1Definições Gerais da Estatística e técnicas de somatórios
1.1 Introdução
Em pleno século XXI, passamos por um processo de transformação na era digital. Uma grande massa de informações surge instantaneamente a cada momento sobre os mais diversos temas possíveis. Por exemplo, nas redes sociais quando percebemos o número de curtidas de uma determinada declaração, número de downloads de um determinado vídeo, a repercussão que determinada declaração proporciona, o número de propagandas, etc, tudo isso cria um grande banco de dados sobre os usuários, que hoje se torna mais valiosa do que a própria moeda local. Isso é a nova revolução chamada “Big Data”. Por meio de grande banco de dados, podemos por exemplo, traçar um perfil dos usuários, como eles se comportam, quais as suas preferências, escolhas, diversão, etc. Contudo, o entendimento dessas informações podem não ser tão claras, ou devido a complexidade do problema, ou pela quantidade de informações recebidas rapidamente, ou outros fatores. Diversos outros exemplos poderiam ser citados, tudo isso para mostrar a necessidade de entender o que está por trás desses dados, cuja compreensão é o grande objetivo nessa era global.
Nesse enfoque, temos a Estatística como Ciência que fornece métodos para coleta, organização, descrição, análise e interpretação de dados (observacionais ou experimentais) e para a utilização dos mesmos na tomada de decisões. Os dados são informações retiradas de um conjunto de elementos de interesse. Podemos estar interessados na Produção anual de Gás Natural Não associado com o petróleo (GASN) de um determinado país, e ao longo dos anos, coletarmos informações para ao final, por exemplo, termos informações que nos indique o potencial energético desse recurso natural nesse local ou consequências dessa fonte energética na economia do país.
Assim, por meio da utilização de técnicas estatísticas, tentamos entender as informações contidas nos dados. Devido a complexidade dessas informações em algumas situações, o estudo sobre essas técnicas têm aumentado, fazendo parte do nosso cotidiano. Nessa era digital, a grande quantidade de informações é gigantesca e valiosa, e as empresas tentam entender o que está por trás desses dados, ou você acha que o Facebook foi criado simplesmente para gerar entreterimento às pessoas? Ou você também acha que o Google criou uma plataforma de pesquisa simplesmente para facilitar a vida das pessoas? Algo muito nobre está por trás de tudo isso, os dados.
No passado, tratar uma grande massa de números era uma tarefa custosa e cansativa, que exigia horas de trabalho tedioso. Porém, hoje, esse volume de informações pode ser analisado rapidamente por meio de um computador pessoal e programas adequados. O computador contribui positivamente na difusão e uso dos métodos estatísticos. Você já se perguntou como é que lojas virtuais lhe oferta produtos sendo que nunca acessou aquele site antes? Já percebeu que o Netflix quando lhe oferece uma série a tela de entrada as vezes se altera? Tudo isso é fruto das técnicas de máquinas de aprendizagem (do inglês, Machine Learning), uma área da inteligência artificial. Juntamente com a estatística, essas ferramentas estão presentes em várias das tecnologias que utilizamos hoje.
1.2 Definições gerais da Estatística
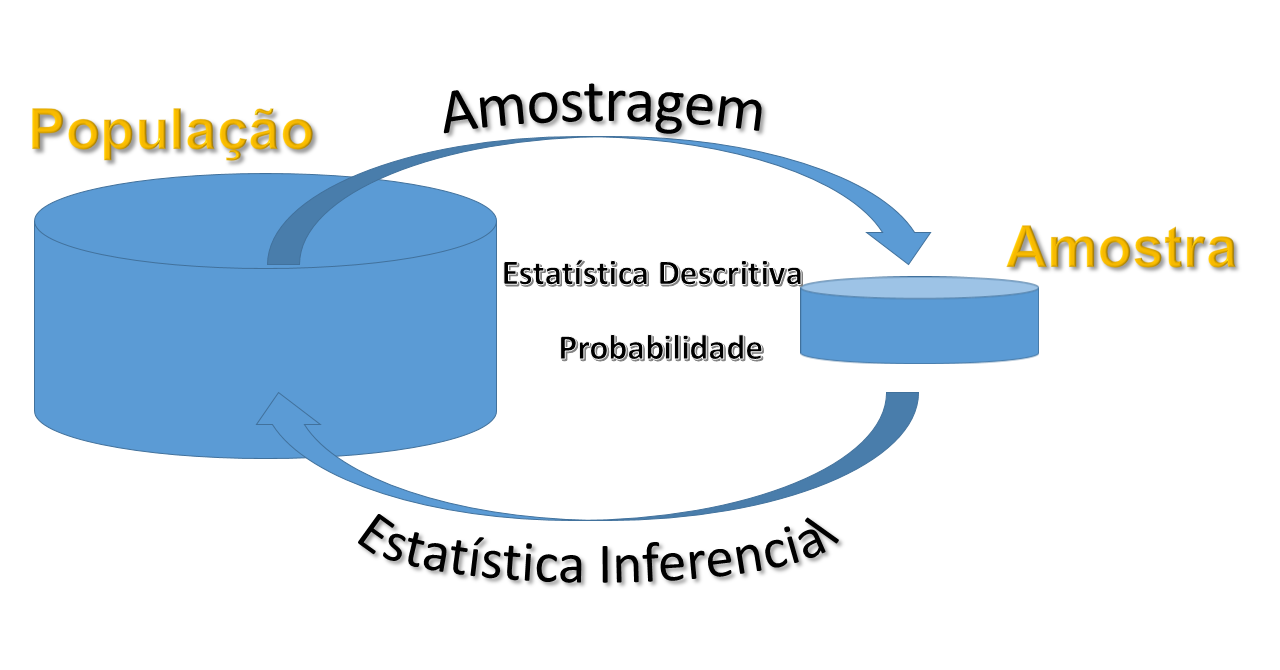
Inicialmente, podemos dividir a Estatística em três ramos:
Estatística Descritiva;
Probabilidade;
Estatística Inferencial.
Definimos cada uma dessas áreas a seguir. A primeira delas é a Estatística Descritiva, apresentada na Definição 1.1.
Definição 1.1: Estatística Descritiva ou Estatística Dedutiva
Um conjunto de técnicas estatísticas destinadas a coleta, descrição e sintetização dos dados, a fim de podermos entender características de interesse da população1, é chamada de Estatística Descritiva ou Estatística Dedutiva.
As técnicas mencionadas na Definição 1.1 são: coleta, organização, tabulação, representação gráfica, bem como medidas que sintetizam todas as informações contidas nos dados.
As quatro primeiras técnicas serão abordadas no Capítulo 2. As medidas serão estudadas nos Capítulo 3 e Capítulo 4. Essa fase é de grande relevância, pois com base na Estatística Descritiva podemos sintetizar as informações contidas nos dados, e torná-las mais compreensíveis que de outro modo seriam complexas de serem entendidas.
No Capítulo 7, daremos uma maior ênfase sobre a definição de uma população. De modo simples, podemos definir como um conjunto de elementos com uma característica em comum. Uma vez definida a característica que delimita essa população (subseção1.3), e também a característica de interesse (chamada de variável) da pesquisa, faremos a coleta dos valores observados da variável em cada elemento da população ou de um subconjunto (amostra). Os valores observados são chamados de dados.
Definição 1.2: Dado ou valor observado
A característica de interesse observada em cada elemento da população é definida como valor observado ou dado.
