z)); .Internal(address(z)); .Internal(refcnt(z))
## @0x000000000a046518 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 0.273359,10,-0.17889
## <pointer: 0x000000000a046518>
## [1] 1
# Modificando novamente o obj z
z[1] <- 100; z
## [1] 100.0000000 10.0000000 -0.1788905
# inspecionando em baixo nivel o objeto z
.Internal(inspect(z)); .Internal(address(z)); .Internal(refcnt(z))
## @0x000000000a046518 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 100,10,-0.17889
## <pointer: 0x000000000a046518>
## [1] 1
A função inspect() será melhor explorada no módulo avançado. O que vamos precisar de sua saída é a estrutura REF(#), que representa a contagem de referência, isto é, o símbolo # determina o número de nomes associados ao objeto inspecionado. Se # = 1, não ocorrerá cópia de objeto, e sim, uma modificação no local. Se # > 1, certamente ocorrerá uma cópia de objeto. Observemos que inicialmente, o objeto associado a z é inspecionado com REF(1), cujo número pode ser obtido também por .Internal(refcnt(w)). A chamada .Internal(address(w)) informa o identificador de memória, o mesmo obtido por lobstr::obj_addr(w) ou tracemem(w), este último com pequenas alterações. Na sequência, associamos um outro nome z ao objeto. Agora, observamos que a contagem de referência agora é REF(2). Dessa forma, qualquer alteração nos valores de w ou z, haverá cópia de objeto. E isso acaba ocorrendo quando executamos z[2] <- 10, verificando que o identificador de memória de z se alterou. Um outro fato muito importante surge nesse momento. A alteração do objeto foi realizada por uma função primitiva, e funções primitivas, geralmente, têm um melhor controle da contagem de referência, e nesse caso, percebemos que o novo objeto associado a z só existe esse nome, e portanto, a contagem de referência retorna a 1, isto é, REF(1). Por fim, alteramos novamente o objeto associado a z, porém a modificação ocorre no local, porque REF(1).
Uma outra consequência de cópia de objeto é a coersão. Vejamos o código na sequência para ilustrar.
# Vetor inteiro de comprimento 10
x <- integer(10)
# Inspecionando x
.Internal(inspect(x))
## @0x00000000066297e0 13 INTSXP g0c4 [REF(1)] (len=10, tl=0) 0,0,0,0,0,...
# Alterando x com um escalar tipo 'double'
x[1] <- 10 # 10 eh 'double', 10L seria 'integer'
# Inspecionando x
.Internal(inspect(x))
## @0x0000000008dfcf88 14 REALSXP g0c5 [REF(1)] (len=10, tl=0) 10,0,0,0,0,...
Falamos anteriormente que, geralmente, as funções primitivas têm um controle melhor da contagem de referência para decidir se um objeto será copiado ou não. Mas, nem todas. Vejamos o código a seguir.
@0x000000004155dee8 14 REALSXP g0c4 [REF(2)] (len=5, tl=0) 1,2,3,4,5## @0x0000000006629620 14 REALSXP g0c4 [REF(1)] (len=5, tl=0) 1,2,3,4,5
# Funcao primitiva `:` - REF(65535)
b <- 1:10
# inspecao de b
.Internal(inspect(b))
@0x0000000043b96328 13 INTSXP g0c0 [REF(65535)] 1 : 10 (compact)## @0x000000000a060680 13 INTSXP g0c0 [REF(65535)] 1 : 10 (compact)
# Funcao primitiva seq() - REF(65535)
b <- seq(1L, 10L)
# inspecao de b
.Internal(inspect(b))
@0x0000000043c41260 13 INTSXP g0c0 [REF(65535)] 1 : 10 (compact)## @0x000000000a05f3e8 13 INTSXP g0c0 [REF(65535)] 1 : 10 (compact)
# Funcao primitiva rep() - REF(1)
b <- rep(1:10, 1)
# Inspecao de b
.Internal(inspect(b))
@0x0000000041551bc0 13 INTSXP g0c4 [REF(2)] (len=10, tl=0) 1,2,3,4,5,...## @0x00000000066295b0 13 INTSXP g0c4 [REF(1)] (len=10, tl=0) 1,2,3,4,5,...
Observemos que algumas funções são muito úteis para a implementação de nossas rotinas, porém estas geram cópias de objetos com a alteração de seus valores, ao invés de modificação no local. Por exemplo, as funções : e seq() são muito úteis para gerarmos uma sequência de valores espaçados igualmente, porém, observamos que suas contagens de referências são diferentes de 1. Isso significa que qualques alteração nos valores do objeto, criado por essas funções, geram cópias. Dependendo da implementação em um loop, por exemplo, o dispêndio de memória ativa pode ser muito alto, e por consequência, perda de desempenho.
No caso de funções tipo closure, isto é, criadas por function(), ocorre algo similar com a discussão anterior, porém, com algumas diferenças, vejamos o próximo código.
f1 <- function(x) {
print(.Internal(inspect(x)))
x
}
f2 <- function(x) {
print(.Internal(inspect(x)))
x[1] <- 10
print(.Internal(inspect(x)))
x
}
# Caso 1
a <- c(1, 2, 3)
.Internal(inspect(a))
## @0x000000000a426578 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 1,2,3
k1 <- f1(a)
## @0x000000000a426578 14 REALSXP g0c3 [REF(2)] (len=3, tl=0) 1,2,3
## [1] 1 2 3
.Internal(inspect(k1))
## @0x000000000a426578 14 REALSXP g0c3 [REF(2)] (len=3, tl=0) 1,2,3
# Caso 2
a <- c(1, 2, 3)
.Internal(inspect(a))
## @0x000000000a426398 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 1,2,3
k2 <- f2(a)
## @0x000000000a426398 14 REALSXP g0c3 [REF(2)] (len=3, tl=0) 1,2,3
## [1] 1 2 3
## @0x000000000a426258 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 10,2,3
## [1] 10 2 3
.Internal(inspect(k2))
## @0x000000000a426258 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 10,2,3
O objeto quando é vinculado em um argumento de um função, entra como promessa, isto significa que ele não é avaliado, apenas quando for chamado no corpo da função. Se nenhuma alteração for realizada a esse objeto, nenhuma cópia é realizada, porém a contagem de referência terá um nível superior. Observe o objeto a, o seu identificador de memória é o mesmo quando chamamos a primeira vez o argumento x = a na função f1(). Isso significa que como essa função é uma identidade, apenas imprime o próprio argumento, portanto, nada é alterado no argumento x. Porém, REF(1) passa para REF(2), e o nome k1 passa a se associar também com o objeto, ao invés de uma cópia de objeto, que pode ser representado pela Figura 5. No segundo caso, criamos novamente o objeto a, ao ser chamado inicialmente agora na função f2, a contagem de referência passa para REF(2), porém sem cópia inicialmente. Quando a chamada [<- é executada ocorre uma cópia, por causa de REF(2), Figura 5. Ao ser copiado, essa função primitiva retorna a contagem de referência para 1, e a saída da função ocorre para REF(1). Nesse sentido, os objetos associados aos nomes k1 e k2, posteriormente, se alterados terão comportamentos diferentes. O objeto associado a k1 se alterado, será realizado uma cópia, e no caso de k2 ocorrerá uma modificação no local, tudo por causa da contagem de referência em cada um dos casos.
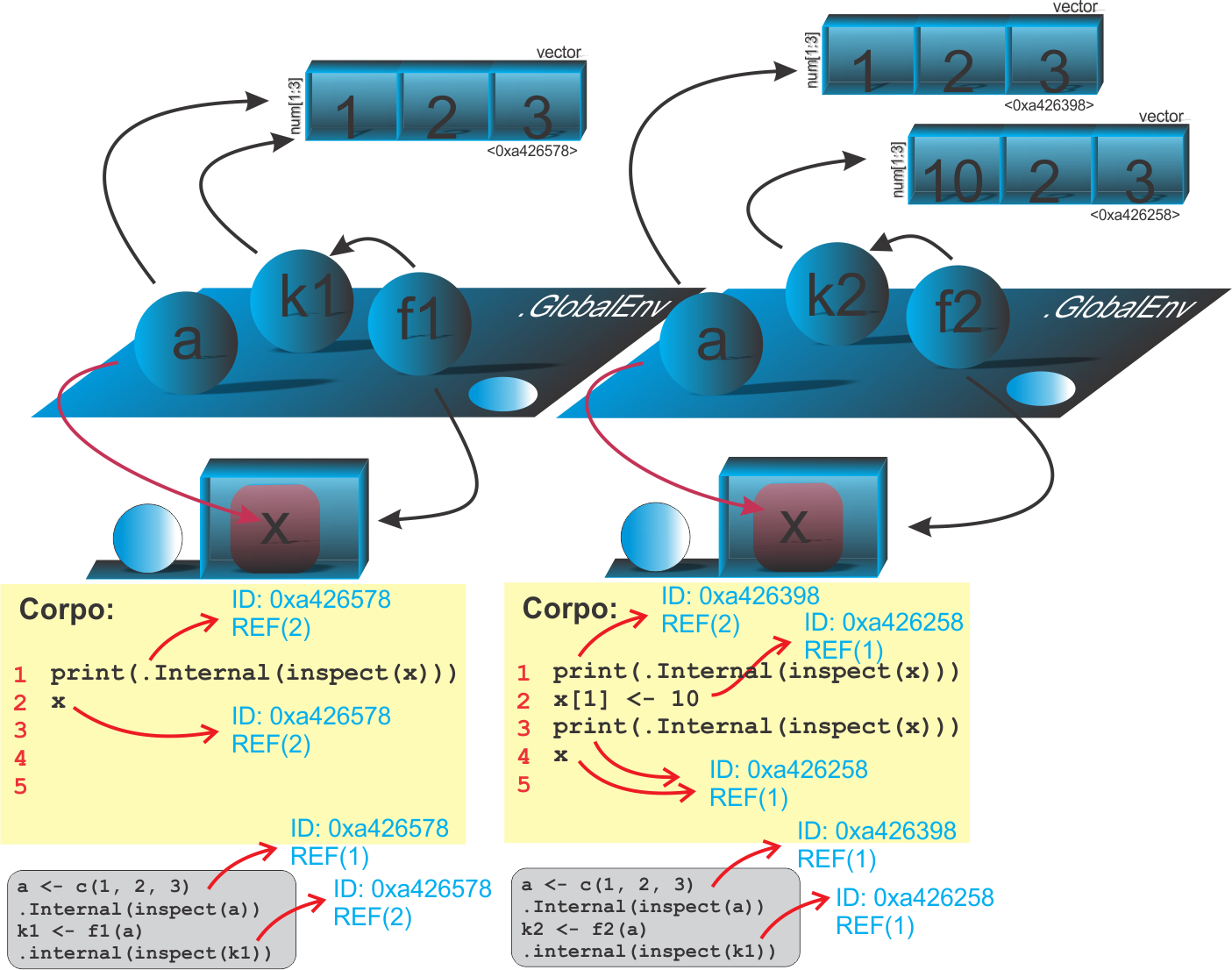
Figure 5: Cópia e modificação no local de objetos.
Os objetos tipo listas, que na realidade vetores mais complexos, apresentam comportamento semelhante na cópia na modificação, e na modificação no local. A ideia seguirá a mesma com a contagem de referência, REF(1) ocorre a modificação no local, e valores superiores a 1, cópia na modificação.
Como visto no módulo básico, os elementos de uma lista são vetores atômicos, e até mesmo listas. Desse modo, diferentemente dos vetores cuja estrutura armazena os próprios valores, as listas armazenam as identificações de memória em que os objetos foram alocados. Vejamos a estrutura de baixo nível desse tipo de objeto.
# Objeto lista
l1 <- list(c(1, 2, 3), 10L, TRUE)
# Inspecao do objeto
.Internal(inspect(l1))
## @0x00000000060b27f8 19 VECSXP g0c3 [REF(1)] (len=3, tl=0)
## @0x00000000060b2848 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 1,2,3
## @0x00000000060af018 13 INTSXP g0c1 [REF(3)] (len=1, tl=0) 10
## @0x00000000060aefa8 10 LGLSXP g0c1 [REF(3)] (len=1, tl=0) 1
# Associacao de outro nome l2 ao obj lista
l2 <- l1
# Inspecao
.Internal(inspect(l2))
## @0x00000000060b27f8 19 VECSXP g0c3 [REF(2)] (len=3, tl=0)
## @0x00000000060b2848 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 1,2,3
## @0x00000000060af018 13 INTSXP g0c1 [REF(3)] (len=1, tl=0) 10
## @0x00000000060aefa8 10 LGLSXP g0c1 [REF(3)] (len=1, tl=0) 1
# Alterando l2
l2[[3]] <- 5
# Inspecao
.Internal(inspect(l2))
## @0x00000000064fc860 19 VECSXP g0c3 [REF(1)] (len=3, tl=0)
## @0x00000000060b2848 14 REALSXP g0c3 [REF(2)] (len=3, tl=0) 1,2,3
## @0x00000000060af018 13 INTSXP g0c1 [REF(4)] (len=1, tl=0) 10
## @0x0000000007fc77e0 14 REALSXP g0c1 [REF(3)] (len=1, tl=0) 5
Nesse caso, podemos representar uma lista pela Figura 6. Observemos quando criamos mais de um nome associado ao objeto lista, e como os seus elementos apontam para os vetores.
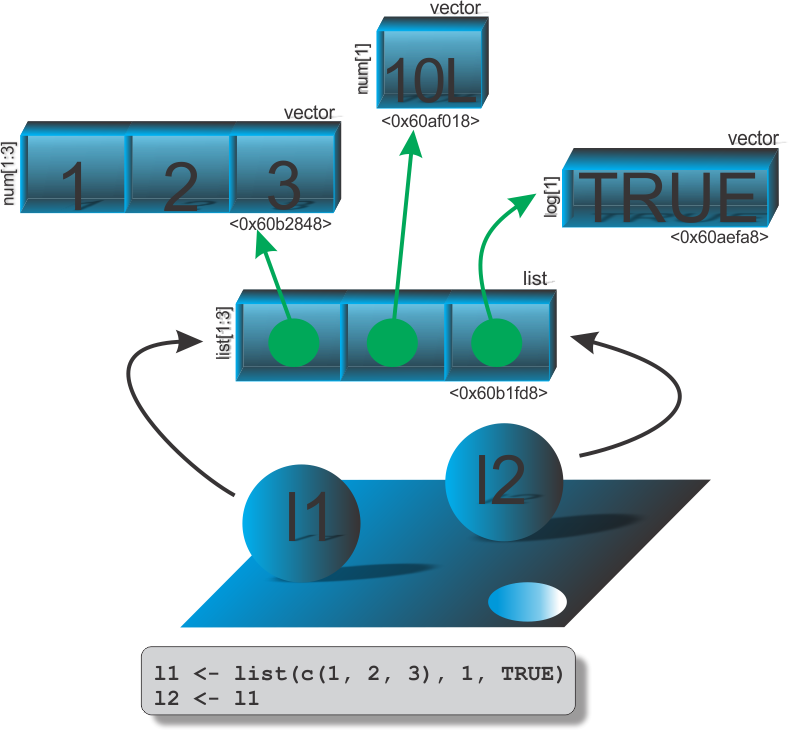
Figure 6: Vinculação de nomes ao objeto lista.