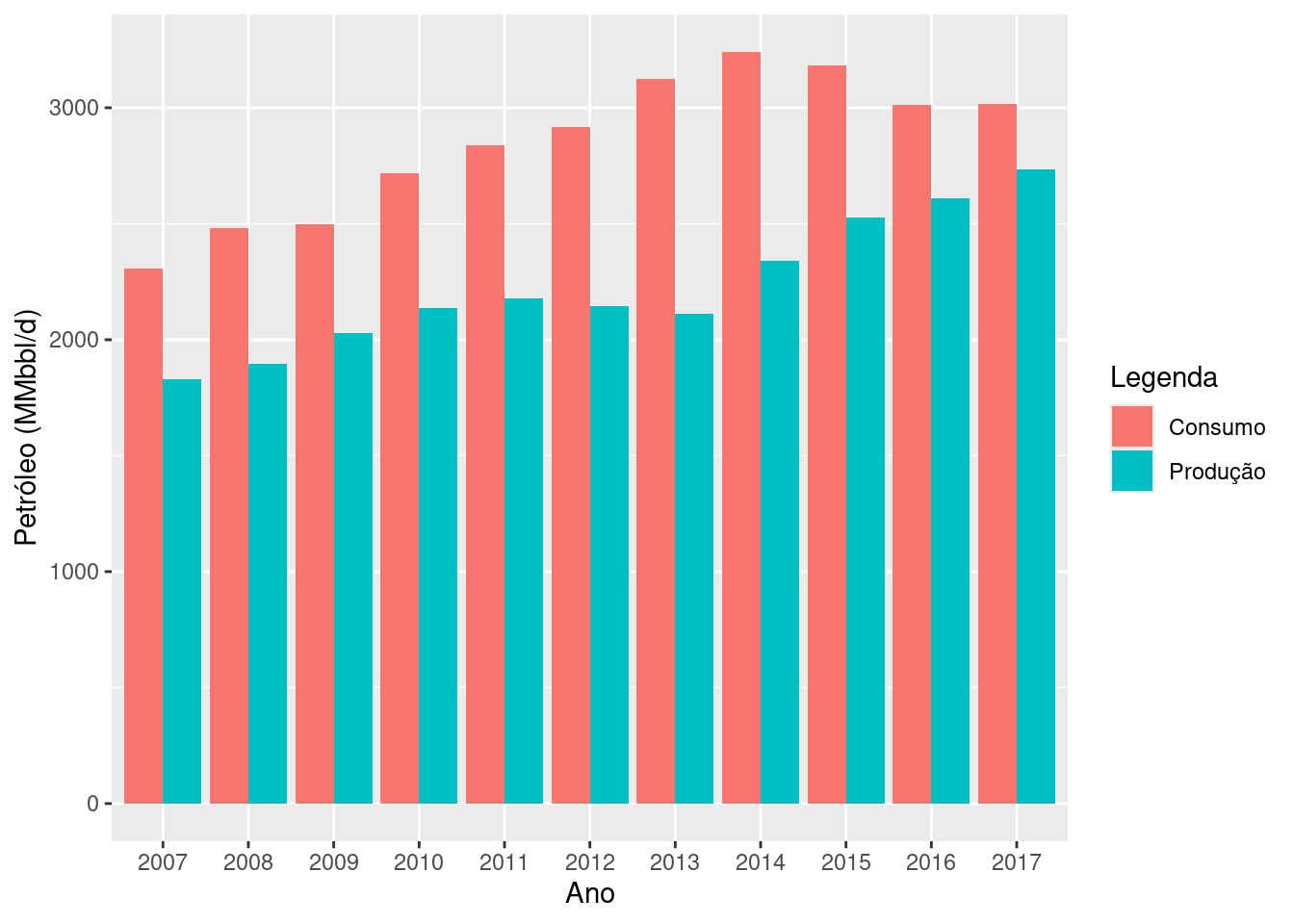
Todas as técnicas mencionadas anteriormente auxiliam na descrição dos dados, uma não necessariamente sobrepõe a outra. Vejamos, a Company (2018) lançou o relatório técnico de 2018 sobre os diversos tipos de produção de energias dos países, e na Figura 1.1 é mostrado um gráfico que sintetiza a produção e o consumo de petróleo do Brasil, em milhões de barris por dia (MMbbl/d), nos períodos de 2007 a 2017.
# BP Statistical Review 2018# Anexando pacotelibrary(ggplot2)# Se nao existir o pacote, use#install.packages("ggplot2")# Producao e consumo de petroleo no brasil (Mtoe)ano <-as.factor(c(2007:2017, 2007:2017))prodcons <-c(1831, 1897, 2029, 2137, 2179, 2145, 2110, 2341, 2525, 2608, 2734,2308, 2481, 2498, 2716, 2839, 2915, 3124, 3242, 3181, 3013, 3017)id <-c(rep("Produção", 11), rep("Consumo",11))# Objeto que armazena as informacoesdados <-data.frame(ano, Legenda = id, prodcons)# Funcao para criacao do grafico de barrasggplot(dados, aes(x = ano, y = prodcons, fill = Legenda)) +geom_bar(position ="dodge", stat ="identity") +xlab("Ano") +ylab("Petróleo (MMbbl/d)")
Figura 1.1: Produção e consumo de petróleo do Brasil nos períodos de 2007 a 2017.
O gráfico nos revela que o Brasil produz petróleo abaixo do que necessitaria para o consumo, de tal modo que a produção é 27,71% a menos do que o consumo. Isso explica o porquê do Brasil como grande produtor de petróleo, ainda assim, necessita importar essa fonte de energia. Contudo, o gráfico não apresenta um resumo perfeito. Por exemplo, mesmo a produção de petróleo sendo mais baixa do que o consumo, o coeficiente de variação (assunto abordado no Capítulo 4 dessas dessas duas variáveis, são 12,99% e 10,93%, respectivamente, calculados de acordo com a Tabela 1.1. Isso implica, que as variações da produção de petróleo são maiores do que as do consumo, no Brasil. Observe que essas últimas informações não podem ser vistas facilmente na Figura 1.1, mas juntamente com o auxílio das medidas numéricas (medidas de posição e dispersão) e as medidas gráficas, podemos complementar as informações, e assim, obter uma melhor descrição sobre essas informações.
Tabela 1.1: Produção e consumo de petróleo do Brasil nos períodos de 2007 a 2017.
(a) Dados de 2007 a 2012
Ano
2007
2008
2009
2010
2011
2012
Produção
1831
1897
2029
2137
2179
2145
Consumo
2308
2481
2498
2716
2839
2915
(b) Dados de 2013 a 2017
Ano
2013
2014
2015
2016
2017
Produção
2110
2341
2525
2608
2734
Consumo
3124
3242
3181
3013
3017
Quando precisamos estender as informações contidas em um subconjunto (amostra) de dados para todo o conjunto (população), necessitamos de técnicas específicas dentro da estatística para garantir que estas informações sejam o mais verossímil possível. Técnicas estas são chamadas de Estatística Inferencial, definida a seguir.
Definição 1.3: Estatística Inferencial ou Estatística Indutiva
O estudo de técnicas que visam estender (extrapolar) a informação contida na amostra à população, chamamos de Estatística Inferencial ou Estatística Indutiva.
As técnicas abordadas na Estatística Inferencial estão relacionadas a determinar características (parâmetros) populacionais desconhecidas, ou até mesmo fazer afirmações sobre esses parâmetros.
A determinação de parâmetros por meio de características amostrais (estimadores) que chamamos de Estimação será abordado no Capítulo 9. As afirmações realizadas sobre estes parâmetros, chamadas de hipóteses, e serão estudadas no Capítulo 10.
A Definição 1.3 nos mostra que por meio da Estatística, podemos tomar decisões sobre uma população através da amostra. Isso se faz necessário muitas vezes em uma pesquisa, devido a duas coisas preciosas: tempo e dinheiro. Muito embora, se tivermos acesso a todos os elementos de uma população, não se faz necessário o uso de técnicas da inferência estatística, e daí realizamos o que chamamos de Censo.
A forma de como se obter uma amostra é um dos passos mais importante em todo o processo da análise, uma vez que não adianta está com todo o aparato técnico se as informações contidas nessas amostra não são representativas da população. Para isso, temos uma área na estatística chamada Amostragem, que será responsável pelo desenvolvimento de métodos de como selecionar os elementos populacionais para compor a amostra de modo que as principais características contidas na população sejam preservadas na amostra. Esse assunto será estudado no Capítulo 7.
Contudo, sabemos que entender uma população por um subconjunto desta, gera-se uma incerteza ou erro. A estatística tenta minimizar esse erro o máximo possível, isto é, reduzir as incertezas das informações contidas na amostra e extrapolar essas informações para a população. Para isso, usamos a probabilidade como suporte, assunto estudado nos Capítulos 5, 6 e 8.
Definição 1.4: Probabilidade
A teoria matemática que estuda a incerteza de fenômenos aleatórios é chamada de probabilidade.
Os fenômenos aleatórios estão relacionados a situações que dificilmente saberemos com certeza do que pode acontecer. Por exemplo, se arremessarmos um dado de seis faces de tamanhos iguais e desejarmos saber a face superior desse dado antes do arremesso, não temos como afirmar com certeza qual o valor, se considerarmos as faces numerados de 1 a 6. Observe que, mesmo sabendo quais os valores das faces, não podemos afirmar com exatidão qual o valor da face superior antes do arremesso. Mas, por meio da probabilidade, podemos minimizar essa incerteza e dizer que há aproximadamete 17% de chance de um número escolhido ocorrer.
Em nosso cotidiano, a probabilidade auxilia na decisão de um fabricante de cola de empreender uma grande publicidade no seu produto visando aumentar sua participação no mercado, ou na decisão de parar de imunizar pessoas com menos de vinte anos contra determinada doença, ou ainda na decisão de arriscar-se a atravessar uma rua no meio do quarteirão. Esses pequenos exemplos mostram a relação que a probabilidade tem com a inferência estatística, pois ela nos auxiliará a tomar decisões em procedimento inferencias tentando traduzir para a nossa linguagem do dia-a-dia.
Ao final dessas definições gerais, podemos mostrar uma ilustração, Figura 1.2, que facilitará a compreensão do que abordamos nessa seção. Por fim, um último assunto estudado nesse livro, Capítulo 11, será o estudo da correlação e regressão linear, quando estamos interessado em estudar a forma e o grau relação entre duas ou mais variáveis.
Todos esses assuntos estudaremos nos capítulos seguintes com um certo detalhamento, dando ênfase a exemplos práticos estudados em nosso campo de trabalho. Alguns Capítulos poderão conter uma seção chamada Aprofundamento, com o intuito de apresentar uma maior profundidade sobre o tema estudado. Alguns apêndices serão criados nesse livro para dar suporte ao conteúdo.
O trabalho estatístico é parte integrante do método científico. Segundo Silva (2007), definimos,
Definição 1.5: Método científico
Um conjunto de regras e procedimentos para a obtenção de resultados, isto é, uma conclusão, sobre um determinado problema de uma pesquisa científica, é denominado de Método científico.
A pesquisa científica por sua vez, desenvolve conhecimentos para um saber mínimo de um determinado fenômeno estudado. A pesquisa científica se inicia a partir de um problema dentro da população em estudo. Por meio desse problema surgem diversas indagações.
Exemplo 1.1
No Estado de Minas Gerais houveram dois acidentes, de grandes proporções nos últimos anos, envolvendo barragens que armazenam rejeitos de mineração. Os acidentes ocorreram na cidade de Mariana e Brumadinho, vitimando centenas de pessoas e um impacto ambiental imenso com o arrombamentos dessas barragens. Indagamos:
Quem são os responsáveis por essas duas tragédias?
Quanto será o custo o impacto dessas tragédias?
Quando começou esse problema trágico?
Que medidas poderiam ter sido tomadas para que isso não acontecesse?
Onde estão os órgãos de fiscalização para coibir esses acontecimentos, uma vez que no intervalo de três anos ocorreram duas catástrofes dessas?
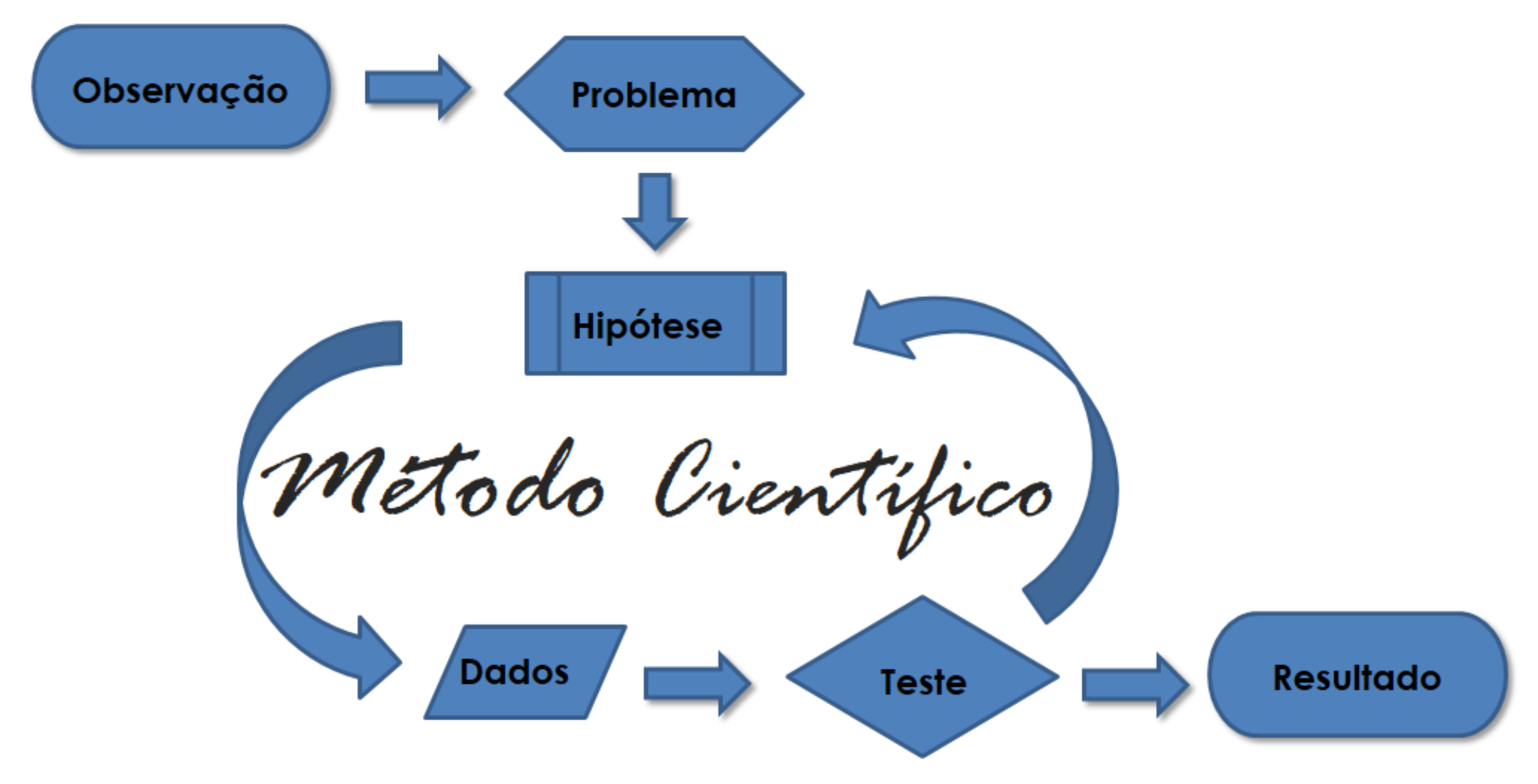
Com essas indagações lançadas para o estudo do problema, e definido a questão inicial dentre as citadas ou outras que possam surgir, o método científico se encarregará de estruturar a pesquisa de modo preciso e sistemático. A resposta a essas indagações resultam em um plano de pesquisa que consiste em:
Identificar o problema e o objetivo da pesquisa
A identificação do problema é o norte da pesquisa. Por meio das perguntas iniciais, procuraremos entender as possíveis causas e efeitos da situação, formulando assim o problema. Nessa fase, devemos identificar a população e os elementos que a compõe, como também os demais procedimentos da pesquisa, inclusive o objetivo do trabalho, no qual se estipula a finalidade do presente estudo. Esse passo é o combustível que impulsiona a pesquisa científica.