A alteração do terceiro elemento da lista l2, proporciona uma cópia de l1, porém os dois primeiros elementos de l2 apontam para os mesmos dois primeiros objetos de l1, não havendo cópia sobre esses vetores, Figura 7. Para saber se determinado vetor de uma lista será copiado ou modificado no local, seguirá a mesma regra abordada em vetores com relação a contagem de referência dos vetores e não a contagem de referência da lista.
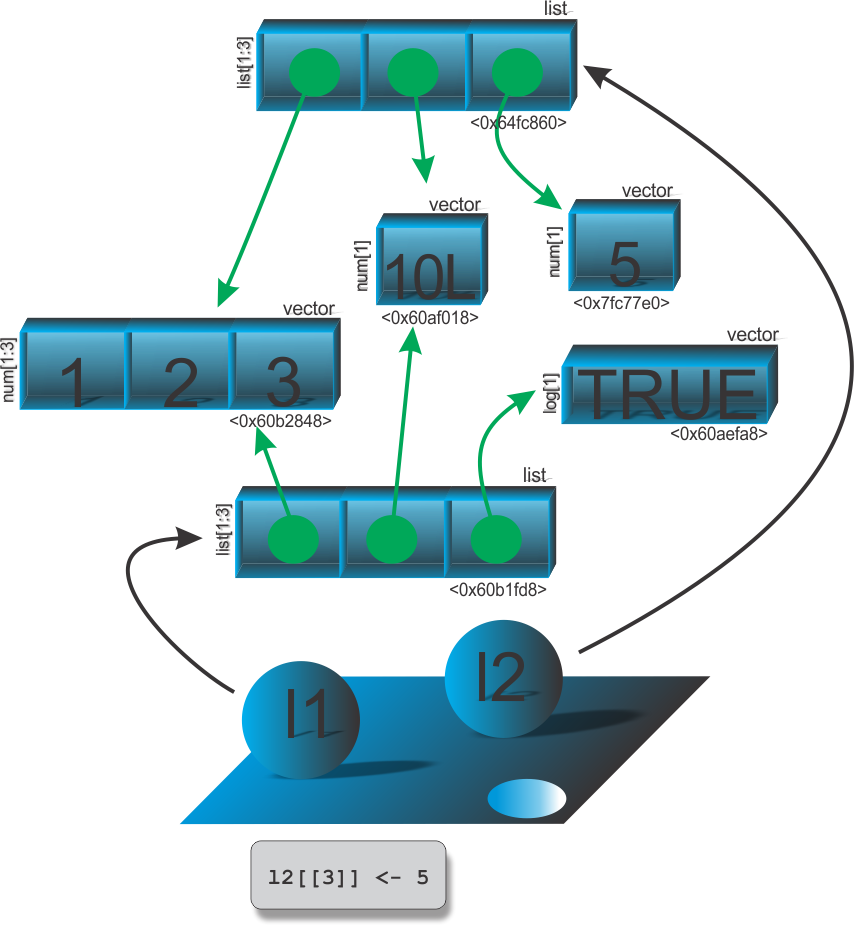
Figure 7: Cópias de listas.
Aparentemente, os quadro de dados (Data frames) deveriam ter os mesmos comportamentos de uma lista na cópia ou modificação no local. Porém, apresentamos uma diferença marcante no quadro de dados, alterar uma coluna nesse objeto, modifica apenas essa coluna, contudo, modificar por linha, todo o objeto é copiado. Vejamos em código essa explicação.
qd1 <- data.frame(c1 = c(1, 2, 3), c2 = c(4, 5, 6))
# Inspecao
.Internal(inspect(qd1))
## @0x0000000007ff9e78 19 VECSXP g0c2 [OBJ,REF(1),ATT] (len=2, tl=0)
## @0x0000000006382578 14 REALSXP g0c3 [REF(5)] (len=3, tl=0) 1,2,3
## @0x0000000006382528 14 REALSXP g0c3 [REF(5)] (len=3, tl=0) 4,5,6
## ATTRIB:
## ...
# A primeira alteracao em copia
qd1$c1[2] <- 10
.Internal(inspect(qd1))
## @0x0000000007ffa178 19 VECSXP g0c2 [OBJ,REF(1),ATT] (len=2, tl=0)
## @0x000000000985c8f8 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 1,10,3
## @0x0000000006382528 14 REALSXP g0c3 [REF(6)] (len=3, tl=0) 4,5,6
## ATTRIB:
## ...
# Quando REF(1), a modificacao ocorre no local
qd1$c1[1] <- 99
.Internal(inspect(qd1))
## @0x0000000007ffa1b8 19 VECSXP g0c2 [OBJ,REF(1),ATT] (len=2, tl=0)
## @0x000000000985c8f8 14 REALSXP g0c3 [REF(2)] (len=3, tl=0) 99,10,3
## @0x0000000006382528 14 REALSXP g0c3 [REF(7)] (len=3, tl=0) 4,5,6
## ATTRIB:
## ...
# Porem, quando a alteracao ocorre em linha,
# sempre havera copia na modificacao
qd1[1,] <- c(00, 00)
.Internal(inspect(qd1))
## @0x0000000007c2f3c8 19 VECSXP g0c2 [OBJ,REF(1),ATT] (len=2, tl=0)
## @0x00000000098c3550 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 0,10,3
## @0x00000000098c3500 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 0,5,6
## ATTRIB:
## ...
# Porem, mesmo com REF(1) e alteracao em linha,
# havera copia na modificacao
qd1[2,] <- c(11, 11)
.Internal(inspect(qd1))
## @0x0000000007c0abe8 19 VECSXP g0c2 [OBJ,REF(1),ATT] (len=2, tl=0)
## @0x00000000098c3230 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 0,11,3
## @0x00000000098c31e0 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 0,11,6
## ATTRIB:
## ...
No caso das modificações realizadas em coluna, podemos também verificar por meio da Figura 8. No caso das alterações realizadas em linha, sempre haverá cópia na modificação.
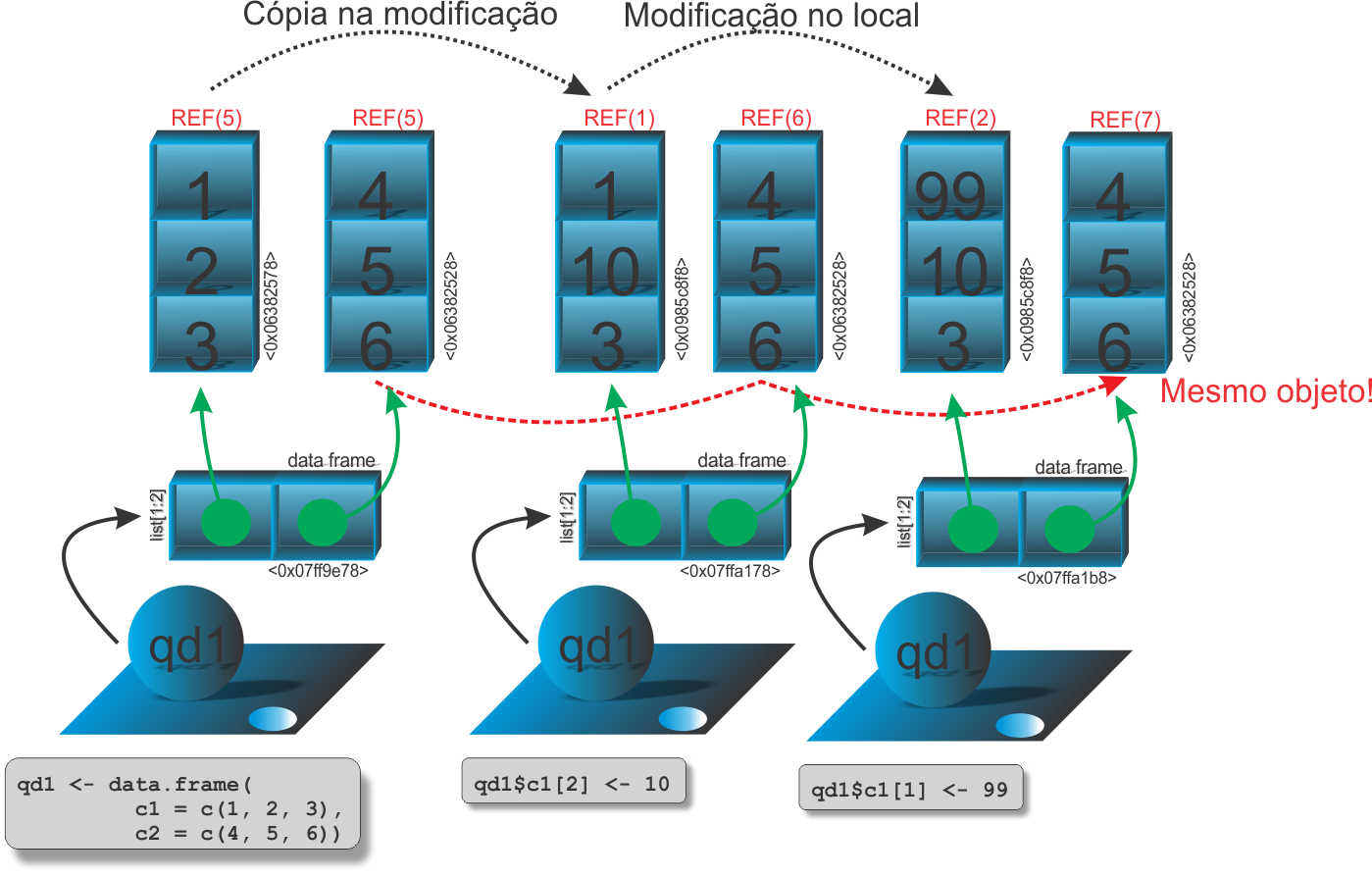
Figure 8: Cópia de quadro de dados (data frames).
Quando o objeto quadro de dados tem dois nomes associados, segue as mesmas ideias apresentadas nas listas, com a adição das características verificadas anteriormente para esse tipo de objeto, em que abaixo, apresentamos mais um código para análise.
# Quadro de dados 1
qd1 <- data.frame(c1 = c(1, 2, 3), c2 = c(4, 5, 6))
# Inspecao
.Internal(inspect(qd1))
## @0x00000000064d2db8 19 VECSXP g0c2 [OBJ,REF(1),ATT] (len=2, tl=0)
## @0x00000000099a0448 14 REALSXP g0c3 [REF(5)] (len=3, tl=0) 1,2,3
## @0x00000000099a03f8 14 REALSXP g0c3 [REF(5)] (len=3, tl=0) 4,5,6
## ATTRIB:
## ...
# Quadro de dados 2
qd2 <- qd1
# Inspecao
.Internal(inspect(qd2))
## @0x00000000064d2db8 19 VECSXP g0c2 [OBJ,REF(2),ATT] (len=2, tl=0)
## @0x00000000099a0448 14 REALSXP g0c3 [REF(5)] (len=3, tl=0) 1,2,3
## @0x00000000099a03f8 14 REALSXP g0c3 [REF(5)] (len=3, tl=0) 4,5,6
## ATTRIB:
## ...
# A copia em coluna, o quadro de dado copia apenas a coluna
qd2$c1[2] <- 10
.Internal(inspect(qd2))
## @0x00000000064d3238 19 VECSXP g0c2 [OBJ,REF(1),ATT] (len=2, tl=0)
## @0x00000000099cf960 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 1,10,3
## @0x00000000099a03f8 14 REALSXP g0c3 [REF(7)] (len=3, tl=0) 4,5,6
## ATTRIB:
## ...
qd2$c2 <- c(100, 100, 100)
.Internal(inspect(qd2))
## @0x00000000064d32b8 19 VECSXP g0c2 [OBJ,REF(1),ATT] (len=2, tl=0)
## @0x00000000099cf960 14 REALSXP g0c3 [REF(2)] (len=3, tl=0) 1,10,3
## @0x00000000099cf870 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 100,100,100
qd2[1,] <- c(100, 100)
.Internal(inspect(qd2))
## @0x00000000064d34b8 19 VECSXP g0c2 [OBJ,REF(1),ATT] (len=2, tl=0)
## @0x00000000099cf5a0 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 100,10,3
## @0x00000000099cf550 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 100,100,100
## ATTRIB:
## ...
Podemos perceber ao final algumas características para a modificação no local:
- contagem de referência;
- objetos associados a apenas um nome;
- objetos tipo
"Environment", ambientes. Será apresentado apenas nas seções seguintes, quando aprofundamentos as características desse tipo de objeto.
Por fim, não poderíamos de reforçar o exemplo apresentado na Figura 4. Esses dois objetos são vetores tipo character, isto é string. Apesar de apresentarmos dessa forma: x <- c("a", "b", "d"), e parecer um objeto alocado em um mesmo espaço de memória para armazenar seus valores, o que temos na realizadade é um ponteiro para cada elemento do vetor, apontando para uma string única dentro do conjunto de caracteres (strings) global, que nesse caso é um objeto tipo CHARSXP, apresentada na seção Objetos base, acessível apenas internamente ao ambiente R. Vejamos alguns exemplos pelo código a seguir.