Formular a hipótese estudada
A hipótese é uma afirmação atribuída pelo pesquisador sobre a população, com o intuito de responder a(s) indagação(ões) do problema, atingindo o objetivo da pesquisa. Essa afirmação pode ser sugerida pela literatura ou até mesmo construída pelo próprio pesquisador. De toda forma, a elaboração dessa hipótese deve ser bem formulada para que sua não rejeição ou rejeição consiga responder a indagação inicial e o objetivo seja atingido, ou desencadeie novas dúvidas e outras pesquisas possam surgir.
Exemplo 1.2
Tentando inspecionar, como controle de qualidade, uma remessa de peças enviadas por um fornecedor de uma determinada fábrica de peças para indústria de automóveis, garante que essa remessa não há mais de 8% de peças com defeito. Dessa forma o problema foi lançado com a seguinte indagação: será que essa remessa não há mais de 8% de peças com defeito? Lancemos a hipótese a ser testada2: \[\begin{align*}
\left\{\begin{array}{cl}
H_0: & \textrm{A porcentagem de peças com defeito é igual}\\
& \textrm{ou superior a 8\%.}\\
\end{array}\right.
\end{align*}\]
Perguntamos aos leitores: essa indagação elucida a indagação do problema? A avaliação dessa hipótese será realizada na análise e interpretação de dados do qual aplicaremos técnicas específicas para refutar ou não a hipótese estudada \(H_0\). Supondo que não tenhamos evidências estatísticas para a rejeição dessa hipótese, e decidimos não rejeitá-la, a dúvida que fica é: será que a hipótese estudada foi não rejeitada porque a quantidade de peças é igual ou superior a 8%? Observe, se foi 8% a afirmação inicial do fornecedor das peças está correta. Entretanto, se o número de peças foi superior a 8%, o que o fornecedor afirmou está equivocado. Concluímos, que a hipótese não foi bem elaborada para responder a indagação inicial no problema levantado. A forma correta deveria ser:
\[\begin{align*}
\left\{\begin{array}{cl}
H_0: & \textrm{A porcentagem de peças com defeito é menor }\\
& \textrm{ou igual a 8\%.}\\
\end{array}\right.
\end{align*}\]
A importância do desenvolvimento das hipóteses é muito importante, uma vez que podemos tomar decisões totalmente equivocadas, e assim, todo o trabalho estudado ser desperdiçado em vão.
Revisão de literatura
Um passo importante na pesquisa é a confirmação ou o não das respostas encontradas no estudo. É por meio dos trabalhos já publicados que embasamos nossas argumentações, corroborando-as ou refutando-as. Com isso, surge o progresso da ciência, não havendo uma verdade absoluta.
Formular um Plano amostral e Identificar as variáveis de interesse para a pesquisa (Capítulo 7).
Coleta, crítica e tratamento dos dados
Após definirmos cuidadosamente o problema que se quer pesquisar, elabora-se um delineamento e damos início á coleta dos dados necessários à sua descrição. Obtidos os dados, eles devem ser cuidadosamente criticados, à procura de possíveis falhas e imperfeições, a fim de não incorrermos em erros grosseiros, que possam influir sensivelmente os resultados. Por fim, tratamos os dados, que consiste no processamento das informações e a disposição mediante critérios de classificação, podendo ser manual ou eletrônico.
Apresentação dos dados
Por mais diversa que seja a finalidade, os dados devem ser apresentados sob forma adequada (tabelas e gráficos) tornando mais fácil e simples a sua descrição.
Análise e interpretação dos resultados
Após a apresentação dos dados devemos calcular as medidas típicas convenientes para fazermos uma análise dos resultados obtidos, através de métodos estatísticos (Estatística inferencial ou indutiva), e tirarmos desses resultados conclusões e previsões.
Conclusão e derivação da conclusão que poderá rejeitar ou não a hipótese estudada, gerando assim, uma confirmação ou indagações para outros problemas
É de responsabilidade de um especialista no assunto que está sendo pesquisado, que não é necessariamente um estatístico, relatar as conclusões de maneira que sejam facilmente entendidas por quem as for usar na tomada de decisões.
Apresentação dos resultados por meio de trabalhos científicos para a propagação do conhecimento sobre o problema estudado.
Esses pontos do plano de pesquisa podem sofrer alterações em algumas metodologias científicas. Contudo, elas estão envolvidas direta ou indiretamente nas metodologias estudadas, sendo que não necessariamente elas ocorrem em todas as pesquisas nessa ordem, e que podem ser ilustrados na Figura 1.3.
Figura 1.3: Fases do plano da pesquisa científica.
1.4 Definições básicas
Ao ser discutido na seção anterior sobre as definições gerais da Estatística, iniciaremos agora ao que chamamos de definições básicas, que consiste em definir formalmente alguns termos tais como população e amostra, como também os termos variável, dado ou valor observado. Essas definições serão importantes para o desenvolvimento do conteúdo do livro.
O conjunto de todos os elementos dos quais temos o interesse de suas informações, chamamos esse conjunto de população. A palavra população, em nosso cotidiano, está sempre relacionado a um conjunto de pessoas que habitam um determinado local (país, cidade, etc.). Contudo, na estatística ampliamos a definição de população da seguinte forma,
Definição 1.6: População
O conjunto finito ou infinito de todos os elementos com pelo menos uma característica comum, dos quais é de interesse para a pesquisa, denominamos de População. O número de elementos é denominado tamanho da população, denotado por \(N\).
Percebemos pela Definição 1.6 que a idéia sobre população é mais geral. Podemos dizer que o conjunto de peças com defeitos fabricados por uma determinada empresa constitui uma população. Um outro exemplo é a concentração de metais pesados no Rio, sendo que o rio constitui a população. No primeiro caso, a população constitui a empresa que fabrica essas peças com defeitos, que por sua vez, essas peças representam os elementos dos quais a característica em comum a todas as peças é que foi fabricada por essa empresa e apresenta defeito. No segundo caso, a especificação dos elementos poderá não ser muito claro, pois é um caso de população infinita. Daremos mais detalhes sobre isso no Capítulo 7.