# Criamos tres objetos tipo 'character'
x <- c("a", "b", "d")
y <- c("a", "abc", "e")
z <- c("f", "abc", "b")
# Inspecionando os objetos
.Internal(inspect(x))
## @0x0000000006f84908 16 STRSXP g0c3 [REF(1)] (len=3, tl=0)
## @0x0000000006589e38 09 CHARSXP g0c1 [MARK,REF(10),gp=0x61] [ASCII] [cached] "a"
## @0x0000000006c3d580 09 CHARSXP g0c1 [MARK,REF(14),gp=0x60] [ASCII] [cached] "b"
## @0x0000000006a5ec00 09 CHARSXP g0c1 [MARK,REF(5),gp=0x61] [ASCII] [cached] "d"
.Internal(inspect(y))
## @0x0000000006f84868 16 STRSXP g0c3 [REF(1)] (len=3, tl=0)
## @0x0000000006589e38 09 CHARSXP g0c1 [MARK,REF(10),gp=0x61] [ASCII] [cached] "a"
## @0x0000000006984360 09 CHARSXP g0c1 [REF(7),gp=0x60] [ASCII] [cached] "abc"
## @0x0000000000393188 09 CHARSXP g0c1 [MARK,REF(5),gp=0x61] [ASCII] [cached] "e"
.Internal(inspect(z))
## @0x0000000006f847c8 16 STRSXP g0c3 [REF(1)] (len=3, tl=0)
## @0x000000000641d518 09 CHARSXP g0c1 [MARK,REF(6),gp=0x61] [ASCII] [cached] "f"
## @0x0000000006984360 09 CHARSXP g0c1 [REF(7),gp=0x60] [ASCII] [cached] "abc"
## @0x0000000006c3d580 09 CHARSXP g0c1 [MARK,REF(14),gp=0x60] [ASCII] [cached] "b"
# Se alterar apenas a 'string', ocorre apenas a mudanca do
# apontamento com modificacao local
x[2] <- "f"
.Internal(inspect(x))
## @0x0000000006f84908 16 STRSXP g0c3 [REF(1)] (len=3, tl=0)
## @0x0000000006589e38 09 CHARSXP g0c1 [MARK,REF(10),gp=0x61] [ASCII] [cached] "a"
## @0x000000000641d518 09 CHARSXP g0c1 [MARK,REF(9),gp=0x61] [ASCII] [cached] "f"
## @0x0000000006a5ec00 09 CHARSXP g0c1 [MARK,REF(5),gp=0x61] [ASCII] [cached] "d"
# Alterando os elementos, bem como sua dimensao, ocorrera a copia
# do objeto STRSXP, porem os elementos continuam apontando para as suas
# respectivas 'strings' globais
x[4] <- "f"
.Internal(inspect(x))
##@0x0000000006988190 16 STRSXP g0c3 [REF(1)] (len=4, tl=0)
## @0x0000000006589e38 09 CHARSXP g0c1 [MARK,REF(11),gp=0x61] [ASCII] [cached] "a"
## @0x000000000641d518 09 CHARSXP g0c1 [MARK,REF(13),gp=0x61] [ASCII] [cached] "f"
## @0x0000000006a5ec00 09 CHARSXP g0c1 [MARK,REF(6),gp=0x61] [ASCII] [cached] "d"
## @0x000000000641d518 09 CHARSXP g0c1 [MARK,REF(13),gp=0x61] [ASCII] [cached] "f"
Pela Figura 9, podemos entender o que ocorrer nesses objetos. Para a situação de cópia, isso ocorrerá apenas se houver a alteração da dimensão do vetor. Caso, contrário a modificação ocorre no local.
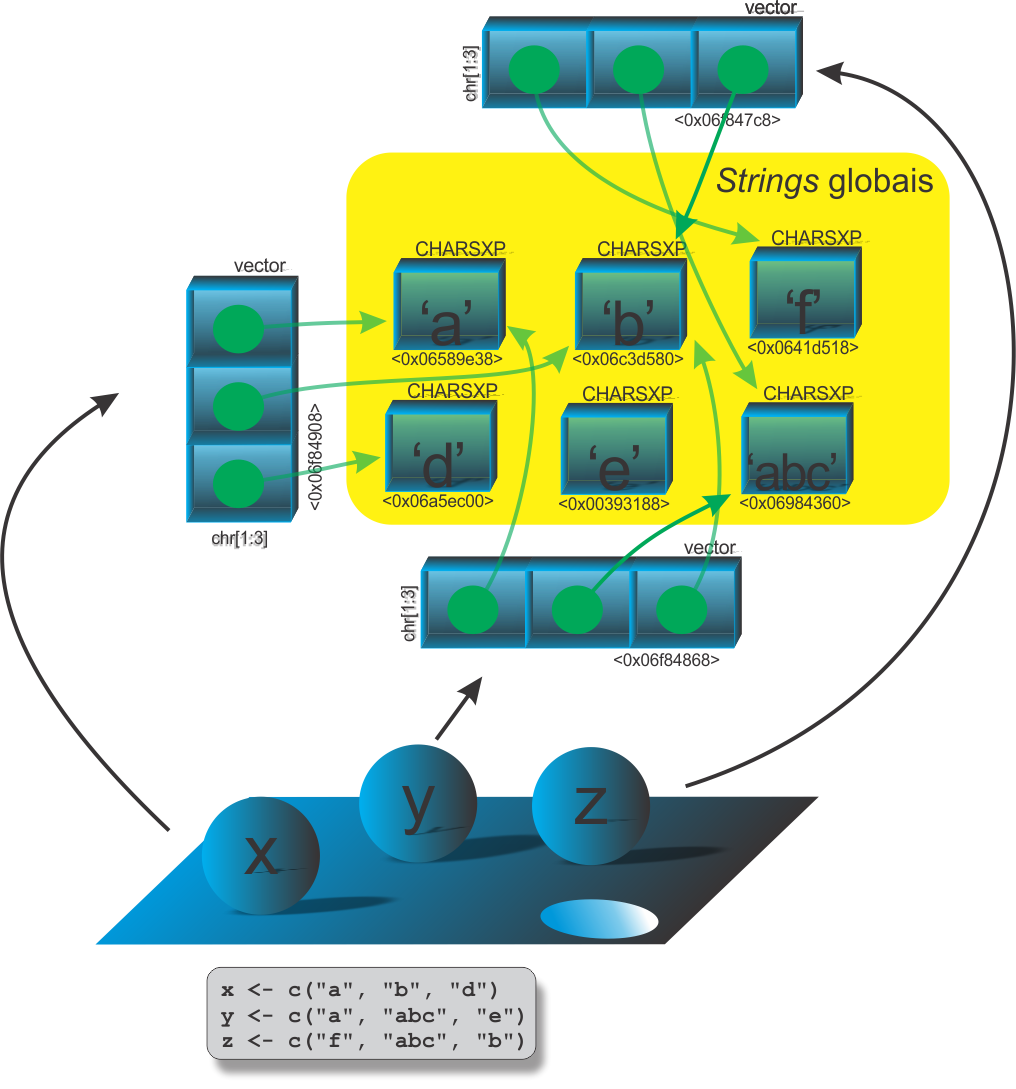
Figure 9: Cópia de quadro de dados (data frames).
Tamanho de objetos
Quando falamos sobre tamanho de objetos, estamos pensando no quanto de memória é preciso para armazenar o objeto em seu computador. Porém, em algumas situações pode ser questionável esse tamanho, quando temos objetos cujos elementos são referências para objetos já existentes ou objetos existentes propriamente dito. Outra forma, ocorre quando há o compartilhamento de objetos em objeto listas ou data frames. A forma de verificarmos esse tamanho, pode ser por meio das funções, object.size() e lobstr::obj_size(). A primeira função quando temos comportilhamento de objetos em listas ou quadro dados por exemplo, pode superestimar o tamanho de memória para o referido objeto. Vamos observar alguns casos como esses, a seguir.
O tamanho dos objeto está relacionado com a cópia ou modificação no local. Além do mais, devemos notar também que listas e quadro de dados apontam para objetos que podem estar compartilhados, e algumas funções podem apresentar uma superestimativa do tamanho, que é o caso da função object.size(). Vamos comparar o resultado dessa função com lobstr::obj_size() na Figura 10.
Figure 10: Tamanho de memória de listas.
Observamos que o objeto z é uma lista com cinco elementos, em que as referências apontam para o mesmo objeto. A estimativa de object.size() considera que os elementos apontam para objetos diferentes, quando na realidade está havendo um compartilhamento. Desse modo, o resultado de lobstr::obj_size() é bem menor e mais próximo do tamanho real, aproximadamente cinco vezes menor que o tamanho encontrado por object.size().
No caso dos vetores tipo character como já falado anteriormente, iremos perceber que repetir uma string 1000 vezes, não significará multiplicar mil vezes o tamanho da memória reservada para essa string para armazenar esse objeto. O que ocorre é que o vetor armazena mil referências nos elementos para apontar para o mesmo objeto CHARSXP. Chamado uma vez uma determinada string em um objeto, poderemos observar que enquanto não fecharmos o nosso ambiente de trabalho, o espaço de memória alocada para essa string será sempre a mesma, seja usada nesse objeto ou em outros que possam ser de interesse. Nesse caso, percebamos que uma vez usada uma determinada string em um objeto, por ventura se for utilizada também em outros objetos, não estaremos ocupando mais memória específica para armazenar essa string, mas sim, se houver um acréscimo de memória para armazená-lo, será apenas para a referência que aponta para esse objeto (CHARSXP) no conjunto global de strings. Vejamos um exemplo para ilustrar.
x <- "ben"
lobstr::obj_size(x)
112 Bobject.size(x)
112 bytesy <- rep(x, 1000); y
[1] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[11] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[21] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[31] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[41] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[51] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[61] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[71] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[81] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[91] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[101] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[111] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[121] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[131] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[141] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[151] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[161] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[171] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[181] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[191] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[201] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[211] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[221] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[231] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[241] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[251] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[261] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[271] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[281] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[291] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[301] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[311] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[321] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[331] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[341] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[351] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[361] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[371] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[381] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[391] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[401] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[411] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[421] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[431] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[441] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[451] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[461] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[471] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[481] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[491] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[501] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[511] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[521] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[531] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[541] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[551] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[561] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[571] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[581] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[591] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[601] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[611] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[621] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[631] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[641] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[651] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[661] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[671] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[681] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[691] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[701] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[711] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[721] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[731] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[741] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[751] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[761] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[771] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[781] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[791] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[801] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[811] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[821] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[831] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[841] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[851] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[861] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[871] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[881] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[891] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[901] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[911] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[921] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[931] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[941] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[951] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[961] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[971] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[981] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"
[991] "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben" "ben"lobstr::obj_size(x)
112 Bobject.size(x)
112 bytesUma outra situação que vale a pena discutirmos é quando armazenamos objetos em listas, cujos os objetos são existentes com a inicialização do ambiente R, apresentado no código a seguir.
A pergunta é, será que estamos utilizando, aproximadamente, toda essa memória para o objeto l1? Sabemos que as funções median() e range são do pacote base e com a inicialização do ambiente R, todos os objetos desse pacote são carregados, isto implica em um espaço de memória para alocar esses objetos. Podemos perceber também que o espaço de memória para armazenar esses objetos, são respectivamente, 1296 e 0, aproximadamente. O que os elementos de l1 fizeram foi guardar a referência que aponta para esses objetos, e que muito provavelmente não precisaria de toda a memória para armazenar todo o objeto. De outro modo, percebemos que o tamanho real do objeto não é o que se apresenta, uma vez que os objetos apontados nas referências dos elementos das listas já existem, e desse modo, não foram necessários para armazenar todo o objeto, mas apenas o seu identificador de memória (referência). Vejamos o código a seguir, para confirmar o que acabamos de discutir.
# Inspecionando as funcoes 'median' e 'range'
.Internal(inspect(median))
## @0x0000000006463210 03 CLOSXP g0c0 [MARK,REF(3)]
## ...
.Internal(inspect(range))
## @0x0000000000368688 08 BUILTINSXP g0c0 [MARK,REF(65535)]
# Inspecionando o objeto 'l1'
l1 <- list(median, range)
.Internal(inspect(l1))
## @0x000000000038f300 19 VECSXP g0c2 [REF(1)] (len=2, tl=0)
## @0x0000000006463210 03 CLOSXP g0c0 [MARK,REF(4)]
## ...
## @0x0000000000368688 08 BUILTINSXP g0c0 [MARK,REF(65535)]
O identificadores de memória quando inspecionamos as funções median e range, são os mesmos identificadores para onde os elementos de l1 apontam, confirmando assim, que esses espaços de memória já estavam reservados, e não foram alocados com a criação do objeto.
Por fim, como já mencionado no módulo básico, a representação alternativa (ALTREP) de uma sequência de elementos, por meio de “:” pode nos causar expanto, porque independente do comprimento, é armazenado apenas o primeiro e o último elemento da sequência. Isso significa que os vetores criados a partir de :, terão mesmo tamanho. Contudo, quando falos
Aprofundamento sobre ambientes
Antes de iniciarmos um aprofundamento sobre ambientes, sugerimos a revisão introdutório desse assunto, no módulo básico, na seção Ambientes e Caminho de busca. O que falaremos nessa seção, pressupomos o entendimento que foi estudado no módulo anterior.
A primeira ideia ilustrada que iremos abordar é a hierarquização de ambientes pelo caminho de busca, usando search(). Sabemos que todo ambiente tem um pai ou ambiente superior, e que a única excessão é o ambiente vazio, emptyenv(). A representação dessa hierarquização pode ser observada na Figura 11.

Figure 11: Caminho por onde os objetos serão procurados.
Para sabermos os parentais de um determinado ambiente, podemos recorrer ao pacote rlang. Por exemplo, vamos criar um ambiente, e verificar seus parentais, a seguir.
# Ambiente
amb1 <- new.env()
# Verificando os seus parentais
rlang::env_parents(amb1, last = emptyenv())
[[1]] $ <env: global>
[[2]] $ <env: package:midrangeMCP>
[[3]] $ <env: package:SMR>
[[4]] $ <env: package:magrittr>
[[5]] $ <env: package:leaflet>
[[6]] $ <env: package:stats>
[[7]] $ <env: package:graphics>
[[8]] $ <env: package:grDevices>
[[9]] $ <env: package:utils>
[[10]] $ <env: package:datasets>
[[11]] $ <env: package:methods>
[[12]] $ <env: Autoloads>
[[13]] $ <env: package:base>
[[14]] $ <env: empty>Observemos que os parentais presentes, apresentou alguns ambientes como tools:rstudio, Autoloads. O primeiro sempre aparece quando usamos a IDE RStudio. O ambiente Autoloads, que pode ser acessado por .AutoloadEnv, é um ambiente que armazena promessas de ligações. Por exemplo, podemos estar interessados em usar a função makeCluster do pacote parallel, porém, ao invés de carregar o pacote e alocar memória para armazenar todos o seus objetos, podemos deixar a função makeCluster como promessa no ambiente Autoloads, e caso seja utilizado em alguma linha de comando, uma outra função autoloader() é acionada, carregando o pacote parallel e a função de interesse e reavaliada no ambiente do pacote parallel. Qual a vantagem disso? Enquanto a função não é chamada, é como se o pacote estivesse carregado, porém sem ocupar nenhuma memória. Vejamos o exemplo a seguir.
# Promessa makeCluster
autoload("makeCluster", "parallel")
# Caminho de busca sem o pacote 'parallel'
search()
[1] ".GlobalEnv" "package:midrangeMCP" "package:SMR"
[4] "package:magrittr" "package:leaflet" "package:stats"
[7] "package:graphics" "package:grDevices" "package:utils"
[10] "package:datasets" "package:methods" "Autoloads"
[13] "package:base" # Verificamos que 'makeCluster' esta como promessa
ls("Autoloads")
[1] "makeCluster"# Chamando a funcao
makeCluster
function (spec, type = getClusterOption("type"), ...)
{
switch(type, PSOCK = makePSOCKcluster(names = spec, ...),
FORK = makeForkCluster(nnodes = spec, ...), SOCK = snow::makeSOCKcluster(names = spec,
...), MPI = snow::makeMPIcluster(count = spec, ...),
NWS = snow::makeNWScluster(names = spec, ...), stop("unknown cluster type"))
}
<bytecode: 0x00000000437c5108>
<environment: namespace:parallel># Verificando novamente o Caminho de busca,
# agora com o pacote 'parallel'
search()
[1] ".GlobalEnv" "package:parallel" "package:midrangeMCP"
[4] "package:SMR" "package:magrittr" "package:leaflet"
[7] "package:stats" "package:graphics" "package:grDevices"
[10] "package:utils" "package:datasets" "package:methods"
[13] "Autoloads" "package:base" Quando a função de interesse, que estava como promessa, é chamada, observamos que o pacote que contempla essa função é carregado e passa a ser anexado ao caminho de busca. Uma outra situação interessante é que ao anexar um pacote, o ambiente de pacote (package:nome_pacote), será o pai do ambiente global. Daremos mais detalhes sobre ambiente de pacote mais a frente.
Sabemos que o ambiente global é o ambiente corrente quando executamos a maioria de nossas linhas de comando, mas podemos também usar a chamada environment() para tal. Pelo caminho de busca ou caminho de pesquisa, o ambiente R procura pelos objetos. Assim, digitando alguma linha de comando no console, a primeira busca por um objeto, do qual um nome está associado a ele, se iniciará pelo ambiente global (.GlobalEnv), caso não encontre o nome específico no ambiente global, o ambiente R procurará pelo nome no ambiente pai, que no caso da Figura 11, será o ambiente package:stats, e assim por diante. Não encontrando o nome específico em algum dos ambientes, a execução do comando retornará um erro informando que o objeto não foi encontrado. Vejamos o código a seguir.
Observemos que três chamadas de funções foram realizadas, <-, mean() e c(). Essas funções não estão no ambiente global, que poderiam ser inspecionadas por ls(). Desse modo, o ambiente R procurará por todo o caminho de busca, e os encontrará no ambiente package:base. Uma vez encontrado, as funções são chamadas e a execução das linhas ocorrem com sucesso, Figura 12.
Figure 12: Procurando por funções.
O que é interessantes em ambientes é que eles podem se conter, e ainda mais, as modificações ocorridas nos ambientes, modificam no local e não ocorrem cópias, como ocorre na maioria das situações com outros objetos, e algumas vezes isso é chamado de semâtica de referência, porque mesmo alterando o objeto as suas ligações continuam com as mesmas referências. Vejamos a Figura 13, como um exemplo, e seu respectivo código na sequência para inspeção do que acabamos de falar.
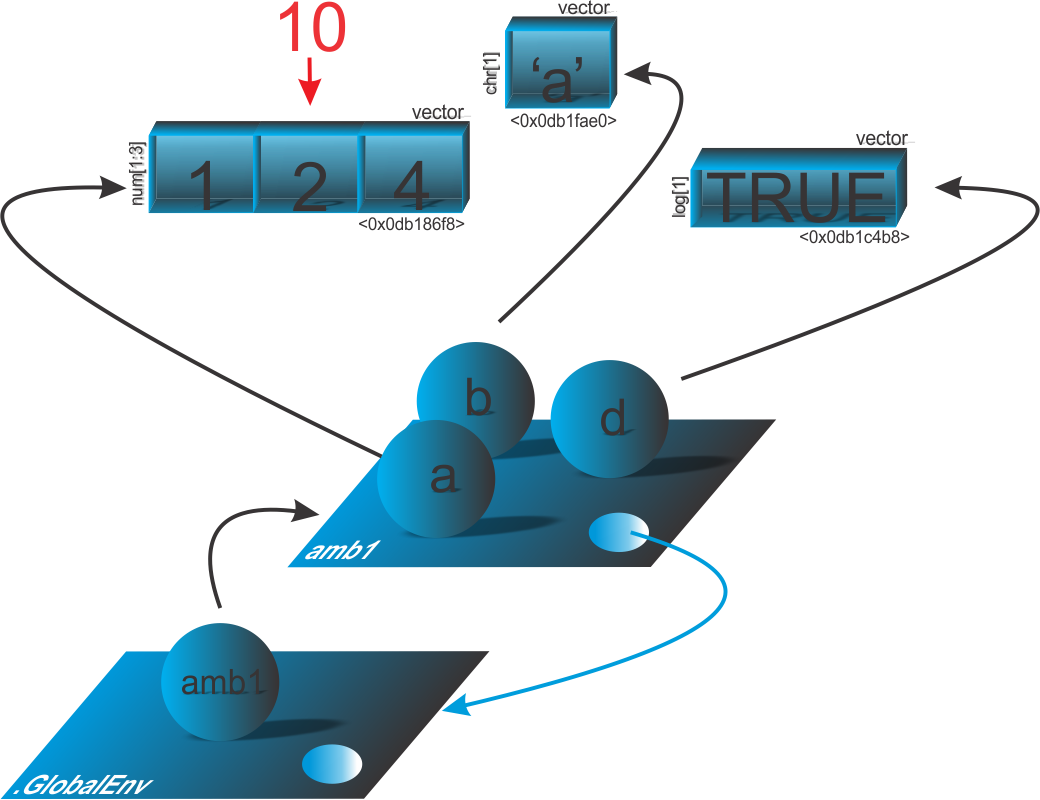
Figure 13: Criando ambientes.
# Ambiente
amb1 <- new.env(hash = FALSE)
# Inserindo objetos nesse ambiente
amb1$a <- c(1, 2, 4); amb1$b <- "a"; amb1$d <- TRUE
# Inspecao do objeto.
Internal(inspect(amb1))
## @0x000000000db22758 04 ENVSXP g0c0 [REF(1)] <0x000000000db22758>
## FRAME:
## @0x000000000db213a8 02 LISTSXP g0c0 [REF(1)]
## TAG: @0x00000000078ebb28 01 SYMSXP g0c0 [MARK,REF(128)] "d"
## @0x000000000db1fa38 10 LGLSXP g0c1 [REF(3)] (len=1, tl=0) 1
## TAG: @0x000000000db1c4b8 01 SYMSXP g0c0 [REF(10)] "b"
## @0x000000000db1fae0 16 STRSXP g0c1 [REF(3)] (len=1, tl=0)
## @0x0000000006369e78 09 CHARSXP g0c1 [MARK,REF(14),gp=0x61] [ASCII] [cached] "a"
## TAG: @0x0000000006483320 01 SYMSXP g0c0 [MARK,REF(60)] "a"
## @0x000000000db186f8 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 1,2,4
ENCLOS:
## @0x0000000005fda628 04 ENVSXP g0c0 [MARK,REF(65535),GL,gp=0x8000] <R_GlobalEnv>
amb1$a[2] <- 10
.Internal(inspect(amb1))
## @0x000000000db22758 04 ENVSXP g0c0 [REF(1)] <0x000000000db22758>
## FRAME:
## @0x000000000db213a8 02 LISTSXP g0c0 [REF(1)]
## TAG: @0x00000000078ebb28 01 SYMSXP g0c0 [MARK,REF(128)] "d"
## @0x000000000db1fa38 10 LGLSXP g0c1 [REF(3)] (len=1, tl=0) 1
## TAG: @0x000000000db1c4b8 01 SYMSXP g0c0 [REF(10)] "b"
## @0x000000000db1fae0 16 STRSXP g0c1 [REF(3)] (len=1, tl=0)
## @0x0000000006369e78 09 CHARSXP g0c1 [MARK,REF(16),gp=0x61] [ASCII] [cached] "a"
## TAG: @0x0000000006483320 01 SYMSXP g0c0 [MARK,REF(62)] "a"
## @0x000000000db186f8 14 REALSXP g0c3 [REF(1)] (len=3, tl=0) 1,10,4
## ENCLOS:
## @0x0000000005fda628 04 ENVSXP g0c0 [MARK,REF(65535),GL,gp=0x8000] <R_GlobalEnv>
parent.env(amb1)
## <environment: R_GlobalEnv>
De um modo geral, apresentamos a Tabela 3 para mostrar as principais funções para manipulações com ambientes
| Função | Objetivo |
|---|---|
globalenv() ou .GlobalEnv |
Ambiente global |
baseenv() |
Ambiente do pacote base |
emptyenv() |
Ambiente vazio |
environment() |
Ambiente corrente |
search() |
Lista o caminho de busca |
new.env() |
Criando um ambiente |
parent.env() |
Identificando o ambiente pai |
parent.frame() |
Ambiente funcional de chamada |
ls() ou ls.str() |
Descreve os objetos do ambiente |
get() |
Acessa o(s) valor(es) dos objetos de um ambiente |
exists() |
Verificando a existência de um objeto em um ambiente |
identical() |
Verificando a equivalência de ambientes |
Ambientes especiais
Precisamos apresentar alguns ambientes especiais, importantes para o entendimento do ambiente R.
Ambientes funcionais
Distinguimos quatro tipos de ambientes funcionais, que são:
- Ambiente envolvente ou ambiente de função;
- Ambiente de ligação;
- Ambiente de execução;
- ambiente de chamada;
Esses ambientes são extremamente importantes, para o entendimento do escopo léxico do ambiente R, uma vez que tudo no R é uma chamada de função (Segundo princípio), de modo que, o ambiente envolvente, de execução e de chamada estarão relacionados a forma de como a função procurará pelos objetos, ao passo que o ambiente de ligação estará relacionado a forma de como os usuários procurarão pelas funções.
Na Figura 14, apresentamos o ambiente envolvente e o ambiente de ligação, para o seguinte código:
# Criando o ambiente 'amb1'
amb1 <- new.env()
# Objeto x em 'amb1'
amb1$x <- 1
# Objeto x no ambiente global
x <- 2
# Criando a funcao 'h' em 'amb1'
amb1$h <- function() x
# chamando a funcao h()
amb1$h()
[1] 2# vericando o id de memoria de amb1
amb1 # ou .Internal(address(amb1))
<environment: 0x00000000159c7ad0># Ambiente envolvente de 'h'
environment(amb1$h)
<environment: R_GlobalEnv>Nesse caso, observemos que para acessarmos a função h, precisamos saber qual o seu ambiente de ligação, por isso acessamos essa função por amb1$h. Ao chamarmos amb1$h(), foi retornado o valor 2, Por quê? Esse resultado ocorre, porque ao ser criação o ambiente de execução para armazenar as ligações que ocorrerão no corpo da função, foi observado que não existia um nome x associado a algum objeto, nesse caso, a função passa a procurar no ambiente pai, que é o ambiente envolvente, e lá é encontrado o nome x associado ao valor 2. Desse modo, conseguimos compreender que o ambiente de ligação serve apenas para nós usuários encontrarmos a função h(), mas em nada serve para que h() encontre os objetos.
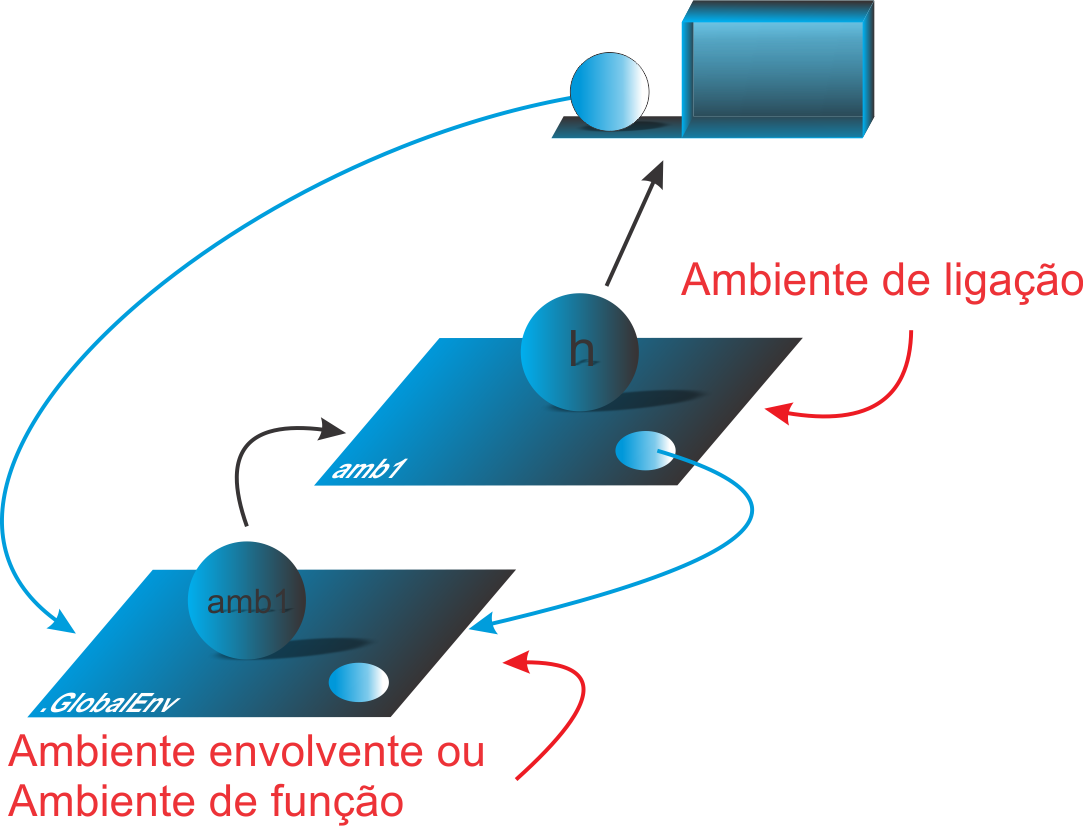
Figure 14: Ambiente envolvente e ambiente de ligação.
A função vincula o ambiente corrente no momento de sua criação, e pode ser verificado por environment(). Vejamos o código a seguir.