Essa(s) característica(s) comum(s) deve(m) delimitar inequivocamente quais elementos que pertencem ou não à população. A notação usual para o número de elementos da população é “\(N\)”. A população pode ser Finita (quando pode ser enumerada) ou Infinita (quando não pode ser enumerada).
Definição 1.7: Amostra
Um subconjunto de elementos da população é denominado amostra. O número de elementos da amostra é chamado de tamanho da amostra, sendo denotado por “\(n\)”.
A amostra é necessariamente finita, pois todos os seus elementos serão examinados para efeito da realização do estudo estatístico desejado. Esse estudo está baseado em características de interesse da população para tentar responder as indagações iniciais do problema da pesquisa (Ver seção1.3). Definimos essa característica como variável.
Definição 1.8: Variável
A característica pela qual desejamos que a população seja descrita é denominada de variável.
A variável representa o mecanismo pelo qual podemos atingir o objetivo da pesquisa. Será por meio dos dados observados, isto é, do valor observado dessa variável assumido por cada elemento da população (ou da amostra), que faremos as análises específicas para se chegar a uma conclusão. Muitas vezes não trabalhamos apenas com uma única variável, dependendo da complexidade da pesquisa, poderemos estudar diversas variáveis ao mesmo tempo.
A variável pode assumir diferentes valores de elemento para elemento, chamado de dado ou valor observado, como foi apresentado na Definição 1.2. A notação usual para a variável é \(X\), \(Y\), \(Z\), ou \(X_i\), \(Y_i\), \(Z_i\) para um particular elemento amostral, em que \(i\)\(=\)\(1\), \(2\), \(\ldots\), \(n\). Definimos a natureza das variáveis, a seguir.
Definição 1.9: Natureza de uma variável
Definimos o tipo de variável pela sua natureza, isto é, pelo valor assumido em cada elemento da população ou amostra como:
Variável qualitativa: é a variável cujo valor observado assume um valor com natureza de atributo ou categoria. Esta ainda se subdivide:
Nominal: Quando os valores não são possíveis de ordenação;
Ordinal: Quando os valores são possíveis de ordenação, segundo um critério quantitativo.
Variável quantitativa: é a variável cujo valor observado assume um valor com natureza numérica (enumerável ou não). Ainda podem ser divididas:
Discreta: Quando os valores são dados de contagem, isto é, descrevem uma quantidade contável, cujos potenciais valores dessa variável podem ser enumerados em um conjunto de valores;
Contínua: Quando os valores resultam de uma medida (ou mensuração), podendo assumir qualquer valor real entre dois extremos, e dessa forma não podemos enumerar seus valores.
Vejamos o Exemplo 1.3, para elucidar todas essas definições mencionadas anteriormente.
Exemplo 1.3: Desmatamento da Amazônia Legal
O Brasil vem passando por um processo de desmatamento na Amazônia legal, que o mundo vem acompanhando nesses últimos anos. O Instituto Nacional de Pesquisas Espaciais (INPE) desenvolveu o PRODES3 (Programa de Monitoramento do Desmatamento da Amazônia) que vem acompanhando desde 1988, as taxas de desmatamento na região. Apresentamos a seguir, a Tabela 1.2, que apresenta algumas informações sobre esse tema em cada estado do qual compreende a Amazônia Legal, em que os dados da taxa acumulada de desmatamento por estado, estão disponíveis na página do INPE, em Amazônia Legal. Podemos verificar que apresentamos diversas variáveis para um melhor detalhamento da taxa de desmatamento na Amazônia legal, em relação a algumas informações sobre os estados que compõe essa região. Observemos que, quanto a natureza das variáveis, Região, UF, e Classificação, são variáveis qualitativas, pois os valores observados representam uma categoria. Apesar de representar uma qualidade, percebamos que classificação apresenta um ordenamento, referente a quantidade de desmatamento acumulado de cada estado, em que, o estado do Pará está em primeiro lugar, por ter sido o estado que mais desmatou, desde 1988. No caso, as variáveis Região e UF representam apenas categorias que não apresentam qualquer forma de ordenamento. Muito embora, os valores de Classificação estejam representados por números, a natureza é qualitativa. Portanto, Região e UF são variáveis qualitativas nominais, e Classificação, variável qualitativa ordinal.
As demais variáveis são Número de cidades, Desmatamento acumulado, Área total e População estimada. Conseguimos observar que Número de cidades e População estimada apresentam dados de contagem, logo, essas variáveis são quantitativas discretas. Isso significa, que entre dois valores consecutivos, há uma discretização, ou seja, o estado do Amapá está dentro da região da Amazônia legal, e tem 14 município. Já o estado de Roraima apresenta 15 municípios dentro da Amazônia Legal. Dessa forma, não há um potencial valor para a variável Número de Cidades, entre esses dois valores, isto é, 14,5. De outro modo, podemos ordenar em um conjunto enumerável todos os valores de uma variável quantitativa discreta.
Agora, para o caso das variáveis Desmatamento e Área total, percebemos que os valores assumidos por essas variáveis não são dados de contagem, mas de medição, isto significa que não contamos área ou taxa de Desmatamento acumulado, mas sim, medimos. De outro modo, teoricamente nós não conseguimos identificar os potenciais valores de uma variável quantitativa contínua em certo certo conjunto enumerável, porque observe o valor da área total do estado do Pará, \(1.245.870,00~km^2\), se tivéssemos instrumentos de medidas mais precisos, esse valor não seria exatamente esse, poderia ter sido \(1.245.870,001~km^2\), \(1.245.870,0001~km^2\), \(1.245.870,00001~k
m^2\), e assim por diante. Dessa forma, em uma determinada ordem nós não conseguiríamos saber qual o próximo valor ordenado para a área, após observarmos a área do estado do Pará.
Tabela 1.2: Taxa de desmatamento acumulado, por estado, na Amazônia Legal, compreendido desde 1988 a 07/12/2020.
Uma variável originalmente quantitativa pode ser coletada de forma qualitativa. Por exemplo, a variável idade, medida em anos completos, é quantitativa (discreta). Porém, se considerarmos uma nova variável como faixa etária, do qual os valores possíveis são: “criança” (0 a 12 anos), “adolescente” (12 a 17 anos), “adulto” (18 a 60 anos) e “idoso” (acima de 60 anos), cujos valores foram originais da variável idade estão entre parênteses, a variável faixa etária passa é considerada uma variável qualitativa (ordinal). Outro exemplo é o peso dos lutadores de boxe, uma variável quantitativa (contínua) se trabalhamos com o valor obtido na balança, mas qualitativa (ordinal) se o classificarmos nas categorias do boxe (peso-pena, peso-leve, peso-pesado, etc.);
Outro ponto importante é que nem sempre uma variável representada por números é quantitativa. O número do telefone de uma pessoa, o número da casa, o número de sua identidade. Às vezes o sexo do indivíduo é registrado na planilha de dados como 1 se macho e 2 se fêmea, por exemplo. Isto não significa que a variável sexo passou a ser quantitativa!
É fato que a rigor, as variáveis quantitativas seriam todas discretizadas devido a limitação dos nossos instrumentos de medidas. Observe que o tamanho de uma pessoa não está limitado às escalas de metros, centímetros, milímetros, etc.. Porém, os instrumentos de medida que obtém essa informação, estão limitados a essas escalas. De toda forma, precisamos dessa limitação para que as análises sejam possíveis, e possamos tomar decisões a partir dos dados.