# Criando a funcao f1
f1 <- function() 1
# Verificando o ambiente envolvente de f1
environment(f1)
<environment: R_GlobalEnv># Criando uma funcao f
f <- function() {
# ambiente de execucao
cat("Ambiente de execucao de f: \n")
print(environment())
# Criando uma funcao f2
f2 <- function() 2
# Verificando o ambiente envolvente de f2
cat("Ambiente envolvente de f2:\n")
print(environment(f2))
}
f()
Ambiente de execucao de f:
<environment: 0x0000000014490520>
Ambiente envolvente de f2:
<environment: 0x0000000014490520>Observamos que a função f1 foi criada no ambiente global, e que a função f2 foi criada no ambiente de execução da função f, por isso a distinção dos ambientes envolventes dessas duas funções. Cada função terá apenas um ambiente envolvente.
No módulo básico, falamos sobre o ambiente de execução. Este ambiente é criado quando fazemos uma chamada de função. Após finalizado a chamada da referida função e retornado o valor desejado, este ambiente desaparece. O ambiente de execução tem como o pai o ambiente envolvente, e podemos representá-lo pela Figura 15, para o código a seguir.
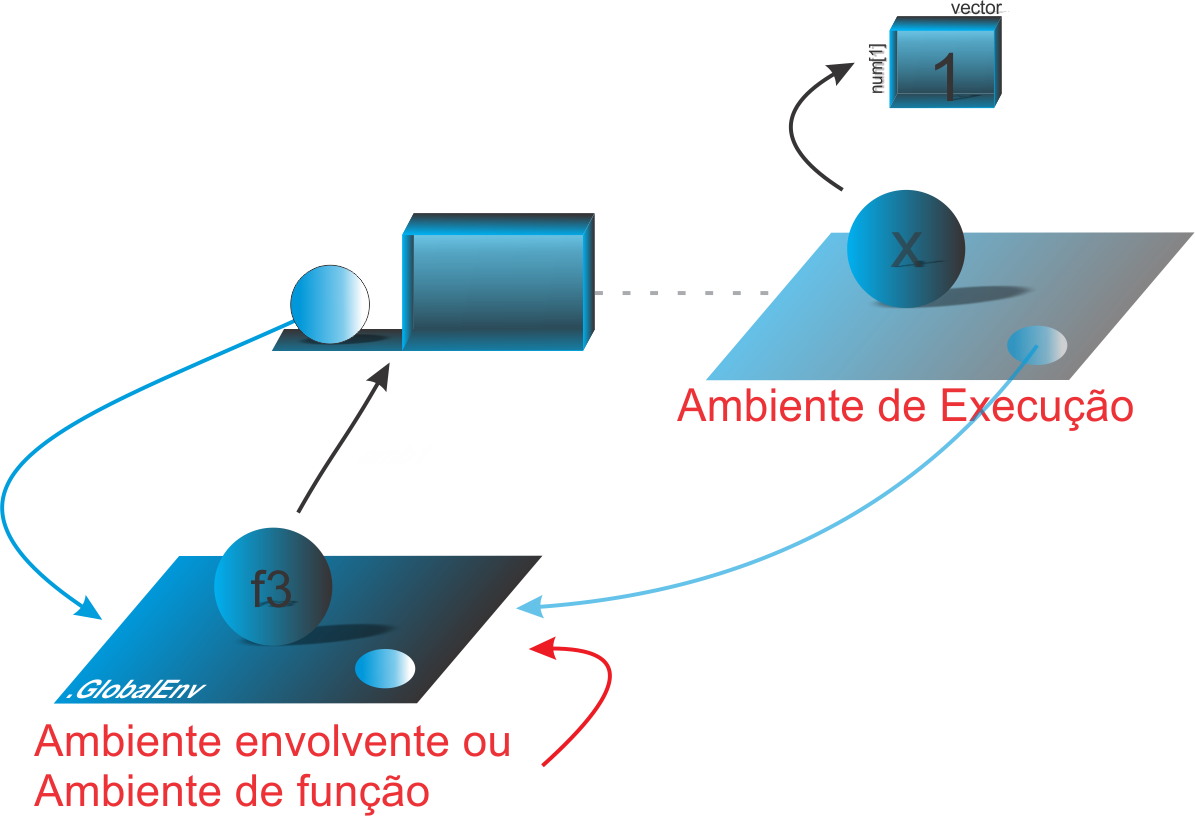
Figure 15: Ambiente envolvente e ambiente de execução.
Esse ambiente, apresenta muitas características como a máscara de nome e o novo começo, apresentados na seção Escopo léxico, no módulo básico.
Por fim, surge o último ambiente que é o ambiente de chamada, e está relacionado ao escopo dinâmico das funções em R, assunto também abordado na seção Escopo léxico, no módulo básico. Na realidade, diremos que os pais do ambiente de execução são o ambiente envolvente e o ambiente de chamada. Daí surge o escopo dinâmico, do qual a busca por objetos não sendo encontrado no ambiente de execução, será procurado no ambiente de chamada ao invés do ambiente envolvente. Apesar, de termos apresentado um exemplo no módulo básico sobre essa característica, vamos reforçar com um outro exemplo, no código a seguir.
# Fabrica de funcoes
h <- function() {
x <- 1
function() {
amb_envolvente <- get("x", environment())
amb_chamada <- get("x", parent.frame())
list(envolvente = amb_envolvente, chamada = amb_chamada)
}
}
# Funcao g
g <- h()
# Definindo 'x' no ambiente global
x <- 20
# Chamada de g(), e verificando 'x' no ambiente de envolvente e de chamada
g()
$envolvente
[1] 1
$chamada
[1] 20Ambientes em pacotes
Um detalhamento sobre ambientes em pacotes, bem como o desenvolvimento de pacotes, sugerimos acessar o projeto meupacoter, como também o livro Desenvolvimento de pacotes R.
Existem dois ambientes em pacotes, quais sejam:
- Ambientes de pacotes,
- Ambientes namespace.
Dizemos que o ambiente de pacote é o local em que os usuários procuram pelos objetos. O ambiente de pacote estará disponível no ambiente de busca, e quando um pacote é anexado anexado, o ambiente de pacote do referido pacote, será o pai do ambiente global, e o pai do ambiente de pacote segue a hierarquia do caminho de busca. Vejamos o código a seguir.
# Caminho de busca
search()
[1] ".GlobalEnv" "package:parallel" "package:midrangeMCP"
[4] "package:SMR" "package:magrittr" "package:leaflet"
[7] "package:stats" "package:graphics" "package:grDevices"
[10] "package:utils" "package:datasets" "package:methods"
[13] "Autoloads" "package:base" # Anexando o pacote 'parallel'
library(parallel)
# Verificando novamente o caminho de busca
search()
[1] ".GlobalEnv" "package:parallel" "package:midrangeMCP"
[4] "package:SMR" "package:magrittr" "package:leaflet"
[7] "package:stats" "package:graphics" "package:grDevices"
[10] "package:utils" "package:datasets" "package:methods"
[13] "Autoloads" "package:base" Verifiquemos que o ambiente de pacote parallel passa a ser o pai do ambiente global, após a anexação ao caminho de busca. Uma outra forma de acessar uma função de um pacote sem anexá-lo, é por meio da chamada “::” Contudo, vale salientar que nessa última situação houve apenas o carregamento de uma determinada função, sem anexo ao caminho de busca, e isto significa a disponibilidade do pacote na memória ativa. No caso, da anexação de um pacote ao caminho de busca, além do carregamento ocorre a anexação do referido pacote. Após isso, podemos acessar as suas funções, digitando os nomes das referidas funções sem precisar mencionar o pacote em que estas estão disponíveis.
O outro ambiente é fundamental para a procura interna dos objetos, e esse é o ambiente namespace. O ambiente de pacote é como uma cópia do ambiente namespace, porque as mesmas ligações encontradas em um ambiente, também está no outro. Por exemplo, vejamos o próximo código.
# Veja como uma funcao capta a informacao do ambiente global
y <- 2
aux <- function() {
return(y)
}
aux()
[1] 2# Testando a funcao sd(x)
#------------------------
x <- 1:3 # o resultado de sd(x) de ser 1!
# Criar uma variavel no ambiente global, 'var = "Nada"'.
# Isso, implica que se 'sd' usar essa informacao, devera retornar um erro, pq sd se baseia em um vetor numerico
var <- "Nada"
# Verificando a funcao 'sd()' internamente
sd
function (x, na.rm = FALSE)
sqrt(var(if (is.vector(x) || is.factor(x)) x else as.double(x),
na.rm = na.rm))
<bytecode: 0x0000000029010c70>
<environment: namespace:stats># Testando sd(x)
sd(x)
[1] 1# Agora veja uma outa situacao:
x <- c(1, 2, 3)
# Funcao 'var' que criamos, que nao calcula variancia de dados
var <- function(x) return("Nada")
# Funcao que depende de 'var' do pacote stats, e calcula a variancia
aux2 <- function(x) {
vari <- var(x)
return(vari)
}
# O resultado mostra, que a funcao aux como esta no ambiente global, ela não
# tem um namespace porque nao esta em pacote algum. No caminho de busca,
# o ambiente do pacote 'stats' estara na posicao 3, isso significa
# que a funcao aux ao buscar por 'var', encontrarar primeiro no
# ambiente global, que nao seria o objeto desejado.
aux2(x)
[1] "Nada"Antes de detalharmos a ideia do ambiente de namespace, precisamos entender uma estrutura do pacote que é um arquivo chamado NAMESPACE. Esse arquivo é responsável para definir quais os objetos de outros pacotes iremos importar, quais os objetos do pacote em desenvolvimento desejamos disponibilizar. Alguns outros objetos, principalmente funções, estão disponíveis apenas internamente, por decisão do desenvolvedor, muitas vezes por questão de futuras atualizações, ou outras finalidades. Desse modo, é o ambiente namespace que armazena todas as ligações dos objetos exportados, objetos importados ou objetos interno ao referido pacote. Assim, mostraremos que é por causa desse ambiente, que alguns outros objetos que não pertencem ao pacote e que podem estar no ambiente global, com o mesmo nome, e não entram em conflito. No código anterior, temos um exemplo típico para justificar essa situação. A função var() calcula a variância de um conjunto de dados, do qual a função sd(), que calcula o desvio padrão, depende da função var(). Ao passo que, também criamos uma função var() no ambiente global, que em nada tem a ver com o cálculo da variância. Assim, veremos que a função sd() acessará corretamente a função var() do pacote stats, o que não ocorrerá com a função aux(), uma vez que esta função tem como ambiente envolvente o ambiente global. A explicação para isso se deve ao fato que as funções desenvolvidos e importadas para um pacote, segue uma hierarquia de ambientes iniciada pelo ambiente namespace, que segue:
- Ambiente namespace do referido pacote;
- Ambiente de importações do referido pacote;
- Ambiente namespace do pacote
base; - Hierarquia de ambientes do caminho de busca.
Desse modo, conseguimos entender o porquê a função sd() encontrar var() de forma correta, pela Figura 16.
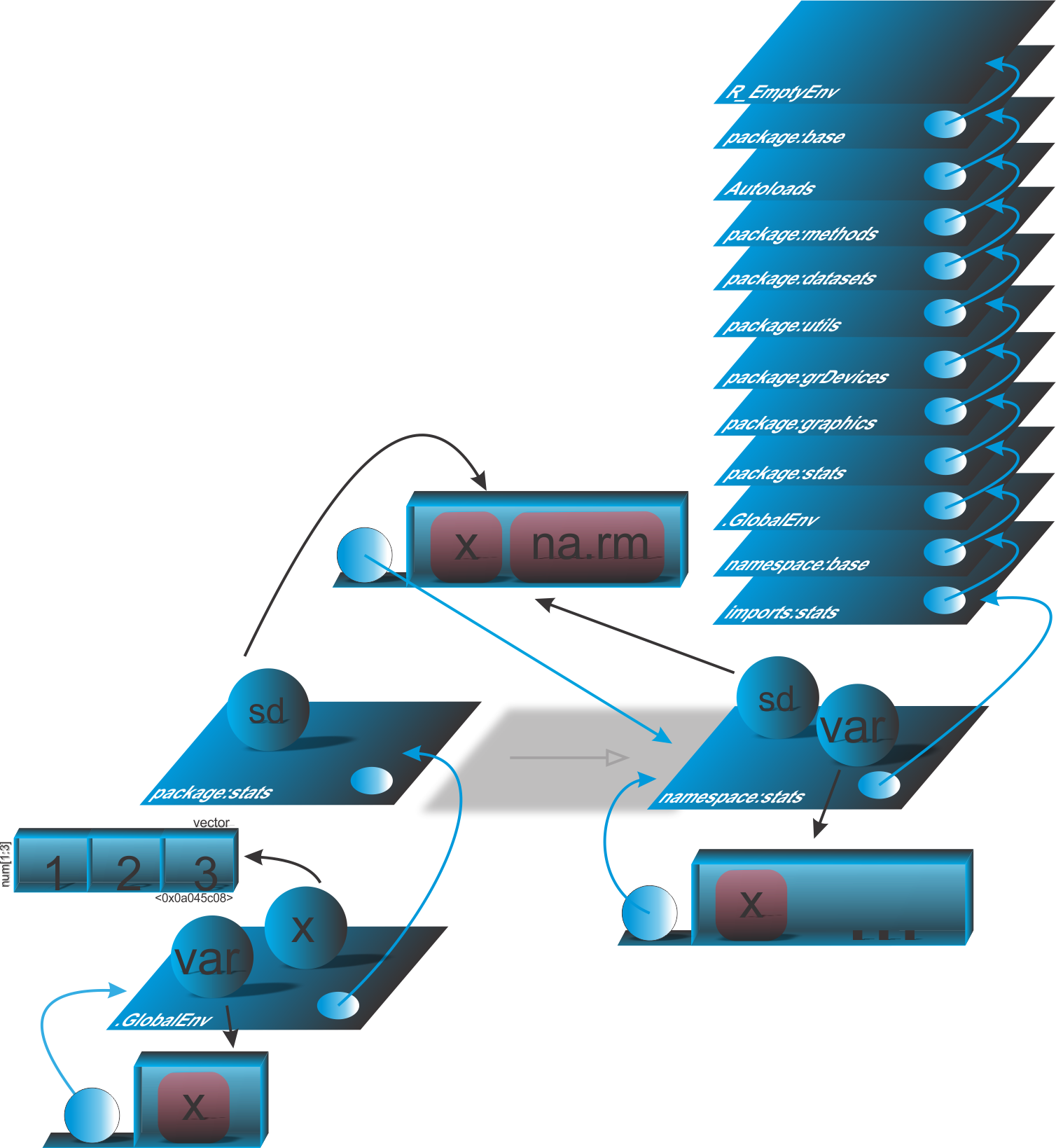
Figure 16: Mecanismo do ambiente namespace de um determinado pacote.
Observemos que quando a função sd() é chamada, esta função não foi criada no ambiente global, mas no ambiente namespace:stats, cujas ligações também estão no ambiente package:stats. Assim, após o ambiente de execução dessa função ser criada temporariamente, todos os seus objetos se não encontrados nesse ambiente, partirão à procura no ambiente namespace do pacote. Desse modo, até chegar a busca pelo objeto no ambiente global, a função ainda procurará pelo ambiente imports:stats, se não encontrar segue para o ambiente namespace:base, e por fim entra no caminho de busca. Portanto, a função var() criada no ambiente global, para ter sido usada, em todos os ambientes anteriores não poderia ter existido esse objeto. Porém, como o desenvolvedor do pacote planeja todas as suas funções, certamente, isso nunca ocorrerá. Desse modo, o ambiente R evita que as funções desenvolvidas em um pacote tenham conflito com funções de outros pacotes.
Programação funcional
Enfim, chegamos propriamente dito ao segundo princípio do R, tudo nesse ambiente é uma chamada de função. Mas lembrando que uma função é também um objeto, com suas características (atribuições) assim como os vetores também apresentam.
Parece não ser evidente, mas já pensaram quantas chamadas de função ocorrem na linha de comando a seguir?
x <- mean(1:10)
Apesar de intuitivo, mas o símbolo de atribuição (<-) é uma função, mean é outra função, : também, bem como (. Por fim, quando digitamos o nome x para verificar o resultado no console, por trás existe a função print trabalhando para isso. Por isso, dizemos que tudo no R é uma chamada de função.
Tanto no módulo básico quanto nesse módulo, já discutimos algumas propriedades importantes das funções, como o seu escopo léxico e dinâmico, a característica do ambiente R ter funções de primeira classe, os ambientes envolvidos em uma função, função anônima, dentre outros assuntos.
Discutimos também que uma função do tipo closure, apresenta três estruturas: os argumentos (formals()), o corpo (body()) e o ambiente (environment()). Porém, as funções primitivas, do tipo special ou buitin, fogem a essa regra porque foram implementadas em linguagem de baixo nível, isto é, em linguagem C. Já mostramos também como identificar essas funções nas seções anteriores, e todas elas se encontram no pacote base.
Compreendemos também que uma função é chamada quando ditamos o seu nome e entre parênteses inserimos os seus argumentos. Podemos também por meio, da função do.call(), repassar os argumentos por meio de uma lista, que segue:
argumentos <- list(x = 1:10, main = "Gráfico",
xlab = "Eixo X", ylab = "Eixo Y")
do.call(plot, argumentos)
Composição de funções
No módulo básico, também vimos a composição de funções, construídas em blocos, aninhadas, resultados intermediários como objetos. Mas, surge uma quarta via, implementada pelo pacote magrittr, que é o operador pipe. Essa ideia, segundo Wickham (2019), foi inspirada nas linguagens Haskell, F#, Julia, JavScript, um estilo baseado em pilhas como forth e Fator. Esse estilo apresenta uma estrutura mais fácil de sequências de operações da esquerda para direitra, evita funções aninhadas ou definição de funções. Para a análise de dados esse operador no ambiente R ganhou tanto respaldo, que foi implementado uma forma nativa na versão R 4.1. O operador pipe é binário, em que o primeiro operando (lhs) representa o valor do primeiro argumento do segundo operando (rhs), que representa uma função, isto é,
lhs %>% rhs # Pipe do pacote 'magrittr'
lhs |> rhs # Pipe nativo do pacote 'base'Uma tabulação básica para compreensão pode ser apresentada na Tabela
| Sintaxe | Equivalência |
|---|---|
x %>% f ou x |> f |
f(x) |
x %>% f(y) ou x |> f(y) |
f(x, y) |
x %>% f %>% g %>% h ou x |> f |> g |> h |
h(g(f(x))) |
Desse modo, podemos pensar em uma sequencia de comandos mais simples, até algo mais complexo. Vejamos o código a seguir.
mtcars |> head()
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1[1] 11
Call:
lm(formula = mpg ~ disp, data = d)
Coefficients:
(Intercept) disp
40.8720 -0.1351 Operadores binários ou unários
Na seção Manipulando vetores (Módulo básico), falamos sobre alguns operadores: matemáticos, lógicos, booleanos. Todos estes são operadores binários ou unários, que na mais são do que funções. Dizemos que um operador é unário quando há apenas a exigência de um operando na operação. Quando há a existência de dois operandos, dizemos que o operador é binário. Por exemplo, o operador soma + pode ser unário ou binário, pois sintaticamente, podemos escrever a operação soma com um operando ou com dois operandos. Vejamos o código a seguir.
# Como operador unario
+2 # operador operando1
[1] 2# Como operador binario
2 + 5 # operando1 operador operando2
[1] 7Isso significa dizer que o operador pipe é binário, em que o primeiro operando é um valor e o segundo operando é uma função. Alguns exemplos de operadores que também podem ser encontrados por ?Sintax, ::, :::, $, @, [, [[, ^, +, -, :, |>, %%, %/%, %*%, %x%, %o%, %in%, <, >, <=, =>, ==, !=, !, &, &&, |, ||, ~, ->, <-, <<-, =, ?, detre outros. Algumas dessas operações tem prevalência sobre outras, como por exemplo, no caso dos operadores matemáticos.
Para sabermos o código interno de um operador, além do nome, escrevemos aspas invertidas envolta desse nome, isto é,
[1] TRUEfunction (x, table)
match(x, table, nomatch = 0L) > 0L
<bytecode: 0x0000000006b0f2c0>
<environment: namespace:base>Uma outra forma de identificarmos se um operador é binário ou unário, é verificando os seus argumentos. Por exemplo, o operador %in% apresenta os argumentos x e table, então no mínimo esse operador é binário. Isso ocorre porque quando verificamos os argumentos do operador soma,
`+`
function (e1, e2) .Primitive("+")percebemos que há dois argumentos, e1 e e2, mas este operador pode se comportar como operador unário, é como se e1 fosse NULL por padrão. Uma outra forma sintática de chamarmos um operador pode ser apresentado a seguir.
`+`(e1 = 2, e2 = 5)
[1] 7Isso é o mesmo de termos realizado a operação 2 + 5. Operadores criados pelos usuários sempre terão o símbolo de porcentagem (%) envolta dos nomes. Os demais operadores que não apresentam essa forma sintática são criados apenas pelo R Core Team.
Para ilustrar a criação de um operador, vamos fazer o nosso próprio operador pipe.
# Nosso operador pipe '%>>%'
`%>>%` <- function(a, b) {
aux <- as.character(substitute(b))
exec <- call(aux, a)
eval(exec)
}
1:10 %>>% mean()
[1] 5.5Avaliação preguiçosa dos argumentos de uma função
Os argumentos em uma função são um tipo de objeto chamado pairlist, isto é,
esse tipo de objeto é avaliado de forma “preguiçosa,” isto é, lentamente. Isso significa dizer computacionalmente, que enquanto esse argumento não for utilizado internamente na função, ele é tipo como uma promessa e não é avaliado. Vejamos um exemplo para entendermos melhor essa afirmação.
f2 <- function(x = aux()) 10; f2()
[1] 10A chamada f2() retorna o valor 10 sem erros, porque mesmo no argumento x recebendo uma função aux() que não existe, como internamente esse argumento não foi usado, x é apenas uma promessa. No ambiente R, não podemos manipular esse tipo de objeto, pois se assim fosse possível, o objeto deixaria de ser uma promessa.
Por causa desse tipo de estrutura, que podemos ter outros argumentos padrão como função de outros argumentos ou até como função de outros objetos criados internamente a função. Vejamos,
f3 <- function(a = 4, b = a + 2, c = x * y) {
x <- 10
y <- 100
list(a = a, # 4
b = b, # a + 2
c = c) # x * y
}
f3()
$a
[1] 4
$b
[1] 6
$c
[1] 1000Nesse momento cabe enfatizarmos a diferença entre <- e =. Primeiro, devemos entender que qualquer um dos dois associam nomes a objetos, porém a primeira diferença existente entre os dois, é que o primeiro tem precedência superior. Vejamos o seguinte código:
y <- x = 4
Error in y <- x = 4: não foi possível encontrar a função "<-<-"Por que esse exemplo gera um erro? Porque primeiro é executado y <- x (precedência superior de <- sobre =), em que x não é encontrado, e retorna um erro.
Um outro ponto é que sintaticamente usamos o operador = para atribuir valores a argumentos de uma função, e <- para atribuir nomes a objetos, e este último deve ser a sintaxe recomendada para a atribuição de nomes a objetos.
Parece que semanticamente a atribuição de argumentos a valores são iguais, mas podemos ver que a seguir, apesar de sintaticamente as linhas de comando aparentemente idêntica, apresentam comportamentos e resultados diferentes
# Funcao teste
teste <- function(x = ls()) {
obj_ae <- "Objeto_interno"
x
}
# ls() avaliado dentro de teste():
teste()
[1] "obj_ae" "x" # ls() avaliado no ambiente de chamada:
teste(ls())
[1] "cran" "github" "rlink" "rstudio" "teste" teste2 <- function(){
obj_teste2_1 <- "primeiro"
obj_teste2_2 <- "segundo"
obj_teste2_3 <- "terceiro"
teste(ls())
}
teste2()
[1] "obj_teste2_1" "obj_teste2_2" "obj_teste2_3"# Objeto x avaliado no ambiente global
teste((x <- ls()))
[1] "cran" "github" "rlink" "rstudio" "teste" "teste2" teste((x <- ls()))
[1] "cran" "github" "rlink" "rstudio" "teste" "teste2"
[7] "x" Na primeira situação temos a criação da função teste com um argumento padrão x = ls(). Nesse caso, ls() será avaliado no ambiente de execução da função, do qual pode ser confirmado com a chamada teste(). O segundo caso, a chamada teste(ls()) apresenta um resultado diferente, porque ls(), nesse caso, foi avaliado no ambiente de chamada, que pode também ser verificado na chamada teste2(). Por fim, a chamada teste((x <- ls())) apresenta um resultado diferente com relação ao caso anterior, pois x <- ls() é avaliado no ambiente global, nesse caso, e não como um promessa tal como x = ls() foi, sendo avaliado apenas internamente no ato de sua chamada.
Por fim, podemos verificar se um argumento teve como entrada padrão, ou inserida pelo usuário, usando missing(). Vejamos o código, a seguir.
teste <- function(arg = 5) {
list("argumento padrão?" = missing(arg), valor = arg)
}
# Teste 1
teste()
$`argumento padrão?`
[1] TRUE
$valor
[1] 5# Teste 2
teste(4)
$`argumento padrão?`
[1] FALSE
$valor
[1] 4Saídas implícitas, explícitas, invisíveis de funções
No módulo Básico, mostramos a estrutura básica de como criar uma função, cujo corpo é delimitado por chaves, isto é,
nova_funcao <- function(x) {
# Corpo da funcao
x
}
Nesse caso, como a última linha de comando no corpo da função nova_funcao() a ser avaliada é x, então será esta o resultado da saída da função. Observamos que nesse caso, a última linha de comando imprime o valor de x. Dizemos nesse caso, que a função teve uma saída implícita. Se ao invés, a última linha de comando fosse a associação de um nome ao objeto, nada seria retornado após a chamada de função. Vejamos o próximo exemplo para o entendimento.
# Funcao com saida implicita
nova_funcao <- function(x) {
# Corpo da funcao
x
}
nova_funcao(2)
[1] 2# Funcao com saida implicita sem resultado
nova_funcao2 <- function(x) {
# Corpo da funcao
x <- x
}
nova_funcao2(4)
Essa última chamada, acaba não aparecendo nada porque a avaliação x <- x, associa o nome x ao valor do argumento x, e isto não implica em imprimir esse valor. Contudo, podemos não necessariamente, apresentar como resultado de uma função, a sua última linha de comando. Nesse caso, usamos a função return(), para identificar qual objeto desejamos como saída para uma determinada função. Nesse caso, temos uma saída explícita.
num_par_ou_impar <- function(x) {
if (!is.numeric(x)) stop("o argumento x deve ser numerico", call. = FALSE)
num <- as.integer(x)
if (num %% 2 == 0) {
return("Número par!")
} else return("Número ímpar!")
}
# Numero real eh coagido a inteiro sem arredondamento
num_par_ou_impar(1.6)
[1] "Número ímpar!"# Programacao defensiva (x deve ser numerico)
num_par_ou_impar(TRUE)
Error: o argumento x deve ser numerico# Verificando se um numero eh par ou impar
num_par_ou_impar(6)
[1] "Número par!"Percebemos que todas essas saídas implícita e explícita são saídas visíveis após a chamada da função. Porém, podemos ter saídas invisíveis, usando a função invisible(). Vejamos o código a seguir.
# Funcao com saida invisivel
estdes <- function(x) {
plot(x)
resumo <- summary(x)
invisible(resumo)
}
# Conjunto de dados
y <- rexp(30)
# Chamando estdes
res <- estdes(y)
# Imprimindo o resultado invisivel
res
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.01191 0.38730 0.83237 1.30549 1.78948 6.36918 # Formas alternativas
print(estdes(y))
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.01191 0.38730 0.83237 1.30549 1.78948 6.36918 (estdes(y))
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.01191 0.38730 0.83237 1.30549 1.78948 6.36918 # Sinalizador de visibilidade
withVisible(estdes(y))
$value
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.01191 0.38730 0.83237 1.30549 1.78948 6.36918
$visible
[1] FALSEstr(withVisible(estdes(y)))
List of 2
$ value : 'summaryDefault' Named num [1:6] 0.0119 0.3873 0.8324 1.3055 1.7895 ...
..- attr(*, "names")= chr [1:6] "Min." "1st Qu." "Median" "Mean" ...