1.5 Técnicas de Somatório
Um tipo de notação muito importante para a Estatística é o uso de técnicas de somatório, muito usado, por exemplo, na notação de medidas estatísticas. A ideia da técnica de somatório é simplificar a notação da soma de dados, de modo que possamos representar essas operações por meio de notação matemática de modo simplificado.
Como já falado anteriormente, representamos por \(X\) uma determinada variável. Nesse caso, não fará sentido falar de variáveis qualitativas, uma vez que o objetivo nessa notação é a representação de operações matemáticas. Assim, estaremos restritos as variáveis quantitativas.
Baseado nos dados da Tabela 1.2, supomos que \(X\) representa o número de cidades pertencentes a Amazônia legal de um terminado estado, então nesse caso, como temos a representação de todos os estados, estamos diante de dados populacionais. Assim, \(N = 9\), podemos representar a variável com um índice para se referir ao número de cidade de um determinado estado. Por exemplo, \(X_1\) representa a variável número de cidades do Pará, o seu valor observado \(x_1 = 144\) cidades. A variável \(X\) pode ser representada nos demais elementos da seguinte forma: \(X_1\), \(X_2\), \(\ldots\), \(X_9\). Podemos nos interessar em saber o total de cidades na Amazônia legal. Em notação, podemos calcular esse total da seguinte forma: \[\begin{align*}
x_1 + x_2 + x_3 + \ldots + x_9 & = 144 + 141 + 52 + 62 + 181 + \\
& \quad 22 + 139 + 15 + 14\\
& = 770~\textrm{cidades.}
\end{align*}\]
Percebemos que com apenas nove observações, a notação para essa simples operação se torna extensa. E isso acaba aumentando à medida que o número de observações aumentam. Também, quando realizamos operações mais complexas, essa representação também se tornam mais complexas. Pensando nisso, surgem as técnicas de somatórios, para simplificar essas representações. Representaremos um somatório pela letra grega sigma maiúsculo (\(\Sigma\)), que indica a soma de determinados valores. Agregado ao símbolo do somatório, usaremos uma (ou algumas) indexação(ões) para representar qual(is) os elementos fazem parte desta operação, seguido da(s) variável(is) de interesse, isto é, \[\begin{align*}
\sum_{i = 1}^{m} X_i & = X_1 + X_2 + \ldots + X_m,
\end{align*}\] sendo que \(m\) pode representar o tamanho amostral, \(n\), ou o tamanho populacional, \(N\). No caso da representação anterior, podemos simplicar a representação da soma de um conjunto de valores usando as técnicas de somatório, apresentadas a seguir, \[\begin{align*}
X_1 + X_2 + X_3 + X_4 + X_5 + X_6 + X_7 + X_8 + X_9 & = \sum_{i = 1}^{9} X_i.
\end{align*}\] Tornamos a notação mais simples de ser representada. Isso será muito importante, quando formos definir medidas estatísticas, provas de teoremas, etc.
De modo similar, podemos realizar as mesmas alterações com transformações na(s) variável(is). Por exemplo, quando formos estudar medidas de dispersão, no Capítulo 4, será útil as seguintes operações, considerando uma amostra de tamanho \(n\), \[\begin{align*}
\sum_{i = 1}^{n} X_i^2 = X_1^2 + X_2^2 + \ldots, X_n^2,
\end{align*}\] isto é, a soma do quadrado da variável. Outra operação interessante, é o quadrado da soma, apresentado a seguir, \[
\left(\sum_{i = 1}^{n} X_i\right)^2 = \left(X_1 + X_2 + \ldots, X_n\right)^2.
\tag{1.1}\] Uma técnica muito utilizada na Estatística é o estudo da Regressão linear, que estuda a relação entre duas ou mais variáveis, e será abordado no Capítulo 11. Assim, uma das operações utilizadas é a soma do produto entre duas variáveis, por exemplo, \(X\) e \(Y\), do qual podemos representar esta soma para um conjunto de pares \((X_i, Y_i)\), de tamanho \(n\), da seguinte forma, \[
\sum_{i = 1}^{n} X_iY_i = X_1Y_1 + X_2Y_2 + \ldots, X_nY_n.
\tag{1.2}\] Outra forma é o produto das somas de variáveis, que nesse caso, nos limitaremos as duas variáveis \(X\) e \(Y\). Por exemplo, para um amostra de pares \((X_i, Y_i)\) de tamanho \(n\), pode ser representada por: \[
\begin{align}
\left(\sum_{i = 1}^{n} X_i\right)\times \left(\sum_{i = 1}^{n} Y_i \right) & = \left(X_1 + X_2 + \ldots, X_n\right)\times \nonumber\\
& \times \left( Y_1 + Y_2 + \ldots, Y_n \right) \nonumber\\
& = \sum_{i = 1}^{n} X_iY_i + \mathop{\sum_{i = 1}^{n}\sum_{j = 1}^{n}}_{i\neq j}X_iY_j,
\end{align}
\tag{1.3}\] em que o primeiro dessa último resultado é dado pela notação expressa em (1.2). O segundo termo, apresenta uma nova notação que é o duplo somatório. A ideia dessa notação é simples, fixaremos o índice no primeiro somatório e percorremos a soma dos valores usando o segundo índice. Após ter realizado toda a operação, passaremos para o próximo índice no primeiro somatório e realizamos o mesmo procedimento para o índice no segundo somatório. Toda a operação será finalizada, quando tivermos percorrido a soma em todos os valores. Vejamos para um caso de duplo somatório, com um par de variáveis \((X_i, Y_i)\), para \(n = 3\), \[\begin{align*}
\sum_{i = 1}^{3}\sum_{j = 1}^{3}X_iY_j & = \sum_{j = 1}^{3}X_1Y_j + \sum_{j = 1}^{3}X_2Y_j + \sum_{j = 1}^{3}X_3Y_j\\
& = (X_1Y_1 + X_1Y_2 + X_1Y_3) + (X_2Y_1 + X_2Y_2 + X_2Y_3) + \\
& \quad + (X_3Y_1 + X_3Y_2 + X_3Y_3).
\end{align*}\] Para uma amostra de tamanho \(n\), podemos generalizar essa notação da seguinte forma, \[
\begin{align}
\sum_{i = 1}^{n}\sum_{j = 1}^{n}X_iY_j & = \sum_{j = 1}^{n}X_1Y_j + \sum_{j = 1}^{n}X_2Y_j + \ldots + \sum_{j = 1}^{n}X_nY_j \nonumber\\
& = (X_1Y_1 + X_1Y_2 + \ldots + X_1Y_n) +\\
&\quad + (X_2Y_1 + X_2Y_2+ \ldots + X_2Y_n) + \nonumber\\
&\quad \ldots + (X_nY_1 + X_nY_2 + \ldots + X_nY_n).
\end{align}
\tag{1.4}\]
Porém, observe que o resultado em (1.4), soma todos os produtos \(X\) e \(Y\). Como desejamos fazer uma relação entre a expressão (1.3) e a expressão (1.2), separamos a soma de produtos \(X\) e \(Y\) com índices iguais das demais situações. Para isso, impomos a restrição no segundo termo, depois da igualdade na expressão (1.4), para enfatizar que somaremos o produto de todos os \(X_i \times Y_i\), tais que \(i \neq j\), resultando na expressão (1.3).