$ visible: logi FALSEUm caso específico de função com resultado invisível é a atribuição (<-). Quando associamos um nome a um objeto, a saída dessa função é invisível, a menos que redigite o nome no console ou use entre parênteses essa linha de comando, isto é,
# Funcao `<-`() com saida invisivel
x <- 10
# Acessando o valor do obj associado com o nome 'x'
x
[1] 10# Outra forma de acesso
(x <- 10)
[1] 10Funções de substituição
Muito provavelmente, ao importar um banco de dados, armazenados em um objeto de classe data.frame, tivemos algum problema de erro em algum valor em nossas variáveis em estudo. Por exemplo, consideremos um banco de dados com informações de um grupo de pessoas, tais como o nome, altura (cm), peso (kg), idade (anos), que segue:
dados <- data.frame(
nome = c("Paulo", "Maria", "Caio"),
altura = c(175, 167, 172),
peso = c(70, 65, 7500),
idade = c(32, 26, 19)
); dados
nome altura peso idade
1 Paulo 175 70 32
2 Maria 167 65 26
3 Caio 172 7500 19Se esse banco foi importado, podemos alterar no próprio banco. Caso contrário, pode ser realizado uma substituição do valor no próprio ambiente R para o objeto específico, usando [, ou similares, dependendo do tipo de objeto. Para esse caso, percebemos que o peso de Caio (7500kg), muito provavelmente foi um erro de digitação, e e que na realidade seria 75kg como correção. Para fazermos essa alteração em dados, uma das possibilidades seria usar a função de substituição dados[3, 3] <- 75, em que a mudança ocorre na terceira linha e 3 coluna do data.frame. Como poderíamos criar uma função de substituição? Usando as mesmas ideias usadas nesse caso. A função de substituição para um caso geral, é dado da seguinte forma sintática:
`[<-` <- function(x, i, value){
# Corpo da funcao
}
# Chamada de funcao
x[i] <- value
# Chamada de forma equivalente
`[<-`(x, i, value)
Claro que isso não é um padrão, mas uma ideia geral para a chamada [<-, que basicamente deve ter dois argumentos, x e value. O primeiro é o objeto em que há a necessidade de substituição de um de seus valores, e o segundo representa o valor para a substituição. Argumentos adicionais a estes, devem ser colocados entre esses argumentos, e à esquerda do argumento value, que foi o caso do argumento i, que representa a posição do elemento a ser substituído no objeto x. Por outro lado, devemos evitar a substituição de funções internas, como no caso da função (<-, por exemplo, uma vez que funções como essas usadas a todo momento em um código, pode trazer conflitos entre essas funções.
Vamos aprofundar um pouco mais essa questão, usando um exemplo mais simples para a compreensão, a seguir.
# Vamos criar um vetor de comprimento 10
x <- 1:10; x
[1] 1 2 3 4 5 6 7 8 9 10# Usando a funcao de substituicao, para alterar
# dois valores na posicao 6 e 10
x[c(6, 10)] <- c(100, 200); x
[1] 1 2 3 4 5 100 7 8 9 200O que ocorre por trás, cuja referência pode ser confirmada no manual R Language Definition, seção 3.4.4, é que surge a criação de um nome temporário `*tmp*` que também se associa ao mesmo objeto associado ao nome x, cujas alterações são realizadas em `*tmp*`, e um novo objeto é criado e um novo nome se associa a ele, e para deixar a impressão de que a alteração é ocorrida no próprio objeto, esse novo nome é exatamente x, igual ao nome antigo.
# Objeto x criado
x <- 1:10
# `*tmp*` temporariamente criado
`*tmp*` <- x
# Alteracoes realizadas
x <- `[<-`(`*tmp*`, c(6, 10), valor = c(100, 200)); x
[1] 1 2 3 4 5 100 7 8 9 200# Ao final se remove `*tmp*`
rm(`*tmp*`)
Por fim, `*tmp*` é removido, e nesse caso, ocorre a cópia do objeto, como pode ser verificado por meio chamada tracemen(), isto é,
# Vamos criar um vetor de comprimento 10
x <- 1:10; x
## [1] 1 2 3 4 5 6 7 8 9 10
# Inspecionando o objeto
tracemem(x)
## [1] "<000000965C8A97D8"
.Internal(inspect(x))
## @0x000000965c8a97d8 13 INTSXP g0c0 [REF(65535),TR] 1 : 10 (compact)
# Usando a funcao de substituicao, para alterar
# dois valores na posicao 6 e 10
x[c(6, 10)] <- c(100, 200); x
## tracemem[0x000000965c8a97d8 - 0x000000965bdf6bc0]:
## tracemem[0x000000965bdf6bc0 - 0x000000965f177418]:
## [1] 1 2 3 4 5 100 7 8 9 200
# Inspecionando novamente o objeto
.Internal(inspect(x))
## @0x000000965f177418 14 REALSXP g0c5 [REF(5),TR] (len=10, tl=0) 1,2,3,4,5,...
Observamos inicialmente x (id 0x000000965c8a97d8), cujo nome `*tmp*` inicialmente se liga ao mesmo objeto, e após as substituições `*tmp*` passa a está alocado a um novo espaço de memória (id 0x000000965f177418), isto é ocorre uma cópia. A cópia intermediária (id 0x000000965bdf6bc0) que ocorre no processo é devido a chamada `. Mas a pergunta que fica, como fica o entendimento da otimização de desempenho especial a modificação no local? Bem, o nosso entendimento para o caso de vetores, como já mostrado anteriormente, a ideia estará sempre na contagem de referência. Já vimos, que para a chamada :`()`:`(), a primeira modificação realizada no objeto será modificação em cópia, pois REF(# > 1). Nesse caso, que foi o exemplo mostrado anteriormente, existe a presença de `*tmp*` por trás dos bastidores. Entretanto, quando o vetor é desenvolvido pela chamada c(), sabemos que a alteração do objeto ocorre em modificação no local, quando não alteraramos a dimensão do vetor, mas apenas os valores. Bem, o que indagamos é a existência ou não do nome temporário `*tmp*` no processo. Como falamos na seção em sobre cópia de objetos, afirmamos que um dos pré-requisitos para a modificação no local, é que o objeto só pode ter uma ligação, isto é, um nome associado ao objeto. E quando mostramos a forma sintática da função de substituição `[<- `(), percebemos que x e `*tmp*` se ligam ao mesmo objeto inicialmente, e assim, teoricamente deveria sempre haver cópia com a alteração de algum dos valores desse objeto. Desse modo, pressupomos que para esses casos de modificação no local, o processo seja um pouco diferente desse processo. Contudo, isso só ocorrerá para o caso da função de substituição primitiva ([<-), implementada em linguagem C. Quando desenvolvemos nossas próprias funções de substituição, aí sempre ocorrerá cópia na modificação.
Para desenvolvermos as nossas próprias funções de substituição apresentamos um exemplo, criando a função `substextr<-`(), a seguir.
# Funcao de substituicao de alterar os extremos
`substextr<-` <- function(x, value) {
x <- sort(x)
x[1] <- x[length(x)] <- value
x
}
# Criando o vetor
set.seed(10)
x <- rnorm(10)
# Inspecao
.Internal(address(x))
<pointer: 0x0000000025e3c8b0># Alterando o vetor
substextr(x) <- 100
# Inspecao
.Internal(address(x))
<pointer: 0x00000000248ffa28>Nesse caso, obrigatoriamente os dois argumentos básicos e com esses nomes são x e value, sendo que value deve ser sempre o último argumento. Caso, seja necessário adicionar mais argumentos, estes devem ser inseridos entre esses dois argumentos, como apresentado no código a seguir.
[1] 1 2 3# Inspecao
.Internal(address(x))
<pointer: 0x000000004153abe8># subst(x, i) <- value
subst(x, 2) <- 100; x
[1] 1 100 3# Inspecao
.Internal(address(x))
<pointer: 0x0000000041ee3990>Vetorização de funções
A vetorização de funções surge quando inserimos argumentos vetorizados, cuja saída dessas funções também são vetorizadas, de modo que não precisamos de loop para que a função retorne um valor de cada elemento do vetor de algum dos argumentos. Pensemos no operador soma (+), no seguinte código:
# Vetorização da soma de vetores
1:4 + 10:13
[1] 11 13 15 17Essa função é vetorizada porque ela realizou, porque ela realizou a soma entre dois elementos de mesma posição nos vetores, isto é,
1 2 3 4
+ + + +
10 11 12 13
------------
11 13 15 17Isso é como se tivéssemos realizado um loop para essa operação, da seguinte forma:
x <- 1:4
y <- 10:13
for (i in 1:4) {
print(x[i] + y[i])
}
[1] 11
[1] 13
[1] 15
[1] 17Grande maioria das funções nativas do R, isto é, das funções desenvolvidas nos pacotes nativos são vetorizados. Vejamos alguns exemplos:
# Funcao logaritmica
log(1:4)
[1] 0.0000000 0.6931472 1.0986123 1.3862944# Multiplicacao
10:20 * 5
[1] 50 55 60 65 70 75 80 85 90 95 100# Operadores logicos
1 == 1:4
[1] TRUE FALSE FALSE FALSE# Gerador de numeros aleatorios [0, 1]
runif(1:10)
[1] 0.50747820 0.30676851 0.42690767 0.69310208 0.08513597 0.22543662
[7] 0.27453052 0.27230507 0.61582931 0.42967153Existem diversos caminhos para se desenvolver uma função vetorizada. Caso as funções internas da função desenvolvida seja vetorizada, esta também será. Vejamos:
`%soma%` <- function(e1, e2) {
e1 + e2
}
# Exemplo 1
1:4 %soma% 10:13
[1] 11 13 15 17# Exemplo 2
1:4 %soma% 5
[1] 6 7 8 9Quando temos funções escalares, podemos em uma das possibilidades, utilizar a função Vectorize() para vetorizar a função desejada. Essa função tem três argumentos importantes, FUN que representa a função a ser vetorizada vectorize.args que representa os argumentos da função vetorizado, que devem entrar como vetores caracteres nesse argumento, e SIMPLIFY que é um argumento lógico, cujo valor TRUE representa uma saída em forma de matriz, dependendo da situação, e FALSE representa a saída em forma de lista. Argumentos padrão não são vetorizados.
Vamos usar como exemplo, a função que gera números aleatórios de uma distribuição normal, rnorm(n, mean, sd, log). Vamos trabalhar apenas com os três primeiros argumentos, em que n representa o tamanho da amostra, mean o parâmetro média e sd o parâmetro desvio padrão. Vamos fixar n = 10 e sd = 1, e variar mean = 1:3. Isto significa que iremos ter valores baseados em uma distribuição normal, tal que os valores \(X_i\), para \(i = 1, 2, \ldots, 10\), serão gerados de distribuições, tal que \(X_i \sim N(\mu_j)\), sequencialmente para \(\mu_1 = 1\), \(\mu_2 = 2\) e \(\mu_3\), respectivamente. Assim, teremos uma amostra de tamanho 10, da seguinte forma: \(X_1\sim N(1,1)\), \(X_2\sim N(2,1)\), \(X_3\sim N(3,1)\), \(X_4\sim N(1,1)\), \(X_5\sim N(2,1)\), \(X_6\sim N(3,1)\), \(X_7\sim N(1,1)\), \(X_8\sim N(2,1)\), \(X_9\sim N(3,1)\), \(X_{10}\sim N(1,1)\). Vejamos o código a seguir.
[1] 1.0187462 1.8157475 1.6286695 0.4008323 2.2945451 3.3897943
[7] -0.2080762 1.6363240 1.3733273 0.7435216Vamos supor agora, que a ideia de vetorização para essa função, seja que quando assumimos mean = 1:3, ao invés de termos uma amostra como a anterior, teremos três amostras baseadas no comprimento do vetor em mean. Fixado os demais argumentos, teremos uma amostra de uma normal para \(\mu_1 = 1\), \(\mu_2 = 2\) e \(\mu_3 = 3\), isto é,
\[
\left\{\begin{array}{ll}
X_1, X_2, \ldots, X_{10}, & X_i \sim N(1,1), \\
Y_1, Y_2, \ldots, Y_{10}, & Y_i \sim N(2,1), \\
Z_1, Z_2, \ldots, Z_{10}, & Z_i \sim N(3,1).
\end{array}\right.
\] Para isso, iremos usar Vectorize() para rnorm(), vetorizando o argumento mean. Vejamos o código a seguir, para essa implementação.
# Apos a vetorizacao, observe a diferenca entre
# 'rnorm_vet1' e 'rnorm_vet2', devido ao argumento
# 'SIMPLIFY'
rnorm_vet1 <- Vectorize(rnorm, "mean", SIMPLIFY = FALSE)
rnorm_vet2 <- Vectorize(rnorm, "mean", SIMPLIFY = TRUE)
# Vetorizando
set.seed(10) # semente para fixar os mesmos valores
rnorm_vet1(n = 10, mean = 1:3)
[[1]]
[1] 1.0187462 0.8157475 -0.3713305 0.4008323 1.2945451 1.3897943
[7] -0.2080762 0.6363240 -0.6266727 0.7435216
[[2]]
[1] 3.101780 2.755782 1.761766 2.987445 2.741390 2.089347 1.045056
[8] 1.804850 2.925521 2.482979
[[3]]
[1] 2.4036894 0.8147132 2.3251341 0.8809388 1.7348020 2.6263384
[7] 2.3124446 2.1278412 2.8982390 2.7462195set.seed(10) # semente para fixar os mesmos valores
rnorm_vet2(n = 10, mean = 1:3)
[,1] [,2] [,3]
[1,] 1.0187462 3.101780 2.4036894
[2,] 0.8157475 2.755782 0.8147132
[3,] -0.3713305 1.761766 2.3251341
[4,] 0.4008323 2.987445 0.8809388
[5,] 1.2945451 2.741390 1.7348020
[6,] 1.3897943 2.089347 2.6263384
[7,] -0.2080762 1.045056 2.3124446
[8,] 0.6363240 1.804850 2.1278412
[9,] -0.6266727 2.925521 2.8982390
[10,] 0.7435216 2.482979 2.7462195As únicas funções que não podem ser vetorizadas por Vectorize() são as funções primitivas que não tem um valor para formals().
Uma outra forma de vetorizar funções, por exemplo, bem como evitar loops no desenvolvimento de algoritmos, é utilizar um conjunto de funções da família apply implentadas no pacote base, que será vista a seguir.
Funções da família apply
Apesar de uma das construções mais interessantes na programação, seja o loop, é bom observar que essas construções implementadas em diversas linguagens apresenta grandes diferenças, em termos de desempenho. Já vimos que as funções para loops no R pode demandar um gasto computacional dependendo de sua implementação, cópias na modificação, por ser uma linguagem interpretada, dentre outras características. Alternativamente, podemos usar uma série de funções implementadas no ambiente R, funções estas vetorizadas. Vamos nos concentrar nas funções disponíveis na Base R.
Iniciamos com a família de funções apply, pertencente ao pacote base, de modo que permite manipularmos estruturas de dados como vetores, matrizes, arrays, listas e quadro de dados (data frames) de maneira repetitiva sem a utilização de loop. Estas funções são: apply(), lapply(), sapply(), tapply(), mapply(), rapply() e eapply()
A primeira função a ser discutida é apply(), que retorna um array ou uma lista obtida pela aplicação de uma função nas linhas ou colunas da entrada de um objeto seja matriz ou array. Vejamos a sintaxe dessa função:
apply(X, MARGIN, FUN, ..., simplify = TRUE),em que: - X argumento que recebe o objeto matriz ou array, - MARGIN argumento que recebe 1, se a função em FUN deve ser aplicado na linha, ou recebe 2 se FUN deve ser aplicado nas colunas, - FUN argumento que recebe a função desejada, - ... argumento que recebe argumentos adicionais para FUN, e - simplify argumento lógico para retorno de resultados simplificados (TRUE) ou não (FALSE).
Por exemplo, supomos que temos 5 amostras de tamanho 10, com reposição, em um conjunto de valores de 1 a 1000, e desejamos computar a média aritmética dessas amostras, que serão inseridas em colunas num objeto matriz, isto é,
# 5 amostras
(am1 <- sample(x = 1:1000, size = 10, replace = TRUE))
[1] 42 334 13 417 361 729 712 656 373 26(am2 <- sample(x = 1:1000, size = 10, replace = TRUE))
[1] 857 209 48 663 527 958 878 536 482 317(am3 <- sample(x = 1:1000, size = 10, replace = TRUE))
[1] 132 739 270 929 35 266 74 570 679 912(am4 <- sample(x = 1:1000, size = 10, replace = TRUE))
[1] 271 543 906 101 435 437 959 613 621 943am5 <- sample(x = 1:1000, size = 10, replace = TRUE)
# Amostras em colunas
amost_col <- matrix(c(am1, am2, am3, am4, am5), 10, 5); amost_col
[,1] [,2] [,3] [,4] [,5]
[1,] 42 857 132 271 39
[2,] 334 209 739 543 947
[3,] 13 48 270 906 630
[4,] 417 663 929 101 89
[5,] 361 527 35 435 530
[6,] 729 958 266 437 899
[7,] 712 878 74 959 982
[8,] 656 536 570 613 554
[9,] 373 482 679 621 394
[10,] 26 317 912 943 254# Calculando a media por coluna
apply(X = amost_col, MARGIN = 2, FUN = mean)
[1] 366.3 547.5 460.6 582.9 531.8# Amostras em linhas
amost_lin <- matrix(c(am1, am2, am3, am4, am5), 5, 10, byrow = TRUE); amost_lin
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 42 334 13 417 361 729 712 656 373 26
[2,] 857 209 48 663 527 958 878 536 482 317
[3,] 132 739 270 929 35 266 74 570 679 912
[4,] 271 543 906 101 435 437 959 613 621 943
[5,] 39 947 630 89 530 899 982 554 394 254# Calculando a media por linhas
apply(X = amost_lin, MARGIN = 1, FUN = mean)
[1] 366.3 547.5 460.6 582.9 531.8# Podemos tambem adicionar argumentos adicionais
# em FUN (Media truncada em 10%)
apply(X = amost_lin, MARGIN = 1, FUN = mean, trim = 0.1)
[1] 365.125 558.625 455.250 596.125 537.125# Usando o argumento simplify, o default: simplify = TRUE
apply(X = amost_lin, MARGIN = 1, FUN = mean, simplify = FALSE)
[[1]]
[1] 366.3
[[2]]
[1] 547.5
[[3]]
[1] 460.6
[[4]]
[1] 582.9
[[5]]
[1] 531.8A próxima função é lapply(), com sintaxe:
lapply(X, FUN, ...),em que: - X argumento que recebe uma lista; - FUN argumento que recebe a função desejada, e - ... argumento que recebe argumentos adicionais para FUN.
Vejamos que a sintaxe desta função é muito parecido com apply(). Vejamos alguns exemplos, a seguir.
# Vetor (nao faz muito sentido)
lapply(1:10, mean)
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] 4
[[5]]
[1] 5
[[6]]
[1] 6
[[7]]
[1] 7
[[8]]
[1] 8
[[9]]
[1] 9
[[10]]
[1] 10$x
[1] 5.5
$y
[1] 15.5$x
[1] 2
$y
[1] 12$mat1
[1] 5 6 7 8A função seguinte é sapply(), que é um invólucro (wrapper) da função lapply(), e o acréscimo sintátivo do argumento padrão simplify = TRUE. Assim, a forma sintática dessa função, segue:
sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE),em que: - X argumento que recebe uma lista; - FUN argumento que recebe a função desejada; - ... argumento que recebe argumentos adicionais para FUN; e - simplify, argumento lógico, se TRUE retorna o resultado de forma simplificada, sendo um vetor atoômico, matriz ou array; se FALSE o retorno é uma lista; - USE.NAMES, argumento lógico; se TRUE é retornado o nome inserido nos objetos da lista; se FALSE, caso contrário.
Na realidade, o que essa função faz é melhorar a saída de lapply(), retornando um vetor, matriz ou array. Vejamos,
[[1]]
[1] 5.5
[[2]]
[1] 15.5[1] 5.5 15.5# 'simplify = FALSE' em 'sapply()' eh equivalente a 'lapply()'
sapply(list(1:10, 11:20), mean, simplify = FALSE)
[[1]]
[1] 5.5
[[2]]
[1] 15.5Uma forma multivariada da função apply, é a função mapply(), com sintaxe:
mapply(FUN, ..., MoreArgs = NULL, SIMPLIFY = TRUE,
USE.NAMES = TRUE)
em que: - FUN argumentos que recebe a função desejada; - ... argumentos para vetorização; - MoreArgs uma lista com argumentos adicionais a FUN; - SIMPLIFY, argumento lógico, se TRUE retorna o resultado de forma simplificada, sendo um vetor atoômico, matriz ou array; se FALSE o retorno é uma lista; - USE.NAMES, argumento lógico; se TRUE é retornado o nome inserido nos objetos da lista; se FALSE, caso contrário.
Vejamos alguns exemplos de aplicação, a seguir.
x y
5.5 15.5 [1] 5.5 15.5mapply(FUN = rep, x = 1:4, times = 1:4)
[[1]]
[1] 1
[[2]]
[1] 2 2
[[3]]
[1] 3 3 3
[[4]]
[1] 4 4 4 4mapply(FUN = rep, x = 1:4, times = 4)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 1 2 3 4
[3,] 1 2 3 4
[4,] 1 2 3 4[[1]]
[1] 4
[[2]]
[1] 4 4
[[3]]
[1] 4 4 4
[[4]]
[1] 4 4 4 4Um outro exemplo interessante usando mapplay(), suponha que temos um conjunto de dados 1:38 e desejamos reamostrar com reposição 10 amostras de mesmo comprimento desses dados. Nesse caso, temos:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 15 13 14 31 23 29 18 1 32 25
[2,] 13 6 30 17 1 24 31 37 36 35
[3,] 26 37 27 37 37 5 37 21 7 7
[4,] 14 12 10 24 19 25 33 22 25 10
[5,] 28 32 8 7 25 32 20 26 3 23
[6,] 4 31 6 27 6 14 35 4 31 15
[7,] 31 4 5 14 33 13 19 35 37 28
[8,] 20 24 9 10 14 11 27 18 9 14
[9,] 29 21 18 6 30 22 25 12 11 24
[10,] 3 18 15 34 15 1 17 24 18 6
[11,] 23 38 16 4 7 28 21 36 15 37
[12,] 17 23 17 1 10 19 10 30 16 18
[13,] 16 17 23 20 31 7 13 27 21 5
[14,] 32 11 38 13 2 4 34 38 29 32
[15,] 22 1 32 21 17 20 5 2 35 11
[16,] 30 34 33 8 4 33 6 6 38 12
[17,] 9 14 13 35 22 2 4 20 30 21
[18,] 36 15 21 32 35 16 23 33 20 4
[19,] 21 28 3 2 28 15 9 8 23 19
[20,] 24 36 25 38 11 21 29 17 28 29
[21,] 38 7 12 30 34 23 36 29 2 33
[22,] 27 2 34 18 29 27 28 7 17 36
[23,] 6 20 29 15 5 31 14 28 13 27
[24,] 10 33 36 22 24 35 22 13 5 26
[25,] 7 35 26 12 9 17 8 32 34 13
[26,] 19 22 22 28 36 10 2 15 26 17
[27,] 8 30 37 16 38 9 24 9 24 38
[28,] 37 25 2 36 26 12 12 16 10 30
[29,] 33 29 24 9 12 8 3 31 8 3
[30,] 34 8 31 11 18 38 7 34 14 31
[31,] 11 27 35 3 16 30 1 3 1 9
[32,] 25 19 19 23 27 36 26 14 19 1
[33,] 12 10 7 25 13 3 11 25 12 34
[34,] 35 3 28 29 21 37 32 10 27 20
[35,] 18 16 20 33 3 34 30 23 6 8
[36,] 2 5 4 26 32 6 38 5 4 2
[37,] 5 9 11 19 20 18 15 11 22 22
[38,] 1 26 1 5 8 26 16 19 33 16Poderíamos estar interessados também em gerar 10 amostras de tamanho \(n = 30\), de uma distribuição normal padrão, isto é,
[,1] [,2] [,3] [,4] [,5]
[1,] 0.97693997 1.02159557 0.128783463 -1.8656023 -1.70899030
[2,] 0.79023781 0.35895923 1.972929865 -0.3264478 0.58183916
[3,] 0.98468618 1.25387555 -0.071548470 0.4604034 0.36406946
[4,] 1.72802155 0.70613372 0.662564612 -0.3511606 1.51223372
[5,] -0.12590361 -1.94721263 -0.021996069 0.7167607 0.19003523
[6,] 2.53435299 -0.11707933 -0.316477912 -0.2088030 0.57913457
[7,] -0.43306272 0.17854140 0.002216812 1.2765002 0.05312193
[8,] 0.05448099 -0.88326729 0.518168763 -1.1883914 0.92380619
[9,] 0.21240835 -0.80757517 1.052712115 -1.7137380 0.14522949
[10,] -0.89938361 0.10100343 1.860744440 -1.9561878 -0.88649435
[11,] -1.37565361 1.46412309 -0.572562971 -1.3176539 0.37985772
[12,] -0.72000035 -0.10547712 -1.116260285 0.4809290 -0.94199625
[13,] 0.57103300 -1.79153520 -0.943473638 0.1418312 -0.48406717
[14,] -2.22797642 0.54351301 -2.224035530 -0.2452919 -0.23334446
[15,] -0.46067194 0.31409270 1.451927428 -1.0040025 0.51127182
[16,] 0.28035150 0.50664013 -1.956099422 0.1515346 0.68847089
[17,] 1.21989163 -0.86584165 -1.014548722 -0.5758454 -0.05936718
[18,] 0.49560734 2.70818206 0.039335338 -0.9516940 -0.69619877
[19,] -0.74053951 -0.88611149 0.806803554 0.6059419 1.95999846
[20,] 0.10386793 0.52069801 -0.524917117 -0.5905524 0.15963178
[21,] 0.77818514 -1.23173443 0.034003567 0.3728825 -0.65101808
[22,] -0.35034355 0.80405233 0.529471098 -1.6821377 -0.16582689
[23,] -1.18489995 1.17219691 1.580699421 -0.3354433 0.78029604
[24,] -0.54906948 0.80655250 -0.097312740 -0.7440138 0.68289313
[25,] -0.35041622 -1.72356712 -0.883009480 0.5024655 -0.93243155
[26,] -0.03310228 -0.14579650 0.920582123 -0.3672830 -1.44286488
[27,] -0.38794160 -1.80357911 0.023514388 -1.0183745 -0.15500192
[28,] -0.48037026 -0.23600588 -0.909644168 0.7085347 -0.51796180
[29,] -0.31829568 -1.18294347 0.423339689 1.4669889 -0.18665527
[30,] -0.89372404 -0.07234726 -0.504172213 1.2324449 1.14898546
[,6] [,7] [,8] [,9] [,10]
[1,] -0.76589869 -1.24022859 0.10728058 -0.39812103 -0.57176892
[2,] 0.68909301 -0.43904601 -0.27361986 0.71432097 -2.16851673
[3,] -0.47754641 0.92465389 -1.15852151 -0.80001178 0.17681026
[4,] 1.74790082 0.48999988 -2.30646600 0.20796708 1.79055424
[5,] 1.61613864 -0.12520464 2.05624855 1.30804130 0.59392193
[6,] -0.67747280 1.90371182 -0.04554368 -0.46294655 -0.76027132
[7,] -1.06211418 0.55390832 0.48959405 -0.56138541 -0.55642984
[8,] 0.88842467 0.02452472 2.08249472 -0.74300563 -0.64327472
[9,] -1.19553994 -0.43558701 2.15266415 0.56601182 -0.72255975
[10,] 1.42369200 -0.84270375 -0.88377944 0.05779672 0.01210588
[11,] -0.20078225 0.78824154 -0.29569873 0.26355651 0.96129385
[12,] 1.32816470 0.30441382 -1.48067015 -0.42854656 -0.95542144
[13,] 2.23539357 -0.73057805 0.71599300 -1.35961592 0.90466367
[14,] 0.34765519 0.07554207 -0.32544876 -0.06506061 0.34902954
[15,] 2.00349064 0.18755286 -0.48025235 -0.32217859 1.99607943
[16,] -1.20741971 1.54888307 -0.40743851 0.65078507 0.22416550
[17,] -0.11984656 0.73348814 -0.33567896 0.97817838 -0.05739319
[18,] 1.23060416 -0.98774829 1.02588074 2.56431606 0.04200018
[19,] -0.44432912 -1.34502211 -0.62750548 -0.69717728 0.59820545
[20,] 0.06629581 1.12057047 0.14214881 0.84131378 -1.21963884
[21,] -1.82850943 2.08816534 1.29126052 0.65903314 0.54559975
[22,] 0.34204225 -0.76044637 0.31021144 0.64665078 -0.73589761
[23,] 1.03675412 -0.21056316 0.33648561 -0.93036920 -2.43940646
[24,] 0.24952543 -0.95743964 -0.86197071 -0.84909779 -1.04992151
[25,] 0.19481959 -1.39402542 -0.36652510 -0.12281368 0.79303164
[26,] 0.06435280 0.26600553 -0.40975408 -0.30369010 -0.72705396
[27,] -0.59126036 0.58662393 -1.71986196 -0.91213787 -0.90122029
[28,] 1.23259700 0.07286590 0.92255632 -0.44223852 0.25348310
[29,] 0.50179363 -0.04643838 0.98709908 -1.78985673 -0.83447270
[30,] -0.68551424 -0.14572402 -1.07541152 1.60283488 -0.74985132- Outras funções:
by(),aggregate(),simplify2array(),ave(),replicate(),outer()
Funções recursivas
Recall()local()
Programação defensiva
Exemplo
Função stop()
Função Warning()
Projetos no RStudio
Projetos R no Github
Introdução a desenvolvimento de pacotes
Banco de dados e APIs, SQL
Criação de documentações no R
Documentos Web (estatística e dinâmica)
Páginas de pacote (pkgdown)
Livros (bookdown)
Blogs e websites (distill, blogdown)
Documentos (PDF, WORD, EPUB)
Documentos estatísticos
Documentos animados
Relatórios dinâmicos