Podemos também representar a notação \(\sum_{i = 1}^{n}\sum_{j = 1}^{n}X_iY_j\) da seguinte forma, \[\begin{align}
\sum_{i = 1}^{n}\sum_{j = 1}^{n}X_iY_j & = \mathop{\sum_{i = 1}^{n}}_{j = 1}X_iY_j.
\end{align}\]
Uma outra notação que pode ser apresentada para o duplo somatório é abrindo o quadrado da soma no resultado da expressão (1.1), dada da seguinte forma, \[
\begin{align}
\left(X_1 + X_2 + \ldots, X_n\right)^2 & = (X_1 + X_2 + \ldots + X_n) \times\\
& \quad \times (X_1 + X_2 + \ldots + X_n) \nonumber\\
& = X_1X_1 + X_1X_2 + \ldots + X_1X_n + \nonumber\\
& \quad + X_2X_1 + X_2X_2 + \ldots + X_2X_n + \ldots \nonumber\\
& \quad \ldots + X_nX_1 + X_nX_2 + \ldots + X_nX_n \nonumber\\
& = \sum_{i = 1}^{n} X_i^2 + 2\sum_{j > i = 1}^{n}X_iX_j.
\end{align}
\tag{1.5}\]
Nesse caso, impomos também uma outra restrição no somatório do segundo termo após a igualdade, que foi somar todos os produtos \(X_i\times X_j\)s, exceto aqueles com ele mesmo. Assim, observamos que situações do tipo \(X_1 \times X_2 = X_2 \times X_1\), e desse modo, podemos representar \(X_1 \times X_2 + X_2 \times X_1 = 2X_1X_2\) que o resultado será o mesmo, e simplifica a notação. Generalizando a soma para os demais casos, temos \(2\sum_{j > i = 1}^{n}X_iX_j\), como verificado na expressão (1.5).
Por fim, queremos enfatizar uma última situação que é usar um indexador não como a identificação da variável para um determinado elemento da população ou amostra, mas como valor observado. Essas situações serão muito utilizadas em notações no Capítulo 5 e Capítulo 6, do qual somaremos as probabilidades da variável assumir valores em um determinado conjunto. A ideia de variável nesses capítulos será entendida como uma função, mas isso é assunto mais para frente. Nesse caso, vamos entender que \(P(.)\) é uma função que mede a chance de determinado \(X\) assumir um determinado valor, isto é, \(P(.)\) assume um valor entre \(0\) e \(1\). Essa função será chamada mais a frente de probabilidade. Assuma também que os valores possíveis de \(X\) assumam valores em um conjunto \(A = \{1, 2, 3, 4, 5\}\), e estamos interessados em representar a chance de \(X\) assumir valor \(3\). Nesse caso, usamos \(P(X = 3)\). Agora desejarmos representar a chance de \(X\) assumir valores, no mínimo, igual a 3. Dessa forma, representamos essa chance da seguinte forma, \[
\begin{align}
P(X \geq 3) & = \sum_{x = 3}^{5}P(X = x) \nonumber\\
& = \quad P(X = 3) + P(X = 4) + P(X = 5).
\end{align}
\tag{1.6}\]
Observamos que o indexador no somatório agora é o valor assumido pela variável, e não a identificação da variável a um deteminado elemento da amostra ou população. Se desejarmos somar todas as chances que \(X\) assume, podemos apresentar duas notações diferentes, apresentadas na sequência, \[
\begin{align}
\sum_{x = 1}^{5}P(X = x) & = \sum_{x \in A}P(X = x) .
\end{align}
\tag{1.7}\] O índice no somatório indica agora que iremos somar as chances de \(X\) assumir todos os valores pertencentes ao conjunto \(A\). Claro que, muitas outras formas de apresentar as técnicas de somatório podem ocorrer ao longo do texto, uma vez que outras formas podem ser abordadas, dependendo do assunto, como também da área estudada. De todo modo, tentamos passar parte da notação que será utilizada ao longo do livro, para que o leitor possa se ambientar nesse tipo de representação matemática.
Para complementar essas informações, o Teorema 1.12 apresenta algumas propriedades sobre técnicas de somatório que serão importantes para os próximos capítulos.
Teorema 1.1: Propriedades de somatório
Considere \(a\), \(b\) e \(k\) constantes, e que \(X\) e \(Y\) são variáveis quantitativas, então as seguintes propriedades envolvendo somatório são válidas:
Observando as expressões (1.2) e (1.3), claramente que \(\sum\limits_{i = 1}^n X_i Y_i < \sum\limits_{i = 1}^n {X_i } \sum\limits_{i = 1}^n {Y_i }\). A única condição de igualdade acontece se \(n = 1\). Porém, em termos práticos para contexto estatístico, essa informação é inútil, uma vez que com apenas uma observação na amostra ou população não haverá condições apresentarmos alguma informação sobre a mesma.
Verificando a expressão (1.5), percebemos claramente que \(\displaystyle\sum_{i = 1}^n X_i^2 < \left(\displaystyle\sum_{i = 1}^n X_i\right)^2\). A única condição de igualdade acontece se \(n = 1\), e em termos práticos para uso estatístico, usamos a mesma justificativa dada na propriedade (I);
Baseado no Exemplo 1.1, identifique um problema para essa pesquisa bem como um objetivo, e desenvolva hipóteses a serem estudadas, de modo que estas possam responder as indagações do problema e atinja o objetivo proposto.
Solução
Sabemos que no Brasil as barragens de mineração apresentam três tipos: barragem a montante, barragem a jusante e barragem linha de centro, dos quais esses tipos levam o custo e a segurança da barragem, porém todos eles depositam água juntamente com os rejeitos, e isto proporciona uma certa instabilidade para a barragem. Desse modo, podemos ter como problema inicial que a instabilidade das barragens podem estar relacionados aos tipos de barragens desenvolvidas no Brasil. Existe um outro tipo de barragem que pode ser desenvolvido a seco, porém pouco conhecido no Brasil, do qual o material acumulado é drenado e acumulado em pilhas, de modo a ficarem expostos à secagem do sol.
Assim, como estudo inicial sobre essa alternativa de construção de barragem, poderíamos nortear a pesquisa sob duas hipóteses a serem estudadas:
Pesquisa 1: \(H_0:\) Barragens do tipo depósito de rejeito a seco são mais baratas que as existentes no Brasil;
Pesquisa 2: \(H_0:\) Barragens do tipo depósito de rejeito a seco são mais seguras que as existentes no Brasil;
Exercício 1.2
Usando os resultados do Teorema 1.1, mostre em quais aplicações na estatística poderemos utilizar esses resultados.
Exercício 1.3
Baseado em Devore (2006), um famoso experimento executado em 1882, Michelson e Newcomb fizeram 66 observações do tempo levado pela luz para percorrer a distância entre dois locais em Washington, D.C. Algumas das medidas (codificadas de certa forma) foram 31, 23, 32, 36, -2, 26, 27 e 31. Por que essas medidas não são idênticas?
Solução
Essas medidas não são iguais por diversos fatores, dentre elas, a imprecisão dos instrumentos de medida. Isso é o que define chamarmos essa característica de interesse no estudo de variável, pois de elemento a elemento, o valor assumido dessa característica varia. Outros aspectos dessa variação podem ser as diferentes condições ambientais referentes ao tempo de medida, dentre outros.
Exercício 1.4
Sejam as amostras de tamanho n = 5 de duas variáveis, dadas por:
Qual conclusão se pode chegar sobre os itens (n) e (p), bem como (o) e (q)?
Exercício 1.5
Forneça uma amostra possível, de tamanho 5, de cada uma das populações a seguir:
todos os jornais publicados no Brasil;
todas as empresas na área de telecomunicações;
todos os alunos da Universidade Federal de São João del-Rei;
todas as notas, pontuados de 0 a 100, dos alunos da disciplina de Estatística e Probabilidade;
Solução
O Globo (Rio de Janeiro), Folha de São Paulo (São Paulo), Tribuna do Norte (Rio Grande do Norte), A crítica (Manaus), A Gazeta (São Paulo);
NET, TIM, Brisanet, Vivo, Oi;
Samara, Diego, Anna Albuquerque, Matheus, Giliwiline;
85, 75, 65, 42, 57.
Exercício 1.6
Observou-se o tempo, em minutos, que \(10\) atendimentos de clientes de uma determinada empresa telefônica demoraram para serem atendidos, que seguem: \(5\), \(10\), \(2\), \(13\), \(7\), \(15\), \(8\), \(12\), \(6\) e \(5\). O objetivo do estudo foi verificar se o tempo médio, em minutos, do atendimento era superior a 10 minutos. Pergunta-se:
Qual a população em estudo?
Qual o problema indagado?
Qual(is) a(s) variável(is) em estudo do trabalho, como também a natureza dessa(s) variável(is)?
Podemos identificar o tamanho da população e da amostra, com essas informações?
Exercício 1.7
Como podemos relacionar os ramos da Estatística com os itens do plano de pesquisa científica, presentes nesse capítulo?
Solução
Pesquisa científica
Ramos da Estatística
Identificar o problema e o objetivo da pesquisa
-
Formular a hipótese estudada
Estatística Inferencial
Revisão de literatura
-
Formular um plano amostral e identificar as variáveis de interesse para a pesquisa
Amostragem (Não o classificamos com um ramo da estatística)
Coleta, crítica e tratamento dos dados
Estatística descritiva
Apresentação dos dados
Estatística descritiva
Análise e interpretação dos dados
Estatística inferencial e Probabilidade
Conclusão e derivação da conclusão que poderá rejeitar ou não a hipótese estudada, gerando assim, uma confirmação ou indagações para outros problemas
Estatística inferencial e Probabilidade
Apresentação dos dados por meio de trabalhos científicos para a propagação do conhecimento sobre o problema estudado
Estatística descritiva
Exercício 1.8
Os dados retirados de Tavares e Anjos (1999), representam a distribuição percentual do estado nutricional em homens idosos brasileiros (idade \(\geq\) 60 anos), segundo Índice de Massa Corporal (IMC7), por macrorregião e situação de domicílio, Pesquisa Nacional sobre Saúde e Nutrição, 1989, que seguem abaixo. Como poderíamos, em notação usando as técnicas de somatório, representar a soma de todos os valores de IMC do Brasil, levando em consideração as demais variáveis? Se desejássemos, calcular o total dos valores observados de IMC dos homens do nordeste, considerando as demais condições? E se fosse do nordeste e da zona urbana, como representaríamos esse somatório?
Regiões
Número
Estado Nutricional (%)
M
A
SI
SII e SIII
Norte
223
4,4
60,6
29,4
5,6
Nordeste
586
8,8
68,3
19,8
3,1
Urbano
267
7,1
62,3
26,6
4,0
Rural
319
10,7
74,6
12,5
2,2
Sudeste
463
7,9
59,0
26,7
6,4
Urbano
197
5,6
56,4
30,2
7,8
Rural
266
17,3
69,5
12,4
0,8
Sul
429
5,1
56,5
29,2
9,2
Urbano
197
4,5
51,2
33,0
11,3
Rural
232
6,4
66,4
22,0
5,2
Centro-Oeste
327
10,7
60,6
22,8
5,9
Urbano
154
10,6
55,2
27,3
6,9
Rural
173
11,0
71,4
13,7
3,9
Brasil
2.028
7,8
61,8
24,7
5,7
Urbano
1.038
6,0
57,2
29,5
7,3
Rural
990
11,7
71,7
14,2
2,4
Solução
Devemos observar nessa tabela, a presença de algumas variáveis como: Região (Norte, Nordeste, Sudeste, Sul, Centro-Oeste e Brasil), Zona (Urbano e Rural), Estado Nutricional (Magreza, Adequado, Sobrepeso I e Sobrepeso II e III) e Número.
Vale lembrar que os valores internos da tabela representam a distribuição percentual de pessoas que se enquadram em um determinado estado nutricional, separados por região. Assim, considerando que temos todos os valores de IMC das pessoas entrevistadas (2.028 pessoas), e que esta é representada pela variável \(X\), (a) a soma de todos os IMCs do Brasil, levando em consideração a todas as outras variáveis, pode ser representada por: \[\begin{align*}
\sum_{i = 1}^{2.028}X_i.
\end{align*}\]
Agora o total do IMC de homens do nordeste (586 pessoas), e que estes são representados pela variável \(Y\), então \[
\begin{align}
\sum_{j = 1}^{586}Y_j
\end{align}
\tag{1.8}\]
Por fim, considerando o total do IMC de homens da zona urbana, podemos aproveitar a notação anterior, e complementar com um outro indexador, \(k = 1, 2\); se \(k = 1\) teremos uma pessoa da zona urbana, e se \(k = 2\), teremos uma pessoa da zona rural, então como representação de soma geral teríamos \[
\begin{align}
\sum_{j = 1}^{586}Y_{jk}, \quad k = 1, 2.
\end{align}
\tag{1.9}\] As expressões (1.8) e (1.9) são equivalentes. Restringindo a soma apenas para homens da zona urbana, temos \[\begin{align*}
\sum_{j = 1}^{586}Y_{j1}.
\end{align*}\] Este último resultado significa que alguns valores de \(Y_{j1}\) serão iguais a 0, pois sabemos pela tabela que há apenas 267 homens da zona urbana.
Exercício 1.9
Considere a expressão \(\displaystyle \sum_{i = 1}^{n}(X_i - A)^2\). Qual o valor de \(A\) para que essa expressão seja minizada?
Exercício 1.10
Os famosos estudos sobre o tempo de oscilação de um pêndulo, do qual se afirmava que este tempo não dependia do peso do corpo suspenso na extremidade do fio, motivou Galileu a realizar diversos experimentos, que levou a fazer determinadas afirmações, como por exemplo: se dois objetos com pesos diferentes caíssem da mesma altura ao mesmo tempo no vácuo chegariam ao chão ao mesmo tempo. Esses estudos foram muito importantes para a criação das leis da queda dos corpos, para enunciar a base do princípio da inércia e a lei da composição das velocidades. Baseado na afirmação de Galileu anteriormente, como poderíamos relacionar o método científico e as suas fases diante dessa situação?
COMPANY, B. P. BP statistical review of world energy. London: British Petroleum Company, 2018.
DEVORE, J. L. Probabilidade e Estatística para Engenharia e Ciências. 6. ed. São Paulo: Cengage Learning, 2006. p. 692
SILVA, J. G. C. DA. Planejamento da Pesquisa Experimental: Base Conceitual e Metodológica. Pelotas: Instituto de Física e Matemática, 2007. p. 509
TAVARES, E. L.; ANJOS, L. A. DO. Perfil antropométrico da população idosa brasileira. Resultados da Pesquisa Nacional sobre saúde e Nutrição. Cad. Saúde Pública, v. 15, n. 4, p. 759–768, 1999.